These days I work primarily in TypeScript on Node.js. I needed to handle bulk uploads of large Excel data and dynamically generate template Excel files to collect that data. Those templates had to include data validation, conditional formatting, dropdowns, and so on.
The existing Node.js Excel libraries each had problems. One split its functionality between a community edition and a paid edition, which meant features I needed were locked away. The other had a gap between its internal implementation and its TypeScript typings, and it was too slow for what I was trying to do. Pull requests had piled up in the repository, but the project was no longer being maintained.
I had known about Excelize, the Go library, for a while. Charts, conditional formatting, formulas, data validation: it covers a lot of the OOXML spec and does it well. I kept thinking I wanted something at that level in TypeScript.
Coding agents have gotten noticeably better in the past year or so, and I wanted to try a specific way of working: I make all the design and architecture decisions, and agents handle the implementation. On Wednesday of last week (February 4th) I started analyzing Excelize and other Excel libraries. By Saturday night (February 7th) I was writing code.
That's SheetKit.
This is the first of two posts. This one covers what SheetKit is and how the week went, from first release to the v0.5.0 I shipped this evening (February 14th). The second post will be about working with coding agents: what I delegated, how, and where it broke down.
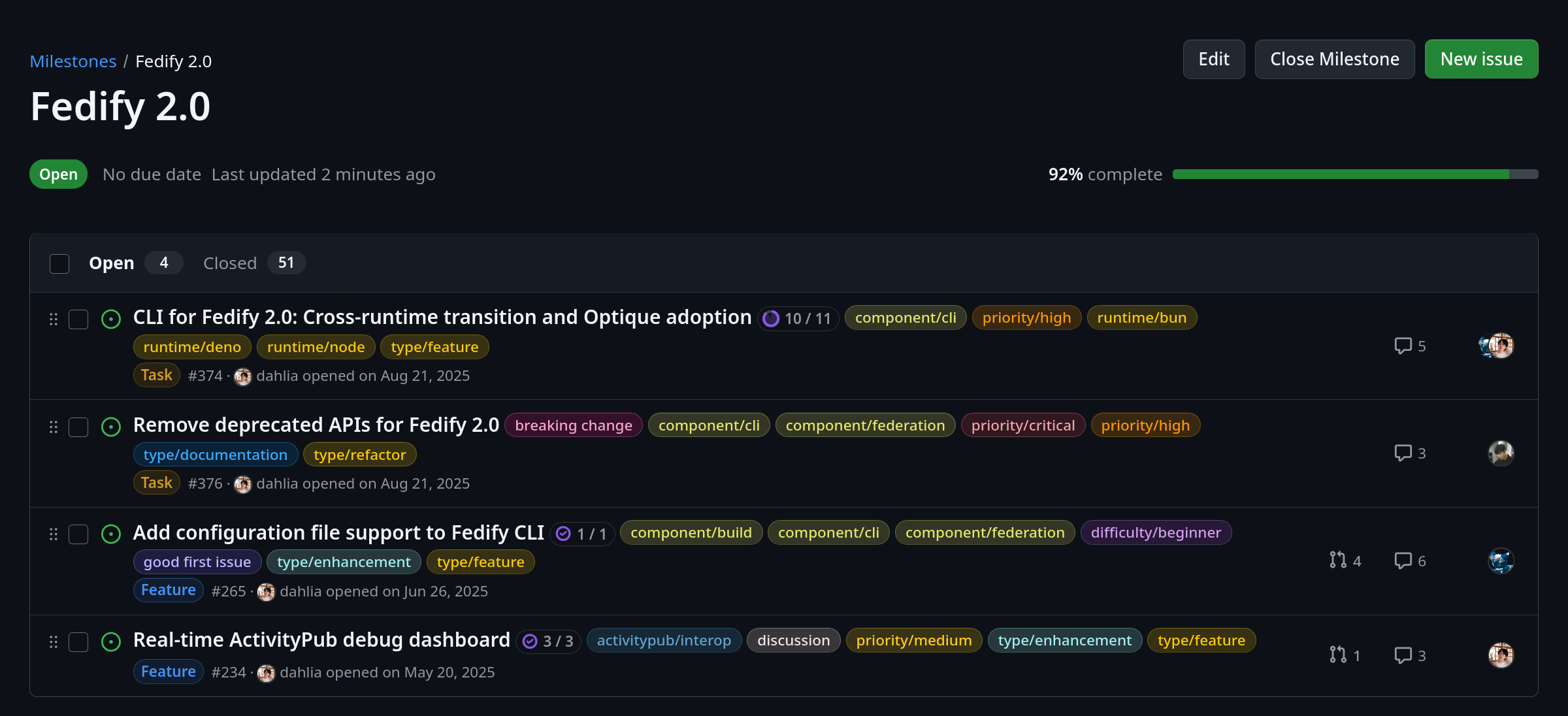
Release Timeline
Dates are crates.io / npm publish timestamps. Approximate, not to-the-minute.
| Version |
When |
Date |
What |
| v0.1.0 |
Sunday (last week) |
2026-02-08 |
First publish (initial form) |
| v0.1.2 |
Monday early morning (last week) |
2026-02-09 |
First snapshot worth calling a public release |
| v0.2.0 |
Monday morning (last week) |
2026-02-09 |
Buffer I/O, formula helpers |
| v0.3.0 |
Tuesday early morning (last week) |
2026-02-10 |
Raw buffer FFI, batch APIs, benchmark suite |
| v0.4.0 |
Tuesday afternoon (last week) |
2026-02-10 |
Feature expansion + documentation site |
| v0.5.0 |
Saturday evening (today) |
2026-02-14 |
Lazy loading / streaming, COW save, benchmark rule improvements |
What Is SheetKit?
SheetKit is a Rust spreadsheet library for OOXML formats (.xlsx, .xlsm, etc.) with Node.js bindings via napi-rs. Bun and Deno work too, since they support Node-API.
.xlsx files are ZIP archives containing XML parts. SheetKit opens the ZIP, deserializes each XML part into Rust structs, lets you manipulate them, and serializes everything back on save.
Three crates on the Rust side:
sheetkit-xml: Low-level XML data structures mapping to OOXML schemassheetkit-core: All business logicsheetkit: Facade crate for library consumers
Node.js bindings live in packages/sheetkit and expose the Rust API via #[napi] macros.
To get started: sheetkit.dev/getting-started.
Saturday Night to First Release (v0.1.x)
I started coding Saturday night (February 7th) and pushed v0.1.0 the next day. By early Monday morning I had v0.1.2, which was the first version I'd actually call releasable.
I had spent Wednesday analyzing the OOXML spec and how existing libraries implemented features, so by Saturday I had a detailed plan ready. I handed implementation to coding agents (Claude Code and Codex). The setup was: a main orchestrator agent receives the plan, then spawns sub-agents in parallel for each feature area. It burns through tokens fast, but it gets a large plan done quickly. After the agents finish, a separate agent does code review before I look at it.
More on this workflow in the next post.
v0.1.2 was an MVP. It had 44,000+ lines, 1,533 tests, 110 formula functions, charts, images, conditional formatting, data validation, StreamWriter, and builds for 8 platform targets. But it could only read/write via file paths (no Buffer I/O), and I hadn't measured performance at all. It worked, but that was about it.
Buffer I/O (v0.2.0)
v0.2.0 went up Monday morning, a few hours after v0.1.2.
I added Buffer I/O: read and write .xlsx directly from in-memory buffers, no filesystem needed. In a server you're usually processing binary from an HTTP request or streaming a generated file back in the response, so this had to come early. fill_formula and other formula helpers went in at the same time.
With Buffer I/O in place I could run tests closer to real production workloads. That's where the problems showed up.
Switching to Raw Buffers (v0.3.0)
The initial implementation created a JS object per cell and passed it across the Rust/JS FFI boundary. Pull a 50k×20 sheet as a row array and that's a million-plus JS objects. GC pressure and memory usage went through the roof.
I got the idea from oxc, which transfers Rust AST data to JS as raw buffers instead of object trees. Same principle here:
- Don't create per-cell objects.
- Serialize the entire sheet into a compact binary buffer.
- Cross the FFI boundary once.
The encoder picks dense or sparse layout automatically based on cell occupancy (threshold: 30%). Since the JS side receives a raw buffer, I also wrote a TypeScript parser for the format.
v0.3.0 shipped the first version of this buffer protocol. v0.5.0 later replaced it with a v2 format that supports inline strings and incremental row-by-row decoding.
I also made changes in the Rust XML layer. The goal was fewer heap allocations and simpler hot paths.
| Change |
Why |
Cell references ("A1") stored as [u8; 10] inline arrays, not heap Strings |
Max cell ref is "XFD1048576" (10 bytes). No need for the heap. |
| Cell type attribute normalized to a 1-byte enum |
Stops carrying raw XML attribute strings around |
| Binary search for cells within a row, replacing linear scan |
|
| Metric |
Before |
After |
| Memory (RSS) at 100k rows |
361 MB |
13.5 MB |
| Node.js read overhead vs. native Rust |
— |
~4% |
| GC pressure |
1M+ object creations |
Single buffer transfer |
Benchmarks
This is when I built the benchmark suite, comparing SheetKit against existing Node.js and Rust libraries. The runner outputs Markdown with environment info, iteration counts, and raw numbers.
Setup: Apple M4 Pro, 24 GB / Node v25.3.0 / Rust 1.93.0. Median of 5 runs after 1 warmup. RSS/heapUsed are residual deltas (before vs. after), not peaks. Fixtures are generated deterministically; row counts include the header.
50k rows × 20 columns: SheetKit read 541 ms, write 469 ms. The JS-only libraries: 1.24–1.56s read, 1.09–2.62s write. heapUsed delta: 0 MB, which confirmed that the JS side was no longer accumulating objects.
One odd thing: edit-xlsx, a Rust library, was showing suspiciously fast read times. I didn't understand why at this point. The explanation came during the v0.5.0 work (covered below).
Tuesday: Closing Feature Gaps (v0.4.0)
v0.4.0 shipped Tuesday afternoon. This one was about features, not performance.
I went through what other Excel libraries supported and listed what SheetKit was still missing. Shapes, slicers, form controls, threaded comments, VBA extraction, a CLI. I also added 54 more formula functions (total: 164), mostly financial and engineering.
Same orchestrator/sub-agent setup as before: write a detailed plan for each feature, have the agents implement in parallel, agent review first, then my review.
Memory optimization continued on the side. Reworking the Cell struct and SST memory layout cut RSS from 349 MB to 195 MB for sync reads (44% drop). Async reads: 17 MB.
I also set up a VitePress documentation site around this time.
Today: Rethinking the Architecture (v0.5.0)
v0.5.0 went out this evening. Unlike the previous releases, which added features on top of the same API shape, this one changed the Node.js API structure and parts of the Rust core.
Lazy Loading by Default
Before v0.5.0, open() parsed every XML part upfront. Open a 50k-row file and all sheets load into memory, even the ones you never touch. Now there are three read modes:
lazy (default): reads ZIP index and metadata only. Sheets parse on first access.eager: the old behavior. Parse everything immediately.stream: forward-only, bounded memory.
Lazy open costs less than 30% of eager, and pre-access memory is under 20% of eager. Auxiliary parts (comments, charts, images, pivot tables) also defer parsing until you actually call a method that needs them.
Streaming Reader
Forward-only reader for large files. One batch in memory at a time.
const wb = await Workbook.open("huge.xlsx", { readMode: "stream" });
const reader = await wb.openSheetReader("Sheet1", { batchSize: 1000 });
for await (const batch of reader) {
for (const row of batch) {
// process
}
}
Copy-on-Write Save
When you save a lazily-opened workbook, unchanged sheets pass through directly from the original ZIP entry. No parse-serialize round trip. At work I generate files by opening a template, filling in a few cells, and sending it back. That's exactly the workload this helps.
The edit-xlsx Read Anomaly
Back when I built the benchmarks, edit-xlsx was recording very fast read times on some files. Rows/cells count was dropping to zero.
I added comparability rules to the benchmark:
- Check that rows/cells count matches expectations
- Value-probe a few cells at known coordinates
- If either fails, mark the result non-comparable
Then I dug into why. In SpreadsheetML, fileVersion, workbookPr, and bookViews in workbook.xml are optional. edit-xlsx 0.4.x treats them as required. When deserialization fails on a file missing these elements, it falls back to a default struct: rows=0, cells=0, near-zero runtime. It was fast because it wasn't reading anything.
SheetKit now writes default values for fileVersion and workbookPr (matching Excel's own defaults) when they're absent, for compatibility.
Node.js Bindings Faster Than Native Rust?
In some write scenarios, the Node.js bindings beat native Rust.
| Scenario |
Rust |
Node.js |
Overhead |
| Write 50k rows × 20 cols |
544 ms |
469 ms |
−14% (Node.js faster) |
| Write 20k text-heavy rows |
108 ms |
86 ms |
−20% (Node.js faster) |
This happens because V8 is very good at string interning and memory management when building SST data through the batch API (setSheetData). The napi crossing costs less than what V8 saves. I did not expect to see negative overhead, but here we are.
Dogfooding SheetKit
I replaced our previous library with SheetKit at work. Template generation and bulk upload processing have been running fine.
Where it stands today (February 14th):
- Streaming read/write in both Node.js and Rust
- 164 formula functions
- 43 chart types
- Multiple image formats
Read overhead (Node.js vs. Rust): ~4%. Some write scenarios are faster from Node.js. Details at sheetkit.dev.
The library is still experimental and APIs may change. I'll keep using it in production, measuring, and fixing things as they come up. Issues and PRs are always welcome.
Next Post
This covered the what and when. The next post is about the how: orchestrator/sub-agent structure, how I used Claude Code and Codex, the agentic code review loop, where I had to step in, and what I'd do differently.