@spinda_kkmr@fedibird.com
Hashtag
#Unicode
415 posts tagged with this hashtag.
@spinda_kkmr@fedibird.com
@spinda_kkmr@fedibird.com
@mikaeru@mastodon.social
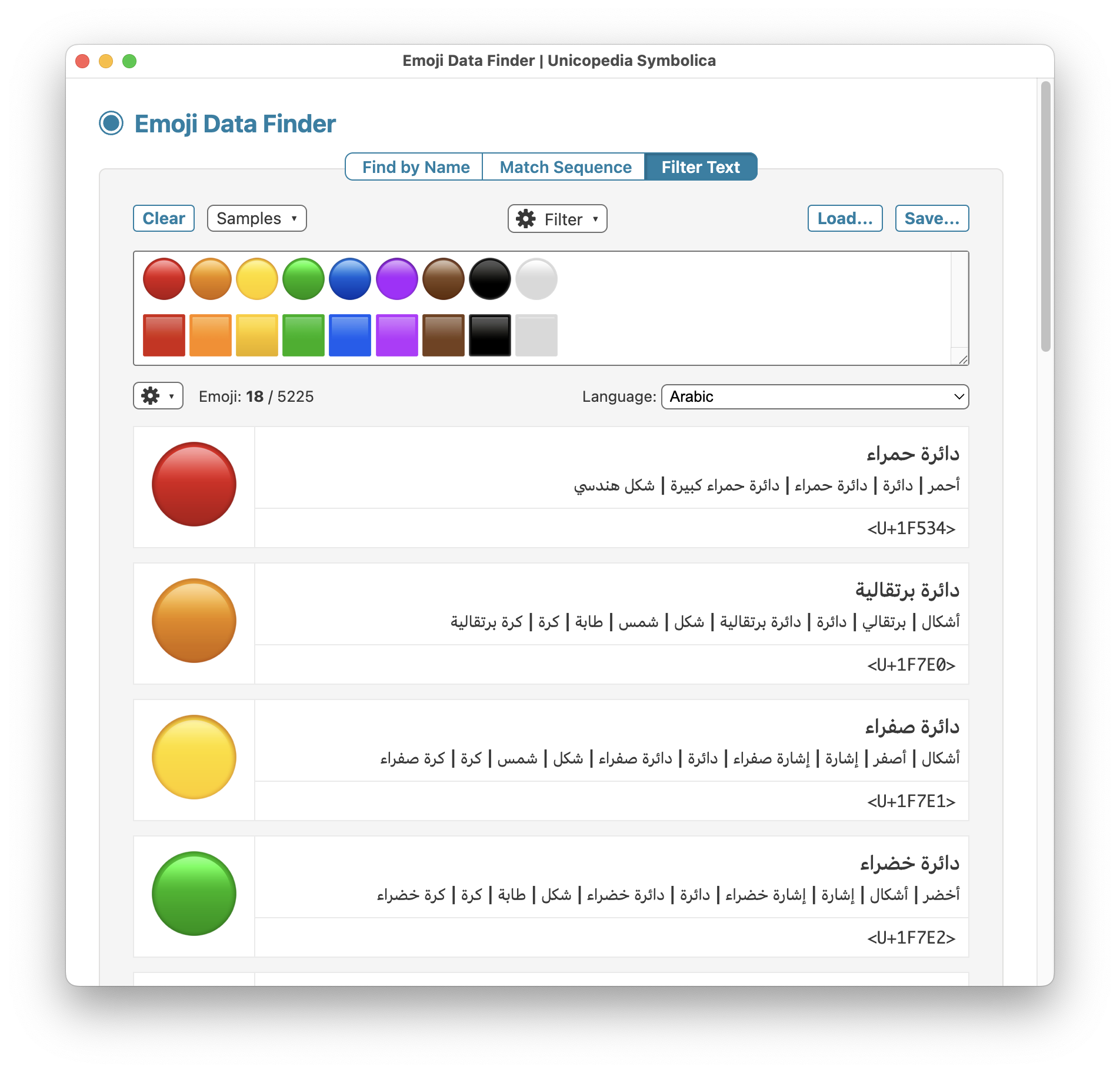
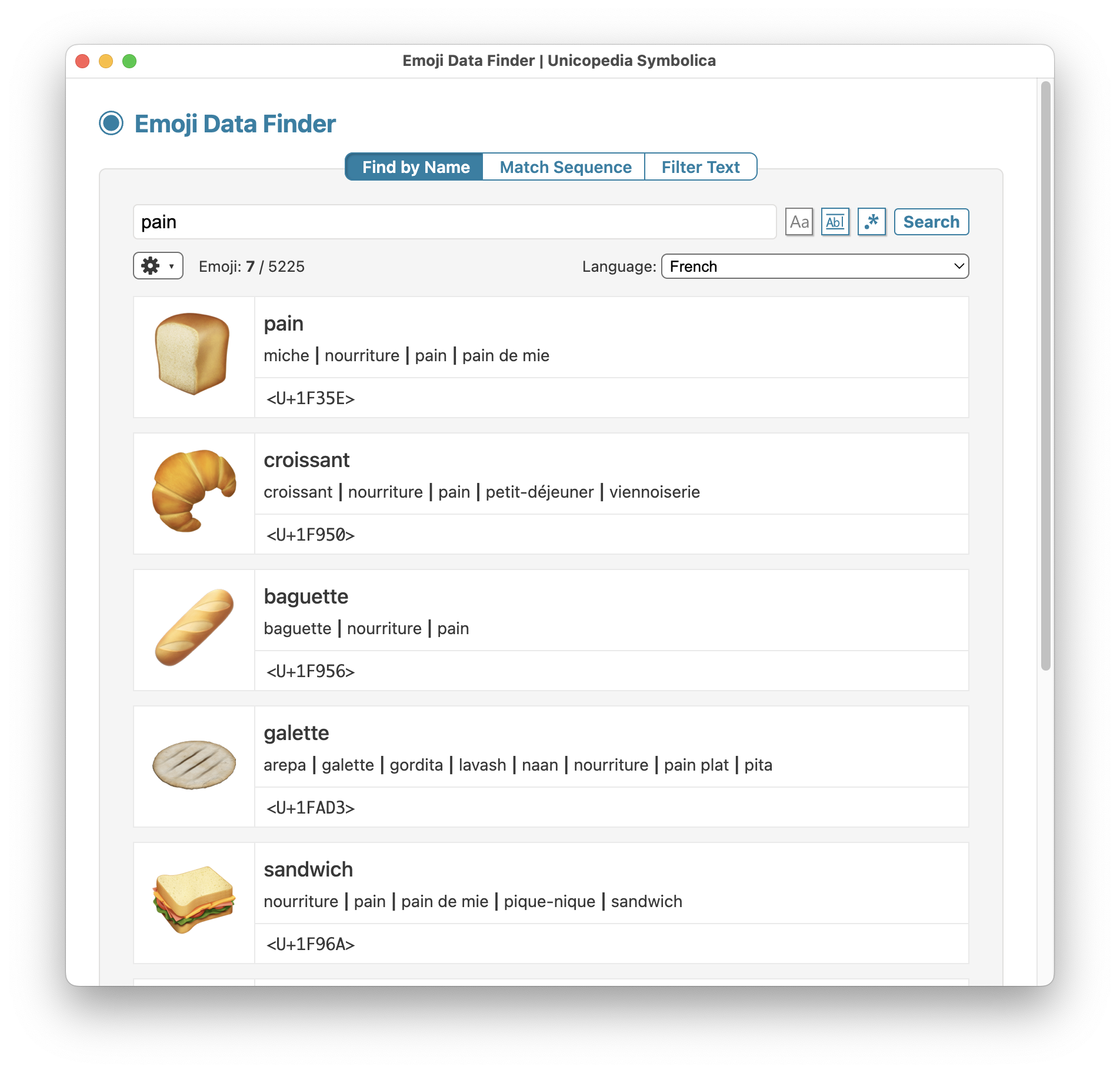
The latest version 2.3.0 of the open-source application "Unicopedia Symbolica" introduces a new Language drop-down menu in the "Emoji Data Finder" utility, which lets you display the short name and keywords of all the emoji in 170 languages, including the ones whose direction is Right-To-Left (RTL).
🔗 https://codeberg.org/tonton-pixel/unicopedia-symbolica
The linguistic data comes from the Unicode CLDR Project:
And all contributions to it are much welcome!
ALT text
Screenshot of the "Filter Text" feature of the "Emoji Data Finder" utility of the "Unicopedia Symbolica" application, with "Language" set to "Arabic".
ALT text
Screenshot of the "Find by Name" feature of the "Emoji Data Finder" utility of the "Unicopedia Symbolica" application, with "Language" set to "French".
@mikaeru@mastodon.social
The latest version 2.3.0 of the open-source application "Unicopedia Symbolica" introduces a new Language drop-down menu in the "Emoji Data Finder" utility, which lets you display the short name and keywords of all the emoji in 170 languages, including the ones whose direction is Right-To-Left (RTL).
🔗 https://codeberg.org/tonton-pixel/unicopedia-symbolica
The linguistic data comes from the Unicode CLDR Project:
And all contributions to it are much welcome!
ALT text
Screenshot of the "Filter Text" feature of the "Emoji Data Finder" utility of the "Unicopedia Symbolica" application, with "Language" set to "Arabic".
ALT text
Screenshot of the "Find by Name" feature of the "Emoji Data Finder" utility of the "Unicopedia Symbolica" application, with "Language" set to "French".
@thias@mastodon.social
UTF-16 reintroduced the old byte split bugs on two byte quantities.
#unicode #utf16
https://george.mand.is/2026/05/my-favorite-bugs-invalid-surrogate-pairs/

george.mand.is
My Favorite Bugs: Invalid Surrogate Pairs
In which I revisit one of my favorite bugs, the invalid surrogate pair.
@thias@mastodon.social
UTF-16 reintroduced the old byte split bugs on two byte quantities.
#unicode #utf16
https://george.mand.is/2026/05/my-favorite-bugs-invalid-surrogate-pairs/
george.mand.is
My Favorite Bugs: Invalid Surrogate Pairs
In which I revisit one of my favorite bugs, the invalid surrogate pair.
@mikaeru@mastodon.social
卢比奥 (lú bǐ ào) ➔ 鲁比奥 (lǔ bǐ ào)
U+5362 卢
U+5362 kDefinition cottage, hut; surname; black
U+5362 kMandarin lú
🔗 https://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=5362
➔
U+9C81 鲁
U+9C81 kDefinition foolish, stupid, rash; vulgar
U+9C81 kMandarin lǔ
🔗 https://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=9C81

unicode.org
Unihan data for U+9C81
@CourrierInter@flipboard.com
Sommet. Changement de nom, survêtement à la Maduro : l’étrange voyage de Marco Rubio en Chine
https://www.courrierinternational.com/article/sommet-changement-de-nom-survetement-a-la-maduro-l-etrange-voyage-de-marco-rubio-en-chine_243997?utm_source=flipboard&utm_medium=activitypub
Publié dans Asie @asie-CourrierInter

courrierinternational.com
Changement de nom, survêtement à la Maduro : l’étrange voyage de Marco Rubio en Chine
Mercredi 13 mai, Donald Trump est arrivé à Pékin pour rencontrer son homologue, Xi Jinping. Dans le cadre de ce déplacement, il est accompagné de son secrétaire...
@jdlh@mstdn.ca · Reply to silverpill
@silverpill @Profpatsch @hongminhee @liaizon @Edent @north @aumetra
I have considered publishing an FEP about #GloballyInclusiveHandles . At FediForum six months ago I got the advice to write three:
1. Advocating for #GloballyInclusive handles and laying out requirements and issues
2. Explaining prior art from #Unicode technical annexes on domain names and identifiers, #ICANN label generation rules for DNS, #UniversalAcceptance, email addresses, etc.
3. Advocating for linkification of globally inclusive handles and layout out requirements and issues.
Do those sound like good FEPs to write at this point?
@SavaRocks@mastodon.social
ASCII Chessboard, No HTML Required - Sometimes, when I have absolutely nothing to do, I play with ASCII characters in vim. Today I made an ASCII chess board with black and white chess pieces. I'm pretty sure I'm not the first one to make an ascii chessboard and I won't be the last. I thought it looks pretty nice so I wanted to share it on my blog.
Full blog post at https://sava.rocks/blog/ascii-chessboard-no-html-required/

ALT text
ASCII Chessboard
@SavaRocks@mastodon.social
ASCII Chessboard, No HTML Required - Sometimes, when I have absolutely nothing to do, I play with ASCII characters in vim. Today I made an ASCII chess board with black and white chess pieces. I'm pretty sure I'm not the first one to make an ascii chessboard and I won't be the last. I thought it looks pretty nice so I wanted to share it on my blog.
Full blog post at https://sava.rocks/blog/ascii-chessboard-no-html-required/
ALT text
ASCII Chessboard
@mikaeru@mastodon.social
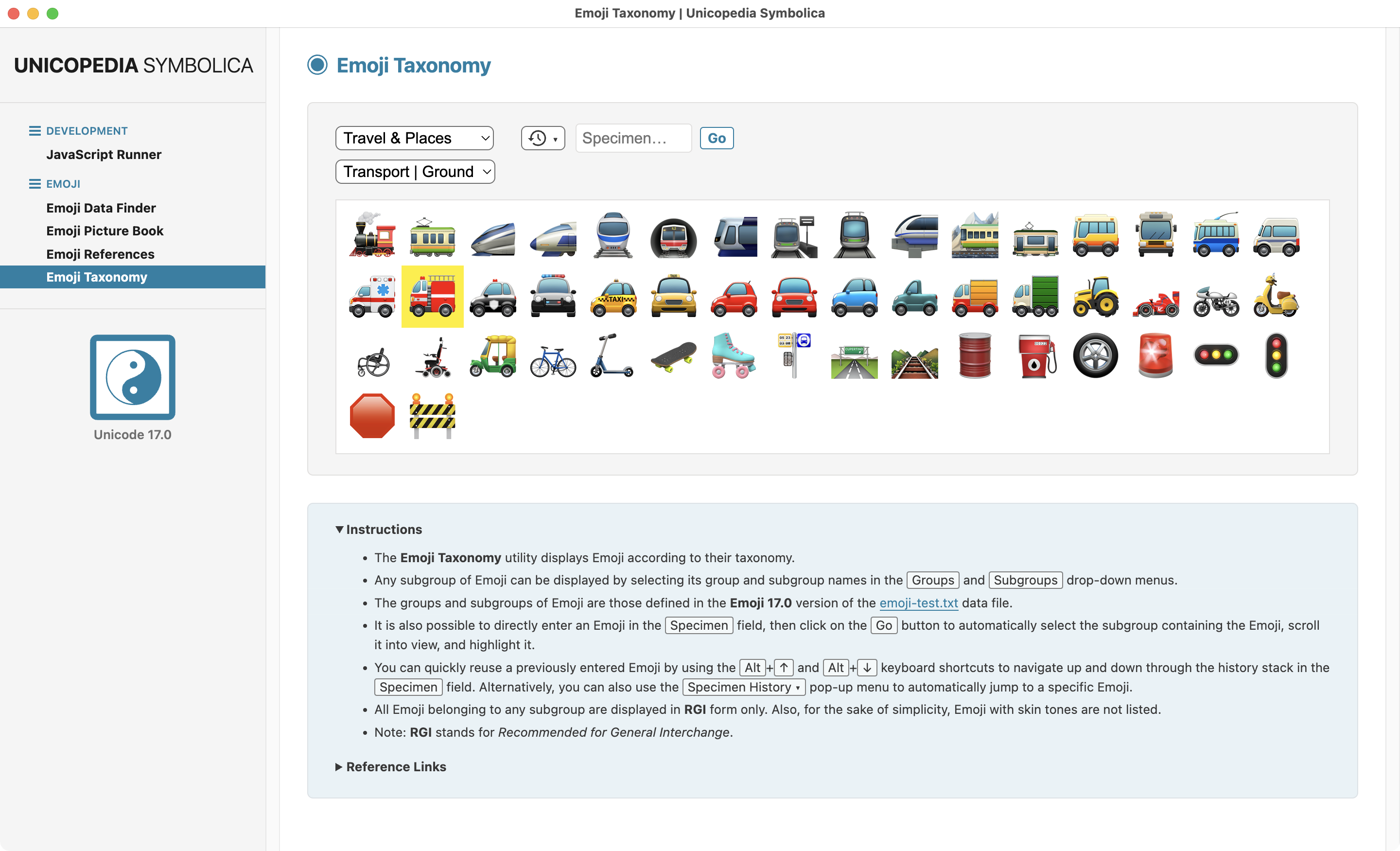
The latest version 2.0.0 of the open-source application "Unicopedia Symbolica" (previously part of the "Unicopedia Plus" application) adds a new "Emoji Taxonomy" utility.
ALT text
Screenshot of the Emoji Taxonomy utility of the Unicopedia Symbolica application
@mikaeru@mastodon.social
The latest version 2.0.0 of the open-source application "Unicopedia Symbolica" (previously part of the "Unicopedia Plus" application) adds a new "Emoji Taxonomy" utility.
ALT text
Screenshot of the Emoji Taxonomy utility of the Unicopedia Symbolica application
@X31Andy@mastodon.green
Today I learned that the 64 I Ching hexagram symbols are all included in Unicode.
I'm fairly sure I'll never need to use them so I'll add it to my ever growing list of probably useless bits of knowledge.
https://en.wikipedia.org/wiki/List_of_hexagrams_of_the_I_Ching
en.wikipedia.org
List of hexagrams of the I Ching - Wikipedia
@X31Andy@mastodon.green
Today I learned that the 64 I Ching hexagram symbols are all included in Unicode.
I'm fairly sure I'll never need to use them so I'll add it to my ever growing list of probably useless bits of knowledge.
https://en.wikipedia.org/wiki/List_of_hexagrams_of_the_I_Ching
en.wikipedia.org
List of hexagrams of the I Ching - Wikipedia
@mikaeru@mastodon.social
Unicode Emoji: Money, Money, Money...
• <U+1F4B6> euro banknote
• <U+1F4B4> yen banknote
• <U+1F4B7> pound banknote
• <U+1F4B5> dollar banknote
• <U+1FA99> coin
• <U+1F4B0> money bag
• <U+1F4B8> money with wings
• <U+1F911> money-mouth face

ALT text
Unicode Emoji: Money, Money, Money... 💶💴💷💵 🪙💰💸🤑
@mikaeru@mastodon.social
Unicode Emoji: Money, Money, Money...
• <U+1F4B6> euro banknote
• <U+1F4B4> yen banknote
• <U+1F4B7> pound banknote
• <U+1F4B5> dollar banknote
• <U+1FA99> coin
• <U+1F4B0> money bag
• <U+1F4B8> money with wings
• <U+1F911> money-mouth face
ALT text
Unicode Emoji: Money, Money, Money... 💶💴💷💵 🪙💰💸🤑
@mikaeru@mastodon.social

@headword@lingo.lol
Interesting video about the encoding of Maya script for computing

youtube.com
Kevin Graaf: Computerising Hieroglyphic Scripts
This presentation was part of the VIEWS conference Writing as Visual Engagement (WAVE 2) held on 26-29 March 2026.Computer scientist Kevin Graaf presents his...
@headword@lingo.lol
Interesting video about the encoding of Maya script for computing
youtube.com
Kevin Graaf: Computerising Hieroglyphic Scripts
This presentation was part of the VIEWS conference Writing as Visual Engagement (WAVE 2) held on 26-29 March 2026.Computer scientist Kevin Graaf presents his...
@w3cdevs@w3c.social
A character encoding defines how text is stored as bytes. If you’ve seen “café” instead of “café,” that’s an encoding mismatch. This intro covers how encoding works, how #Unicode and UTF-8 relate, and why mistakes break apps and websites. It also matters beyond #developers, affecting readability, search, data exchange, #accessibility and whether people see text correctly online.
🎬 Watch @xfq, @w3c's Internationalization Lead, explain what character encoding is: https://youtu.be/y2ay7otbFWk
#i18n

ALT text
The word "café" is written as “café” (on the left) instead of “café” (on the right)
@w3cdevs@w3c.social
A character encoding defines how text is stored as bytes. If you’ve seen “café” instead of “café,” that’s an encoding mismatch. This intro covers how encoding works, how #Unicode and UTF-8 relate, and why mistakes break apps and websites. It also matters beyond #developers, affecting readability, search, data exchange, #accessibility and whether people see text correctly online.
🎬 Watch @xfq, @w3c's Internationalization Lead, explain what character encoding is: https://youtu.be/y2ay7otbFWk
#i18n
ALT text
The word "café" is written as “café” (on the left) instead of “café” (on the right)
@w3cdevs@w3c.social
A character encoding defines how text is stored as bytes. If you’ve seen “café” instead of “café,” that’s an encoding mismatch. This intro covers how encoding works, how #Unicode and UTF-8 relate, and why mistakes break apps and websites. It also matters beyond #developers, affecting readability, search, data exchange, #accessibility and whether people see text correctly online.
🎬 Watch @xfq, @w3c's Internationalization Lead, explain what character encoding is: https://youtu.be/y2ay7otbFWk
#i18n
ALT text
The word "café" is written as “café” (on the left) instead of “café” (on the right)
@w3cdevs@w3c.social
A character encoding defines how text is stored as bytes. If you’ve seen “café” instead of “café,” that’s an encoding mismatch. This intro covers how encoding works, how #Unicode and UTF-8 relate, and why mistakes break apps and websites. It also matters beyond #developers, affecting readability, search, data exchange, #accessibility and whether people see text correctly online.
🎬 Watch @xfq, @w3c's Internationalization Lead, explain what character encoding is: https://youtu.be/y2ay7otbFWk
#i18n
ALT text
The word "café" is written as “café” (on the left) instead of “café” (on the right)
@mikaeru@mastodon.social · Reply to Michel Mariani
Full members (voting) of the Unicode Consortium (2026-04-20): Adobe, Airbnb, Apple, Google, Meta, Microsoft, Salesforce, Translated.
🔗 https://home.unicode.org/membership/members/
Compared to the full members list dated 2026-04-04, Amazon has disappeared and Google (re-)appeared. Great "substitution" magic trick indeed!
On a side note, the HTML page source code indicates:
<!-- List generated: 2026-04-20, 16:07:01 GMT -->
and tomorrow starts the UTC #187 meeting (2026-04-21 to 2026-04-23)...

ALT text
Full members (voting) of the Unicode Consortium (2026-04-20): Adobe, Airbnb, Apple, Google, Meta, Microsoft, Salesforce, Translated.
@mikaeru@mastodon.social · Reply to Michel Mariani
Full members (voting) of the Unicode Consortium (2026-04-20): Adobe, Airbnb, Apple, Google, Meta, Microsoft, Salesforce, Translated.
🔗 https://home.unicode.org/membership/members/
Compared to the full members list dated 2026-04-04, Amazon has disappeared and Google (re-)appeared. Great "substitution" magic trick indeed!
On a side note, the HTML page source code indicates:
<!-- List generated: 2026-04-20, 16:07:01 GMT -->
and tomorrow starts the UTC #187 meeting (2026-04-21 to 2026-04-23)...
ALT text
Full members (voting) of the Unicode Consortium (2026-04-20): Adobe, Airbnb, Apple, Google, Meta, Microsoft, Salesforce, Translated.
@seanpm2001@techhub.social
I am not getting very good results online, so I am asking here. Is it possible to apply bold/italic to only the combining character of a letter (such as the ̈ within ö)
The character did not render correctly in my post (after pasting, the mark applied to the e, it didn't while I was drafting this) I am referring to the combining character in the included image, or U+0308 (Combining Diæresis)
I have been working on a large linguistic dictionary, and I am interested in doing something like this. #linguistics #unicode #richtext #formatting #syntax #help

ALT text
O with diaeresis
@mikaeru@mastodon.social
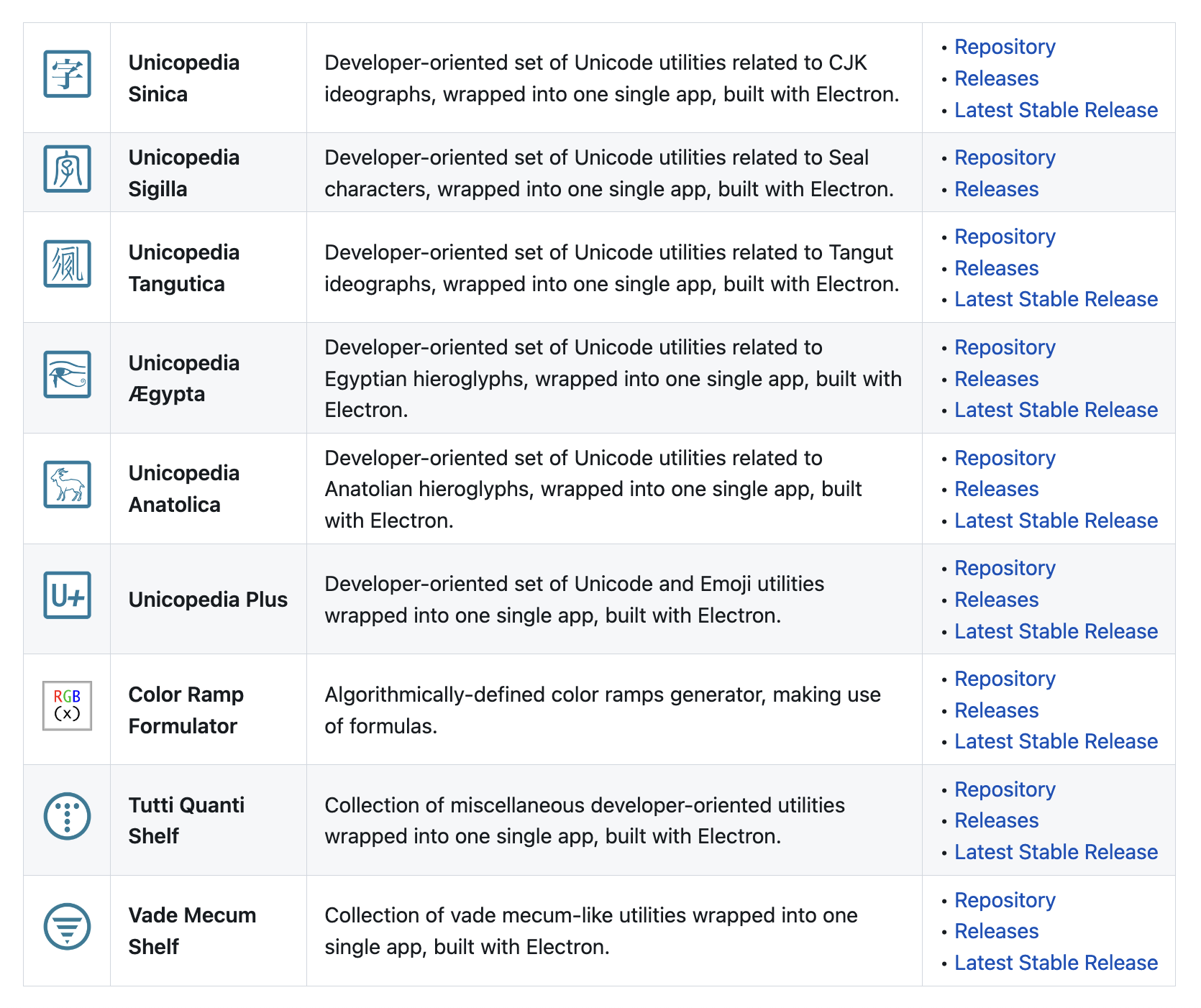
While implementing a file drag-and-drop feature in one of my Electron-based apps, I fortuitously found an issue in the Electron framework which I believe could be a major security hole... Fortunately, this was not too difficult to fix, but I still don't understand why this has been overlooked so far...
All applications have been corrected and can be downloaded from my Codeberg repository:
🔗 https://codeberg.org/tonton-pixel/
ALT text
List of open-source desktop applications from the Codeberg repository: https://codeberg.org/tonton-pixel/
@mikaeru@mastodon.social
While implementing a file drag-and-drop feature in one of my Electron-based apps, I fortuitously found an issue in the Electron framework which I believe could be a major security hole... Fortunately, this was not too difficult to fix, but I still don't understand why this has been overlooked so far...
All applications have been corrected and can be downloaded from my Codeberg repository:
🔗 https://codeberg.org/tonton-pixel/
ALT text
List of open-source desktop applications from the Codeberg repository: https://codeberg.org/tonton-pixel/
@stefan@stefanbohacek.online
A pretty neat online tool for making Unicode wireframes.
via @piccalilli
wiretext.app
Wiretext — Unicode Wireframe Design Tool
A spatial design tool where everything renders as Unicode box-drawing characters. Create wireframes, diagrams, and mockups. Share as text.
@stefan@stefanbohacek.online
A pretty neat online tool for making Unicode wireframes.
via @piccalilli
wiretext.app
Wiretext — Unicode Wireframe Design Tool
A spatial design tool where everything renders as Unicode box-drawing characters. Create wireframes, diagrams, and mockups. Share as text.
@tainome@mastodon.design
A cool little guide to Unicode characters that I found (now I want to make a font that has them all):
https://antofthy.gitlab.io/info/data/utf8_demo.txt
#typography #unicode #characters #glyphs #guide #unicodeBlocks
@tainome@mastodon.design
A cool little guide to Unicode characters that I found (now I want to make a font that has them all):
https://antofthy.gitlab.io/info/data/utf8_demo.txt
#typography #unicode #characters #glyphs #guide #unicodeBlocks
@tainome@mastodon.design
A cool little guide to Unicode characters that I found (now I want to make a font that has them all):
https://antofthy.gitlab.io/info/data/utf8_demo.txt
#typography #unicode #characters #glyphs #guide #unicodeBlocks
@tainome@mastodon.design
A cool little guide to Unicode characters that I found (now I want to make a font that has them all):
https://antofthy.gitlab.io/info/data/utf8_demo.txt
#typography #unicode #characters #glyphs #guide #unicodeBlocks
@hugovk@mastodon.social · Reply to SnoopJ
@SnoopJ On the topic of Unicode updates, what do you think about this? https://discuss.python.org/t/allow-beta-ucd-files-to-be-used-in-the-future/106626
#Python #Unicode

discuss.python.org
Allow beta UCD files to be used in the future?
The next beta review period of Unicode, Unicode 18, is expected to last from May to July 2026. Beta Review Status. Given that according to PEP 790 – Python 3.15 Release Schedule | peps.python.org, no new features will be allowed starting in 3.15beta1, such feature would be added in the upcoming 3.16: PEP 826 – Python 3.16 Release Schedule | peps.python.org This may seem contrived now, but suppose that a future Unicode’s beta review period overlaps with a future Python version’s alpha releases. ...
@hugovk@mastodon.social · Reply to SnoopJ
@SnoopJ On the topic of Unicode updates, what do you think about this? https://discuss.python.org/t/allow-beta-ucd-files-to-be-used-in-the-future/106626
#Python #Unicode
discuss.python.org
Allow beta UCD files to be used in the future?
The next beta review period of Unicode, Unicode 18, is expected to last from May to July 2026. Beta Review Status. Given that according to PEP 790 – Python 3.15 Release Schedule | peps.python.org, no new features will be allowed starting in 3.15beta1, such feature would be added in the upcoming 3.16: PEP 826 – Python 3.16 Release Schedule | peps.python.org This may seem contrived now, but suppose that a future Unicode’s beta review period overlaps with a future Python version’s alpha releases. ...
more specifically, this PR exposes a curious side effect of the Unicode 15.0 → Unicode 15.1 upgrade when it comes to #Python identifiers: ZWJ is now allowed as a 'continue' character (i.e. you can use it in an identifier as long as it's not the first codepoint)
```
$ python3.12 -c 'print(str.isidentifier("A_\u200d_B"))'
False
$ python3.13 -c 'print(str.isidentifier("A_\u200d_B"))'
True
$ python3.13 -c 'print(str.isidentifier("A_\u200d"))' # unfortunately, a trailing ZWJ is legal too
```
github.com
gh-109559: Update `unicodedata` for Unicode 15.1 by SnoopJ · Pull Request #109560 · python/cpython
This changeset implements #109559, adding Unicode 15.1 support to the internal databases that support the unicodedata module. The bulk of this Unicode update is the addition of a new CJK Ideograph ...
@CSSence@mas.to
✍️ In case you haven’t heard of `font-variant-emoji`, neither have I.

cssence.com
Unicode Variation Selectors
In case you haven’t heard of font-variant-emoji…
@CSSence@mas.to
✍️ In case you haven’t heard of `font-variant-emoji`, neither have I.
cssence.com
Unicode Variation Selectors
In case you haven’t heard of font-variant-emoji…
@mikaeru@mastodon.social · Reply to Michel Mariani

@mikaeru@mastodon.social
The latest version v18.1.0 of the open-source application "Unicopedia Sinica" is now available, embedding all data files required to display CJK ideographs as SVG glyphs in the "CJK Sources" and "CJK Variations" utilities...
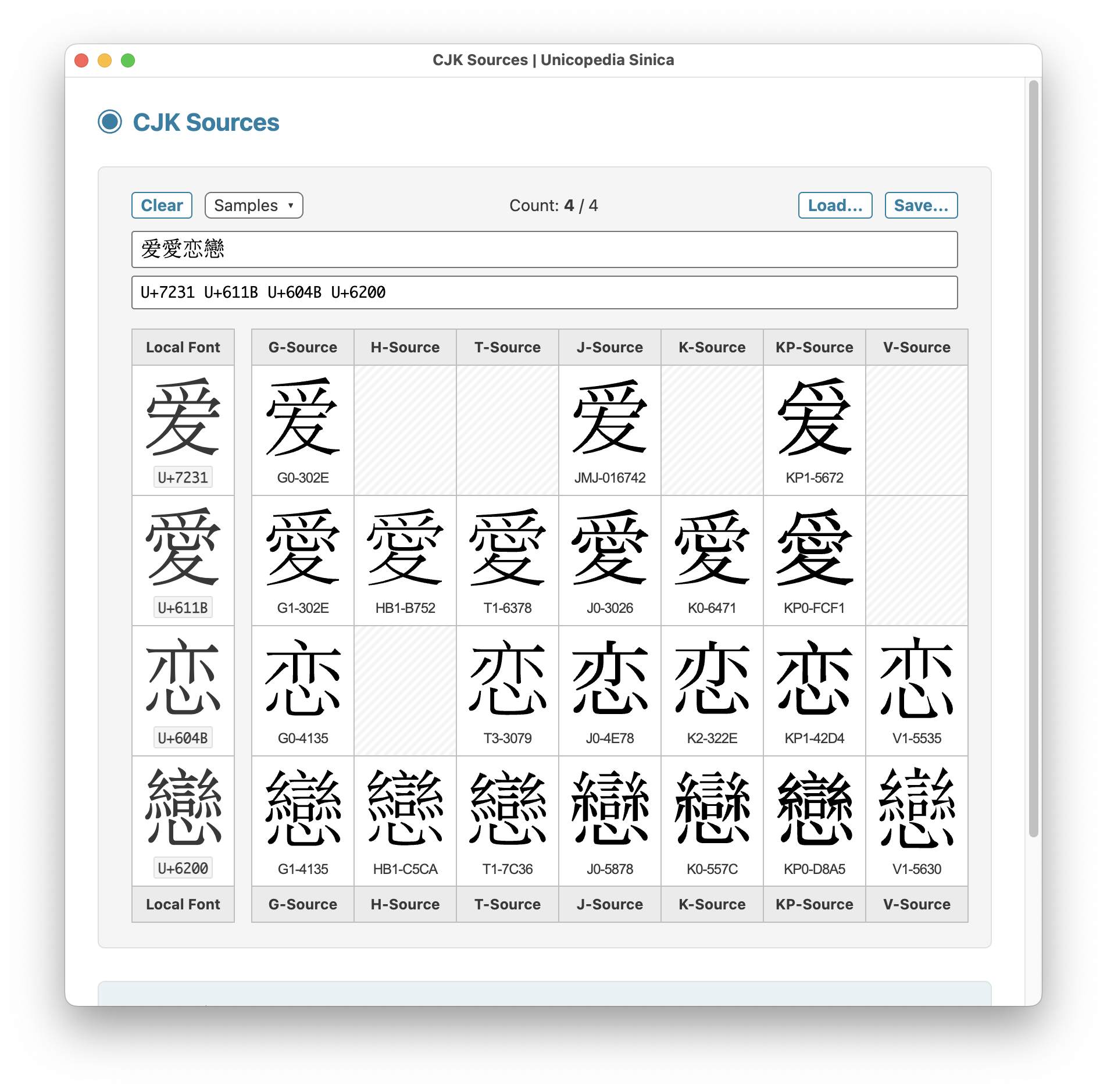
ALT text
Unicopedia Sinica - CJK Sources utility screenshot Four simplified and traditional "Love" characters
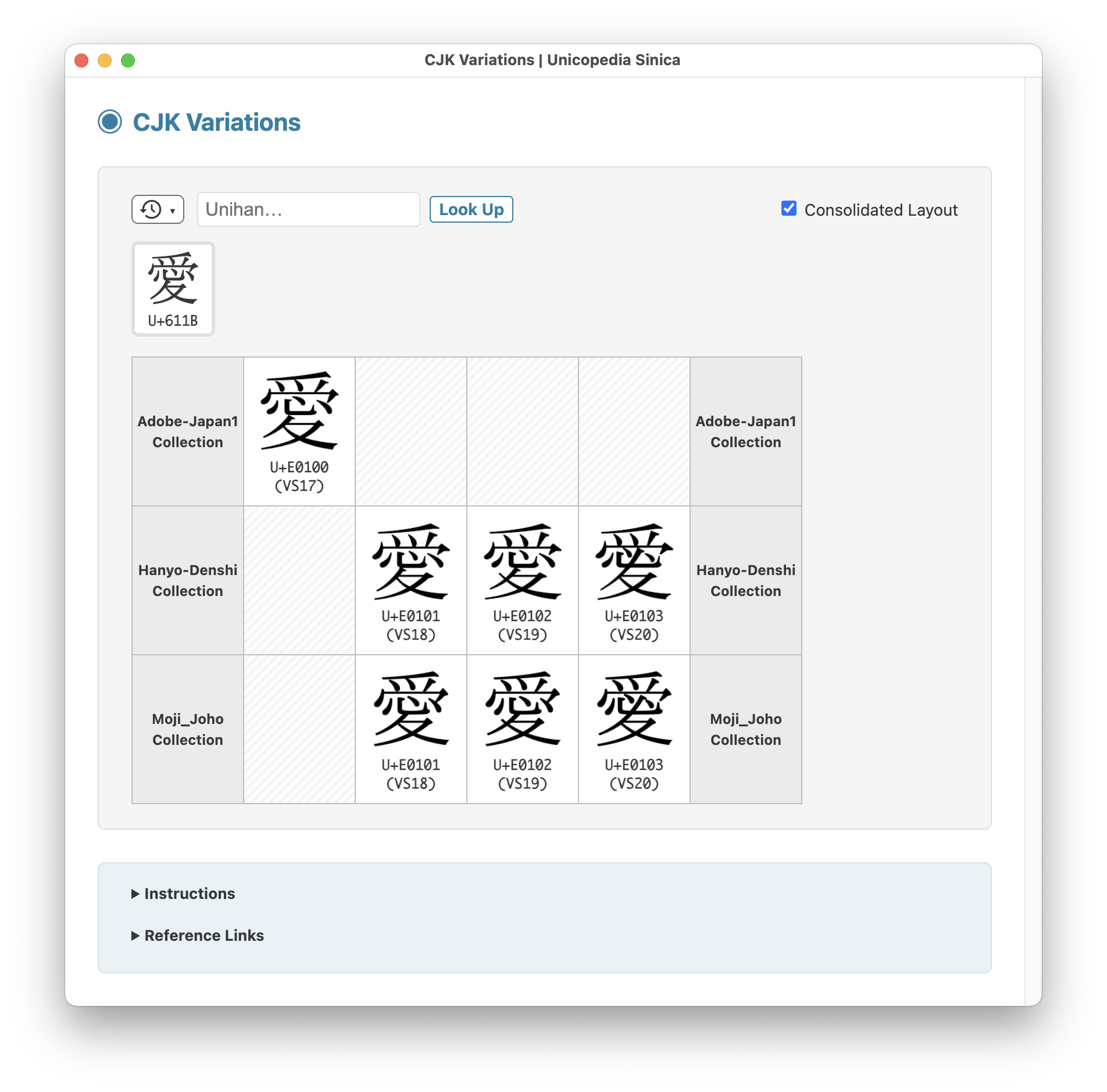
ALT text
Unicopedia Sinica - CJK Variations utility screenshot Japanese glyph variations on "Love" character
@mikaeru@mastodon.social
The latest version v18.1.0 of the open-source application "Unicopedia Sinica" is now available, embedding all data files required to display CJK ideographs as SVG glyphs in the "CJK Sources" and "CJK Variations" utilities...
ALT text
Unicopedia Sinica - CJK Sources utility screenshot Four simplified and traditional "Love" characters
ALT text
Unicopedia Sinica - CJK Variations utility screenshot Japanese glyph variations on "Love" character
@qurlyjoe@mstdn.social
Charcuterie, a visual explorer for #Unicode. Browse the character set, discover related glyphs, and learn more about the scripts, symbols, and shapes that make up the standard.

charcuterie.elastiq.ch
Charcutrie
A visual explorer for Unicode. Browse characters, discover related glyphs, and explore scripts, symbols, and shapes across the standard.
@qurlyjoe@mstdn.social
Charcuterie, a visual explorer for #Unicode. Browse the character set, discover related glyphs, and learn more about the scripts, symbols, and shapes that make up the standard.
charcuterie.elastiq.ch
Charcutrie
A visual explorer for Unicode. Browse characters, discover related glyphs, and explore scripts, symbols, and shapes across the standard.
@qurlyjoe@mstdn.social
Charcuterie, a visual explorer for #Unicode. Browse the character set, discover related glyphs, and learn more about the scripts, symbols, and shapes that make up the standard.
charcuterie.elastiq.ch
Charcutrie
A visual explorer for Unicode. Browse characters, discover related glyphs, and explore scripts, symbols, and shapes across the standard.
@qurlyjoe@mstdn.social
Charcuterie, a visual explorer for #Unicode. Browse the character set, discover related glyphs, and learn more about the scripts, symbols, and shapes that make up the standard.
charcuterie.elastiq.ch
Charcutrie
A visual explorer for Unicode. Browse characters, discover related glyphs, and explore scripts, symbols, and shapes across the standard.
@qurlyjoe@mstdn.social · Reply to Kindness is contagious
Even if you have no vested interest in unicode per se, this is an interesting representation and UI for exploring things that may or may not be related.
#Unicode
@qurlyjoe@mstdn.social
Charcuterie, a visual explorer for #Unicode. Browse the character set, discover related glyphs, and learn more about the scripts, symbols, and shapes that make up the standard.
charcuterie.elastiq.ch
Charcutrie
A visual explorer for Unicode. Browse characters, discover related glyphs, and explore scripts, symbols, and shapes across the standard.
@mikaeru@mastodon.social · Reply to Michel Mariani
Full members (voting) of the Unicode Consortium (2026-04-04): Adobe, Airbnb, Amazon, Apple, Meta, Microsoft, Salesforce, Translated.
🔗 https://home.unicode.org/membership/members/
Adobe is back too! Just in time for Easter Day. Maybe a sign from heaven...

ALT text
Full members (voting) of the Unicode Consortium (2026-04-04): Adobe, Airbnb, Amazon, Apple, Meta, Microsoft, Salesforce, Translated.
@mikaeru@mastodon.social · Reply to Michel Mariani
Full members (voting) of the Unicode Consortium (2026-04-04): Adobe, Airbnb, Amazon, Apple, Meta, Microsoft, Salesforce, Translated.
🔗 https://home.unicode.org/membership/members/
Adobe is back too! Just in time for Easter Day. Maybe a sign from heaven...
ALT text
Full members (voting) of the Unicode Consortium (2026-04-04): Adobe, Airbnb, Amazon, Apple, Meta, Microsoft, Salesforce, Translated.
@dmarti@federate.social
Happy emoji proposal re-opening day to all who celebrate.
Emoji season runs from today through Jul. 31.
(There are still no capybara, guinea pig, or squirrel emoji as far as I know.)
unicode.org
Guidelines for Submitting Unicode® Emoji Proposals
@dmarti@federate.social
Happy emoji proposal re-opening day to all who celebrate.
Emoji season runs from today through Jul. 31.
(There are still no capybara, guinea pig, or squirrel emoji as far as I know.)
unicode.org
Guidelines for Submitting Unicode® Emoji Proposals
@mikaeru@mastodon.social

ALT text
Tower of Babel + Rosetta Stone = Babel Stone
@mikaeru@mastodon.social
Thanks to @jlhwung, the so beautifully crafted 'BabelStone Han' font by Andrew West (魏安), is alive and well!
The latest version 17.0.0, made of 'BabelStoneHanBasic.ttf' and 'BabelStoneHanExtra.ttf', is available from:
🔗 https://github.com/babelstone/babelstonehan-ufo/releases/latest
Release 20250710 · babelstone/babelstonehan-ufo
20250710 - 2026-03-09 Summary Changes from 20250708-beta to 20250710 across all BabelStone Han UFO files. Family Totals: 6 added, 2 modified, 0 removed (8 total changes) BabelStone Han Basic Glyph ...
@mikaeru@mastodon.social
ALT text
Tower of Babel + Rosetta Stone = Babel Stone
@ngate@mastodon.social
👴 Welcome to the riveting world of #writing #systems and Unicode! Because who doesn't want to spend their day deciphering character sets and #script links? 💤 Here's a fun fact: #Chinese #characters were simplified in the 1950s, because evidently, Mainland China thought people had way too much free time. 🙄
https://r12a.github.io/scripts/tutorial/part2 #Unicode #links #tech #humor #HackerNews #ngated
r12a.github.io
An Introduction to Writing Systems
The tutorial will provide you with an understanding of key requirements for implementing writing systems in information technology. It will do this by examining real examples of a wide range of modern scripts to discover features that a computerized implementation must support.
@h4ckernews@mastodon.social
An Introduction to Writing Systems and Unicode
https://r12a.github.io/scripts/tutorial/part2
#HackerNews #WritingSystems #Unicode #Tutorial #Linguistics #TechEducation
r12a.github.io
An Introduction to Writing Systems
The tutorial will provide you with an understanding of key requirements for implementing writing systems in information technology. It will do this by examining real examples of a wide range of modern scripts to discover features that a computerized implementation must support.
@ngate@mastodon.social
👴 Welcome to the riveting world of #writing #systems and Unicode! Because who doesn't want to spend their day deciphering character sets and #script links? 💤 Here's a fun fact: #Chinese #characters were simplified in the 1950s, because evidently, Mainland China thought people had way too much free time. 🙄
https://r12a.github.io/scripts/tutorial/part2 #Unicode #links #tech #humor #HackerNews #ngated
r12a.github.io
An Introduction to Writing Systems
The tutorial will provide you with an understanding of key requirements for implementing writing systems in information technology. It will do this by examining real examples of a wide range of modern scripts to discover features that a computerized implementation must support.
@h4ckernews@mastodon.social
An Introduction to Writing Systems and Unicode
https://r12a.github.io/scripts/tutorial/part2
#HackerNews #WritingSystems #Unicode #Tutorial #Linguistics #TechEducation
r12a.github.io
An Introduction to Writing Systems
The tutorial will provide you with an understanding of key requirements for implementing writing systems in information technology. It will do this by examining real examples of a wide range of modern scripts to discover features that a computerized implementation must support.
@mikaeru@mastodon.social
An excellent "Introduction to Writing Systems & Unicode" and its "Large character sets", by Richard Ishida @ri
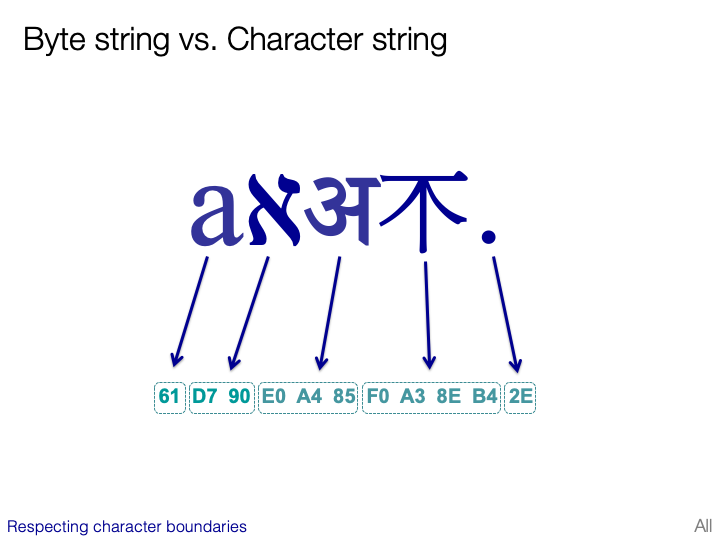
ALT text
Byte string vs. Character string Respecting character boundaries

ALT text
ldeographic description characters Alternative representations of characters Chinese, Japanese, (Korean)
@mikaeru@mastodon.social
An excellent "Introduction to Writing Systems & Unicode" and its "Large character sets", by Richard Ishida @ri
ALT text
Byte string vs. Character string Respecting character boundaries
ALT text
ldeographic description characters Alternative representations of characters Chinese, Japanese, (Korean)
@mikaeru@mastodon.social
An excellent "Introduction to Writing Systems & Unicode" and its "Large character sets", by Richard Ishida @ri
ALT text
Byte string vs. Character string Respecting character boundaries
ALT text
ldeographic description characters Alternative representations of characters Chinese, Japanese, (Korean)
@mikaeru@mastodon.social
An excellent "Introduction to Writing Systems & Unicode" and its "Large character sets", by Richard Ishida @ri
ALT text
Byte string vs. Character string Respecting character boundaries
ALT text
ldeographic description characters Alternative representations of characters Chinese, Japanese, (Korean)
@mikaeru@mastodon.social
An excellent "Introduction to Writing Systems & Unicode" and its "Large character sets", by Richard Ishida @ri
ALT text
Byte string vs. Character string Respecting character boundaries
ALT text
ldeographic description characters Alternative representations of characters Chinese, Japanese, (Korean)
@Flittermouse@girlcock.club · Reply to Terence Eden
@mikaeru@mastodon.social
- Technically speaking, Khitan Small Script and Yi script are not included (yet) in the data for non-Han ideographic scripts.
- The Jurchen and Seal scripts are poised to be officially added to Unicode 18.0 in September 2026...
- BabelStone (Andrew West) reference links:
🔗 https://www.babelstone.co.uk/Jurchen/
🔗 https://www.babelstone.co.uk/Khitan/
🔗 https://www.babelstone.co.uk/Yi/
#Unicode #Ideographic #Unihan #CJK #CJKV #Jurchen #Khitan #Nüshu #Seal #Tangut #Yi
babelstone.co.uk
Babel Stone : Yi
@mikaeru@mastodon.social
About two-thirds of the #Unicode 17.0 standard characters originate from China, most of them of ideographic nature, and are therefore largely over-represented...
Ideographic: 110,943
Han: 103,351
Non-Han (Khitan Small Script + Nüshu + Tangut + Yi): 9,148
Han + Non-Han: 112,499
Standard: 159,799
Ideographic / Standard: 69.43 %
(Han + Non-Han) / Standard: 70.40 %
UAX #38: Unicode Han Database (Unihan)
https://www.unicode.org/reports/tr38/
UAX #60: Data for non Han Ideographic Scripts
https://www.unicode.org/reports/tr60/
unicode.org
UAX #60: Data for non Han Ideographic Scripts
@mikaeru@mastodon.social
About two-thirds of the #Unicode 17.0 standard characters originate from China, most of them of ideographic nature, and are therefore largely over-represented...
Ideographic: 110,943
Han: 103,351
Non-Han (Khitan Small Script + Nüshu + Tangut + Yi): 9,148
Han + Non-Han: 112,499
Standard: 159,799
Ideographic / Standard: 69.43 %
(Han + Non-Han) / Standard: 70.40 %
UAX #38: Unicode Han Database (Unihan)
https://www.unicode.org/reports/tr38/
UAX #60: Data for non Han Ideographic Scripts
https://www.unicode.org/reports/tr60/
unicode.org
UAX #60: Data for non Han Ideographic Scripts
@mikaeru@mastodon.social
- Technically speaking, Khitan Small Script and Yi script are not included (yet) in the data for non-Han ideographic scripts.
- The Jurchen and Seal scripts are poised to be officially added to Unicode 18.0 in September 2026...
- BabelStone (Andrew West) reference links:
🔗 https://www.babelstone.co.uk/Jurchen/
🔗 https://www.babelstone.co.uk/Khitan/
🔗 https://www.babelstone.co.uk/Yi/
#Unicode #Ideographic #Unihan #CJK #CJKV #Jurchen #Khitan #Nüshu #Seal #Tangut #Yi
babelstone.co.uk
Babel Stone : Yi
@mikaeru@mastodon.social
About two-thirds of the #Unicode 17.0 standard characters originate from China, most of them of ideographic nature, and are therefore largely over-represented...
Ideographic: 110,943
Han: 103,351
Non-Han (Khitan Small Script + Nüshu + Tangut + Yi): 9,148
Han + Non-Han: 112,499
Standard: 159,799
Ideographic / Standard: 69.43 %
(Han + Non-Han) / Standard: 70.40 %
UAX #38: Unicode Han Database (Unihan)
https://www.unicode.org/reports/tr38/
UAX #60: Data for non Han Ideographic Scripts
https://www.unicode.org/reports/tr60/
unicode.org
UAX #60: Data for non Han Ideographic Scripts
@v_i_o_l_a@openbiblio.social
"graphic languages: a visual guide to the world’s writing systems" – ein wunderbares buch für #schrift-nerds wie mich. 😊
https://www.slanted.de/product/graphic-languages-a-visual-guide-to-the-worlds-writing-systems/
#schriftsysteme #unicode #typografie

ALT text
foto der titelseite des buchs "graphic languages: a visual guide to the world’s writing systems"

ALT text
foto einer doppelseite aus dem buch "graphic languages: a visual guide to the world’s writing systems"

ALT text
foto einer doppelseite aus dem buch "graphic languages: a visual guide to the world’s writing systems"

ALT text
foto einer doppelseite aus dem buch "graphic languages: a visual guide to the world’s writing systems"
@v_i_o_l_a@openbiblio.social
"graphic languages: a visual guide to the world’s writing systems" – ein wunderbares buch für #schrift-nerds wie mich. 😊
https://www.slanted.de/product/graphic-languages-a-visual-guide-to-the-worlds-writing-systems/
#schriftsysteme #unicode #typografie
ALT text
foto der titelseite des buchs "graphic languages: a visual guide to the world’s writing systems"
ALT text
foto einer doppelseite aus dem buch "graphic languages: a visual guide to the world’s writing systems"
ALT text
foto einer doppelseite aus dem buch "graphic languages: a visual guide to the world’s writing systems"
ALT text
foto einer doppelseite aus dem buch "graphic languages: a visual guide to the world’s writing systems"
@mikaeru@mastodon.social
About two-thirds of the #Unicode 17.0 standard characters originate from China, most of them of ideographic nature, and are therefore largely over-represented...
Ideographic: 110,943
Han: 103,351
Non-Han (Khitan Small Script + Nüshu + Tangut + Yi): 9,148
Han + Non-Han: 112,499
Standard: 159,799
Ideographic / Standard: 69.43 %
(Han + Non-Han) / Standard: 70.40 %
UAX #38: Unicode Han Database (Unihan)
https://www.unicode.org/reports/tr38/
UAX #60: Data for non Han Ideographic Scripts
https://www.unicode.org/reports/tr60/
unicode.org
UAX #60: Data for non Han Ideographic Scripts
@Edent@mastodon.social
Which of these #Unicode symbols do you think *best* represents the concept of "copy"?
That is, if you click it, something will be copied to your clipboard.
(Other suggestions welcome if they are in Unicode.)
- ⮺18 (5%)
- ⎘139 (39%)
- ⎙2 (1%)
- ⧉194 (55%)
@Edent@mastodon.social
Which of these #Unicode symbols do you think *best* represents the concept of "copy"?
That is, if you click it, something will be copied to your clipboard.
(Other suggestions welcome if they are in Unicode.)
- ⮺18 (5%)
- ⎘139 (39%)
- ⎙2 (1%)
- ⧉194 (55%)
@mikaeru@mastodon.social
The latest version 3.5.0 of the open-source application "Unicopedia Ægypta" adds a new "Cross-Referenced" field to the "Unikemet Inspector" utility.
🔗 https://codeberg.org/tonton-pixel/unicopedia-aegypta
It relies on the important "Unikemet" database, which is an impressive work, still in progress... Feedback is welcome!
Public Review Issue #538: Proposed Update UAX #57, Unicode Egyptian Hieroglyph Database (Unikemet)
https://www.unicode.org/review/pri538/
https://www.unicode.org/reports/tr57/tr57-6.html
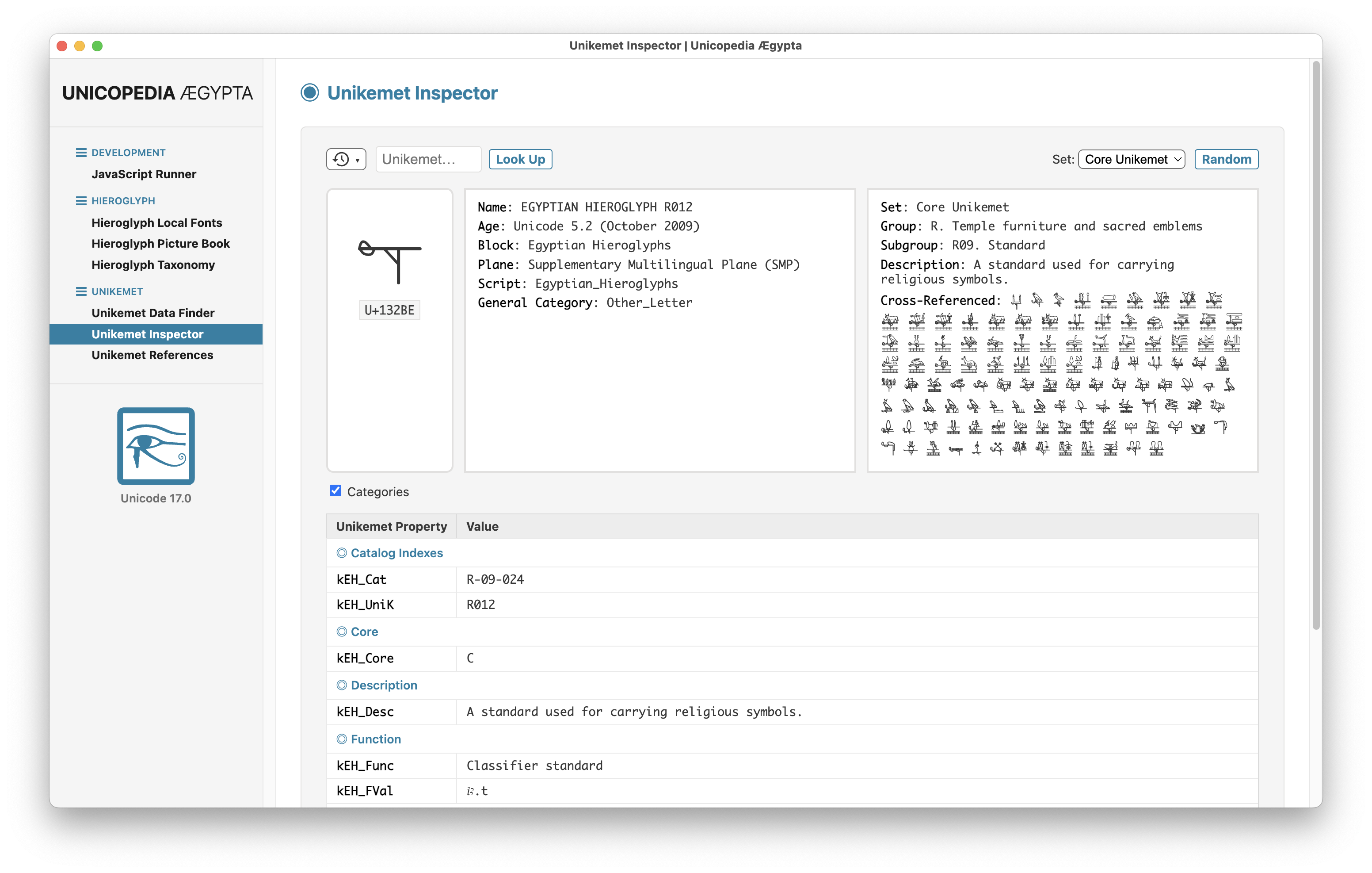
ALT text
Screenshot of the Unikemet Inspector utility of the Unicopedia Ægypta application
@mikaeru@mastodon.social
The latest version 3.5.0 of the open-source application "Unicopedia Ægypta" adds a new "Cross-Referenced" field to the "Unikemet Inspector" utility.
🔗 https://codeberg.org/tonton-pixel/unicopedia-aegypta
It relies on the important "Unikemet" database, which is an impressive work, still in progress... Feedback is welcome!
Public Review Issue #538: Proposed Update UAX #57, Unicode Egyptian Hieroglyph Database (Unikemet)
https://www.unicode.org/review/pri538/
https://www.unicode.org/reports/tr57/tr57-6.html
ALT text
Screenshot of the Unikemet Inspector utility of the Unicopedia Ægypta application
@Edent@mastodon.social
Which of these #Unicode symbols do you think *best* represents the concept of "copy"?
That is, if you click it, something will be copied to your clipboard.
(Other suggestions welcome if they are in Unicode.)
- ⮺18 (5%)
- ⎘139 (39%)
- ⎙2 (1%)
- ⧉194 (55%)
@Edent@mastodon.social
Which of these #Unicode symbols do you think *best* represents the concept of "copy"?
That is, if you click it, something will be copied to your clipboard.
(Other suggestions welcome if they are in Unicode.)
- ⮺18 (5%)
- ⎘139 (39%)
- ⎙2 (1%)
- ⧉194 (55%)
@lascapi@social.tchncs.de
"Why does "👩🏾🌾" have a length of 7 in #JavaScript?"
A very nice analyse!
#utf16 #unicode
by @EvanHahn
https://evanhahn.com/javascript-string-lengths/
evanhahn.com
Why does "👩🏾🌾" have a length of 7 in JavaScript?
👩🏾🌾 is made up of 1 grapheme cluster, 4 scalars, and 7 UTF-16 code units.
@lascapi@social.tchncs.de
"Why does "👩🏾🌾" have a length of 7 in #JavaScript?"
A very nice analyse!
#utf16 #unicode
by @EvanHahn
https://evanhahn.com/javascript-string-lengths/
evanhahn.com
Why does "👩🏾🌾" have a length of 7 in JavaScript?
👩🏾🌾 is made up of 1 grapheme cluster, 4 scalars, and 7 UTF-16 code units.
@sleepycat@infosec.exchange
"The invisible #Unicode characters were devised decades ago and then largely forgotten. That is, until 2024, when hackers began using the characters to conceal malicious prompts fed to AI engines. While the text was invisible to humans and text scanners, #LLMs had little trouble reading them and following the malicious instructions they conveyed."

arstechnica.com
Supply-chain attack using invisible code hits GitHub and other repositories
Unicode that's invisible to the human eye was largely abandoned—until attackers took notice.
@sleepycat@infosec.exchange
"The invisible #Unicode characters were devised decades ago and then largely forgotten. That is, until 2024, when hackers began using the characters to conceal malicious prompts fed to AI engines. While the text was invisible to humans and text scanners, #LLMs had little trouble reading them and following the malicious instructions they conveyed."
arstechnica.com
Supply-chain attack using invisible code hits GitHub and other repositories
Unicode that's invisible to the human eye was largely abandoned—until attackers took notice.
@thias@mastodon.social
The basic underlying problem is that coders and their tooling assume that code is mostly ASCII, when in reality it is Unicode, which most tools don't handle properly.
I'm just waiting for Bidi-injection toolchain injections…
#coding #unicode #texteditor #toolchain #computersecurity
https://www.aikido.dev/blog/glassworm-returns-unicode-attack-github-npm-vscode

aikido.dev
Glassworm Returns: Invisible Unicode Malware Found in 150+ GitHub Repositories
The Glassworm supply chain attack is back. Researchers uncovered malware hidden in invisible Unicode characters across 150+ GitHub repositories, plus npm packages and VS Code extensions.
@thias@mastodon.social
The basic underlying problem is that coders and their tooling assume that code is mostly ASCII, when in reality it is Unicode, which most tools don't handle properly.
I'm just waiting for Bidi-injection toolchain injections…
#coding #unicode #texteditor #toolchain #computersecurity
https://www.aikido.dev/blog/glassworm-returns-unicode-attack-github-npm-vscode
aikido.dev
Glassworm Returns: Invisible Unicode Malware Found in 150+ GitHub Repositories
The Glassworm supply chain attack is back. Researchers uncovered malware hidden in invisible Unicode characters across 150+ GitHub repositories, plus npm packages and VS Code extensions.
@h4ckernews@mastodon.social
Glassworm Is Back: A New Wave of Invisible Unicode Attacks Hits Repositories
https://www.aikido.dev/blog/glassworm-returns-unicode-attack-github-npm-vscode
#HackerNews #Glassworm #Invisible #Unicode #Attacks #Cybersecurity #GitHub #Repositories
aikido.dev
Glassworm Returns: Invisible Unicode Malware Found in 150+ GitHub Repositories
The Glassworm supply chain attack is back. Researchers uncovered malware hidden in invisible Unicode characters across 150+ GitHub repositories, plus npm packages and VS Code extensions.
@ngate@mastodon.social
🚨 Oh no! The dreaded #Glassworm is back, like a transparent hacker on a mission to confuse developers with invisible #Unicode attacks. With 150 #GitHub repositories compromised, the solution is a dizzying list of acronyms and jargon that promises to protect your code, but only if you squint hard enough to see it! 🐛🔍 #SecurityTheater
https://www.aikido.dev/blog/glassworm-returns-unicode-attack-github-npm-vscode #InvisibleAttacks #SecurityThreat #DeveloperConfusion #HackerNews #ngated
aikido.dev
Glassworm Returns: Invisible Unicode Malware Found in 150+ GitHub Repositories
The Glassworm supply chain attack is back. Researchers uncovered malware hidden in invisible Unicode characters across 150+ GitHub repositories, plus npm packages and VS Code extensions.
@ngate@mastodon.social
🚨 Oh no! The dreaded #Glassworm is back, like a transparent hacker on a mission to confuse developers with invisible #Unicode attacks. With 150 #GitHub repositories compromised, the solution is a dizzying list of acronyms and jargon that promises to protect your code, but only if you squint hard enough to see it! 🐛🔍 #SecurityTheater
https://www.aikido.dev/blog/glassworm-returns-unicode-attack-github-npm-vscode #InvisibleAttacks #SecurityThreat #DeveloperConfusion #HackerNews #ngated
aikido.dev
Glassworm Returns: Invisible Unicode Malware Found in 150+ GitHub Repositories
The Glassworm supply chain attack is back. Researchers uncovered malware hidden in invisible Unicode characters across 150+ GitHub repositories, plus npm packages and VS Code extensions.
@h4ckernews@mastodon.social
Glassworm Is Back: A New Wave of Invisible Unicode Attacks Hits Repositories
https://www.aikido.dev/blog/glassworm-returns-unicode-attack-github-npm-vscode
#HackerNews #Glassworm #Invisible #Unicode #Attacks #Cybersecurity #GitHub #Repositories
aikido.dev
Glassworm Returns: Invisible Unicode Malware Found in 150+ GitHub Repositories
The Glassworm supply chain attack is back. Researchers uncovered malware hidden in invisible Unicode characters across 150+ GitHub repositories, plus npm packages and VS Code extensions.
@alainmi11@mamot.fr
Je viens d'apprendre un truc.
#Typographie #Unicode
Le petits symboles de drapeaux qu'on trouve sur nos claviers avec tous les autres émojis… eh bien ce ne sont PAS des caractères uniques (comme les autres émojis) mais des combinaisons de 2 caractères pris dans la famille des « Regional Indicator Symbol » (https://www.compart.com/fr/unicode/search?q=regional%20indicator#characters ) selon la codification des pays avec 2 caractères de la norme ISO https://fr.wikipedia.org/wiki/ISO_3166-1
1/2

ALT text
Capture d'écran d'une partie des caractères Unicode de la famille des « Regional Indicator Symbol », organisés sur 3 colonnes : – la première colonne donne un aperçu du caractère, par exemple : 🇦 – la seconde colonne donne le code Unicode du caractère, par exemple U+1F1F6 – et la 3e colonne donne le nom du caractère, par exemple Regional Indicator Symbol Letter A

ALT text
Capture d'écran d'une partie des codes pays à 2 caractères selon la norme ISO 3166-1, par exemple : – AF = Afghanistan – BE = Belgique – ES = Espagne etc.
@alainmi11@mamot.fr
Je viens d'apprendre un truc.
#Typographie #Unicode
Le petits symboles de drapeaux qu'on trouve sur nos claviers avec tous les autres émojis… eh bien ce ne sont PAS des caractères uniques (comme les autres émojis) mais des combinaisons de 2 caractères pris dans la famille des « Regional Indicator Symbol » (https://www.compart.com/fr/unicode/search?q=regional%20indicator#characters ) selon la codification des pays avec 2 caractères de la norme ISO https://fr.wikipedia.org/wiki/ISO_3166-1
1/2
ALT text
Capture d'écran d'une partie des caractères Unicode de la famille des « Regional Indicator Symbol », organisés sur 3 colonnes : – la première colonne donne un aperçu du caractère, par exemple : 🇦 – la seconde colonne donne le code Unicode du caractère, par exemple U+1F1F6 – et la 3e colonne donne le nom du caractère, par exemple Regional Indicator Symbol Letter A
ALT text
Capture d'écran d'une partie des codes pays à 2 caractères selon la norme ISO 3166-1, par exemple : – AF = Afghanistan – BE = Belgique – ES = Espagne etc.
@kubikpixel@chaos.social
Beware of blank lines and white spaces — Supply-chain attack using invisible code hits GitHub and other repositories
Unicode that’s invisible to the human eye was largely abandoned - until attackers took notice.
#hacking #blankline #whitespace #github #supplychain #unicode #hack #git #code #coding #invisible #gitrepo #itsecurity #it #itsec
arstechnica.com
Supply-chain attack using invisible code hits GitHub and other repositories
Unicode that's invisible to the human eye was largely abandoned—until attackers took notice.
@kubikpixel@chaos.social
Beware of blank lines and white spaces — Supply-chain attack using invisible code hits GitHub and other repositories
Unicode that’s invisible to the human eye was largely abandoned - until attackers took notice.
#hacking #blankline #whitespace #github #supplychain #unicode #hack #git #code #coding #invisible #gitrepo #itsecurity #it #itsec
arstechnica.com
Supply-chain attack using invisible code hits GitHub and other repositories
Unicode that's invisible to the human eye was largely abandoned—until attackers took notice.
@MichalBryxi@mastodon.world
When I say "IT mostly just runs in circles" I mean it: https://arstechnica.com/security/2026/03/supply-chain-attack-using-invisible-code-hits-github-and-other-repositories/
This article from 2026 describes something I've been fighting with ~17 years ago. Sure, slightly more clever payload and different delivery method, but in principle nothing new: https://github.com/MichalBryxi/Apache-fork-hack-finder-cleaner/tree/master
github.com
GitHub - MichalBryxi/Apache-fork-hack-finder-cleaner: apr < 1.3.6 has vulnerability leading to execution of malicious requests which will then randomly serve "blank" pages when your apache HTTP server is requested
apr < 1.3.6 has vulnerability leading to execution of malicious requests which will then randomly serve "blank" pages when your apache HTTP server is requested - MichalBryxi/Apache-for...
@MichalBryxi@mastodon.world
When I say "IT mostly just runs in circles" I mean it: https://arstechnica.com/security/2026/03/supply-chain-attack-using-invisible-code-hits-github-and-other-repositories/
This article from 2026 describes something I've been fighting with ~17 years ago. Sure, slightly more clever payload and different delivery method, but in principle nothing new: https://github.com/MichalBryxi/Apache-fork-hack-finder-cleaner/tree/master
github.com
GitHub - MichalBryxi/Apache-fork-hack-finder-cleaner: apr < 1.3.6 has vulnerability leading to execution of malicious requests which will then randomly serve "blank" pages when your apache HTTP server is requested
apr < 1.3.6 has vulnerability leading to execution of malicious requests which will then randomly serve "blank" pages when your apache HTTP server is requested - MichalBryxi/Apache-for...
@arstechnica@c.im
Supply-chain attack using invisible code hits GitHub and other repositories https://arstechni.ca/LKbk #supplychainattacks #publicuseareas #Security #Unicode #Biz&IT
arstechnica.com
Supply-chain attack using invisible code hits GitHub and other repositories
Unicode that's invisible to the human eye was largely abandoned—until attackers took notice.
@arstechnica@c.im
Supply-chain attack using invisible code hits GitHub and other repositories https://arstechni.ca/LKbk #supplychainattacks #publicuseareas #Security #Unicode #Biz&IT
arstechnica.com
Supply-chain attack using invisible code hits GitHub and other repositories
Unicode that's invisible to the human eye was largely abandoned—until attackers took notice.
@mikaeru@mastodon.social
Thanks to @jlhwung, the so beautifully crafted 'BabelStone Han' font by Andrew West (魏安), is alive and well!
The latest version 17.0.0, made of 'BabelStoneHanBasic.ttf' and 'BabelStoneHanExtra.ttf', is available from:
🔗 https://github.com/babelstone/babelstonehan-ufo/releases/latest
Release 20250710 · babelstone/babelstonehan-ufo
20250710 - 2026-03-09 Summary Changes from 20250708-beta to 20250710 across all BabelStone Han UFO files. Family Totals: 6 added, 2 modified, 0 removed (8 total changes) BabelStone Han Basic Glyph ...
@rk@mastodon.well.com
The mystery of Unicode ⍼ (U+237C) has been solved!

ionathan.ch
U+237C ⍼ is Azimuth
@rk@mastodon.well.com
The mystery of Unicode ⍼ (U+237C) has been solved!
ionathan.ch
U+237C ⍼ is Azimuth
@mikaeru@mastodon.social · Reply to Michel Mariani
Full members (voting) of the Unicode Consortium (2026-03-10): Airbnb, Amazon, Apple, Meta, Microsoft, Salesforce, Translated.
🔗 https://https://home.unicode.org/membership/members/
Airbnb is back! No comment...

ALT text
Full members (voting) of the Unicode Consortium (2026-03-10): Airbnb, Amazon, Apple, Meta, Microsoft, Salesforce, Translated.
@mikaeru@mastodon.social · Reply to Michel Mariani
Full members (voting) of the Unicode Consortium (2026-03-10): Airbnb, Amazon, Apple, Meta, Microsoft, Salesforce, Translated.
🔗 https://https://home.unicode.org/membership/members/
Airbnb is back! No comment...
ALT text
Full members (voting) of the Unicode Consortium (2026-03-10): Airbnb, Amazon, Apple, Meta, Microsoft, Salesforce, Translated.
Want to know how #Unicode handles Braille?
One code point for each possible glyph.
Not character. Glyph.
There is one code point for each of 2⁸ (256) possible combinations you can punch out of an 8 dot braille pad.
That means the unicode code point for ⠜ can represent literally 18 different characters!

en.wiktionary.org
⠜ - Wiktionary, the free dictionary
Anyways, here's my challenge to somebody.
The CJK space in #Unicode represents ~100,000 Chinese, Japanese, and/or Korean language words.
Can we universalize the Kanji?
鹿 is the character for the animal deer. How can we make that readable to the rest of the world?
Who is a bad enough dude to make a CJK emoji font.
Want to know how #Unicode handles Braille?
One code point for each possible glyph.
Not character. Glyph.
There is one code point for each of 2⁸ (256) possible combinations you can punch out of an 8 dot braille pad.
That means the unicode code point for ⠜ can represent literally 18 different characters!
en.wiktionary.org
⠜ - Wiktionary, the free dictionary
Musqueam language literally uses the North American Phonetic Alphabet.
Is #Unicode going to add a hən̓q̓əmin̓əm̓ block?
- Of course not!
Saanich language uses a modified version of IPA.
Is #Unicode going to add a SENĆOŦEN block?
- Of course not! Saanich gets five supplementary characters and they'll be happy about it.
Would it be possible to represent both of these phonetic alphabets by sharing the same #IPA code points?
Yes! You would literally just need to change the fonts.
ALL CAPS TO IMPLY YELLING
NOT EVERY LANGUAGE HAS AN ALPHABET.
THERE ARE EXISTING LANGUAGES TODAY THAT JUST WRITE DOWN THE SOUNDS IN IPA.
WHAT ARE THE PEOPLE WHO USE THESE LANGUAGES SUPPOSED TO DO WITHOUT IPA IN UNICODE.
WE COULD HAVE A BASICALLY UNIVERSAL ALPHABET IN UNICODE.
YOU COULD CONVERT BETWEEN PHONETIC-BASED SCRIPTS BY CHANGING A FONT.
IPA uses a basically random assortment of characters from whatever existing Unicode blocks had similarly-shaped scripts.
There's no consistent IPA in Unicode. Just a patchwork.
Why does any of this matter?
Well, for one is makes linguistics more difficult.
Unicode is fine with adding a bunch of dead or even undeciphered languages to Unicode to help out academics, but linguists I guess can get fucked.
But also there's a bigger and more obvious problem.
#IPA is the alphabet used to less ambiguously represent sounds.
Just like Latin, Greek, and Cyrillic, it's an alphabet.
The IPA "a" doesn't have the same meaning as the Latin "a" or the Cyrillic "а". Instead it represents the "open front unrounded vowel".
https://en.wikipedia.org/wiki/Open_front_unrounded_vowel
So what #Unicode character are IPA users supposed to use?
Just the Latin one.

en.wikipedia.org
Open front unrounded vowel - Wikipedia
#Unicode goes by characters, not glyphs.
Each Unicode character is supposed to represent a unique meaning, not just the shape associated with a letter.
That's why the glyph "A" is in Unicode more than three times.
It's not actually the same letter in Latin, Greek, and Cyrillic alphabets. They're three different characters represented by the same glyph.
Unicode allows you to make clear which you're talking about.
U+0041 A LATIN CAPITAL LETTER A
U+0391 Α GREEK CAPITAL LETTER ALPHA
U+0410 А CYRILLIC CAPITAL LETTER A
@steven@zeroes.ca
I like #Unicode.
If you happened to have followed me on Twitter, you'll know that I know way more about how emoji work than most people.
But holy crap, did Unicode manage to mess up how they handled #IPA.
For anybody who knows what this means: I think Unicode's handling of IPA is more serious stumble than CJK Unification.
@shaft@piaille.fr
#Unicode 18.0 will add at least 13,000 characters.
“At UTC #185, nearly 13,000 additional characters were approved for encoding in Unicode 18.0.
The approved additions include encoding of Small Seal script ("Seal"), a repertoire of 11,328 ideographic characters. Seal is distinct from modern Han ideographs (aka, "CJK"), but is an important precursor of CJK resulting from the first efforts to standardize writing across Chinese-speaking regions during China's Qin Dynasty. As such, Seal has important cultural significance in China and for Chinese speakers throughout the world”
https://blog.unicode.org/2025/12/utc-185-highlights.html?m=1
More on seal script: https://en.wikipedia.org/wiki/Seal_script

en.wikipedia.org
Seal script - Wikipedia
@unwirehk_mirror@mastodon.hongkongers.net
跨性別專屬中文代名詞「X也」 正式納入 Unicode 系統
由跨性別社群自創的中文代名詞「X也」在 2025 年 9 月正式獲統一碼(Unicode)批准納入 Unico […]
#社交網絡 #科技新聞 #LGBTQ #Unicode
https://unwire.hk/2026/02/11/x-unicode/fun-tech/?utm_source=rss&utm_medium=rss&utm_campaign=x-unicode

@SnoopJ@hachyderm.io
Whoa, I just noticed:
#Unicode Technical Standard #58 was published two weeks ago!
Unicode Link Detection and Formatting:
URLs and Email Addresses
https://www.unicode.org/reports/tr58/
---
【This document specifies two consistent, standardized mechanisms that address [URL] problems, consisting of:
1 )link detection: detecting URLs and email addresses embedded in plain text that properly handles non-ASCII characters, and
2) minimally escaping: minimal escaping of non-ASCII code points in the Path, Query, and Fragment portions of a URL.】
unicode.org
UTS #58: Unicode Link Detection and Formatting: URLs and Email Addresses
@shibao there is a special codepoint called ZERO WIDTH JOINER (abbreviated ZWJ) that is not printable (so you would never "see" it) but which carries the meaning that it's meant to join two codepoints (usually but not *exclusively* emoji) together in some sense.
The semantics for emoji ZWJ sequences (as they are called) allow for fallback behavior that "just" shows the two emoji next to each other if the system is not capable of showing you the glyph for the "combined" form.
@emojipedia has a good blog post about the concept in general: https://blog.emojipedia.org/emoji-zwj-sequences-three-letters-many-possibilities/
And if you want to see the nuts and bolts of the standardization, check #Unicode Technical Report #51, §2.5 ("Emoji ZWJ Sequences"): https://unicode.org/reports/tr51/#Emoji_ZWJ_Sequences
unicode.org
UTS #51: Unicode Emoji
@mikaeru@mastodon.social
The latest post on the Unicode Consortium blog gives an exhaustive list of all the new Unicode properties in regular expressions (regex), and explains why all the supported properties are so important and can be so useful:
https://blog.unicode.org/2026/03/uts-18-more-unicode-properties-in.html

blog.unicode.org
UTS #18: More Unicode Properties in Regular Expressions
Regular Expressions, or “Regex”, are the invisible workhorses of the digital world. Regex allows apps and computer systems to find, validate...
@mikaeru@mastodon.social
The "official" Unicode Regular Expressions (UTS #18) document, dated February 8, 2022, has never been updated since then, and the four new Unicode properties introduced in Unicode 15.1 are only listed in the Proposed Update *draft*, dated May 11, 2023...
This could explain why #Safari, #Firefox, and the #Electron framework (#Chromium) trigger an "invalid property" error for the /\p{IDS_Unary_Operator}/u #regex in JavaScript, while /\p{IDS_Binary_Operator}/u is ok...
@shibao there is a special codepoint called ZERO WIDTH JOINER (abbreviated ZWJ) that is not printable (so you would never "see" it) but which carries the meaning that it's meant to join two codepoints (usually but not *exclusively* emoji) together in some sense.
The semantics for emoji ZWJ sequences (as they are called) allow for fallback behavior that "just" shows the two emoji next to each other if the system is not capable of showing you the glyph for the "combined" form.
@emojipedia has a good blog post about the concept in general: https://blog.emojipedia.org/emoji-zwj-sequences-three-letters-many-possibilities/
And if you want to see the nuts and bolts of the standardization, check #Unicode Technical Report #51, §2.5 ("Emoji ZWJ Sequences"): https://unicode.org/reports/tr51/#Emoji_ZWJ_Sequences
unicode.org
UTS #51: Unicode Emoji
@mikaeru@mastodon.social
The latest version 3.0.0 of the open-source application "Unicopedia Ægypta" is now available, displaying all the representative glyphs of the 4,403 Egyptian hieroglyphs belonging to the "Core Unikemet" set.
🔗 https://codeberg.org/tonton-pixel/unicopedia-aegypta
#Unicopedia #Egyptian #Hieroglyphs #Unikemet #Unicode #NewGardiner #Font
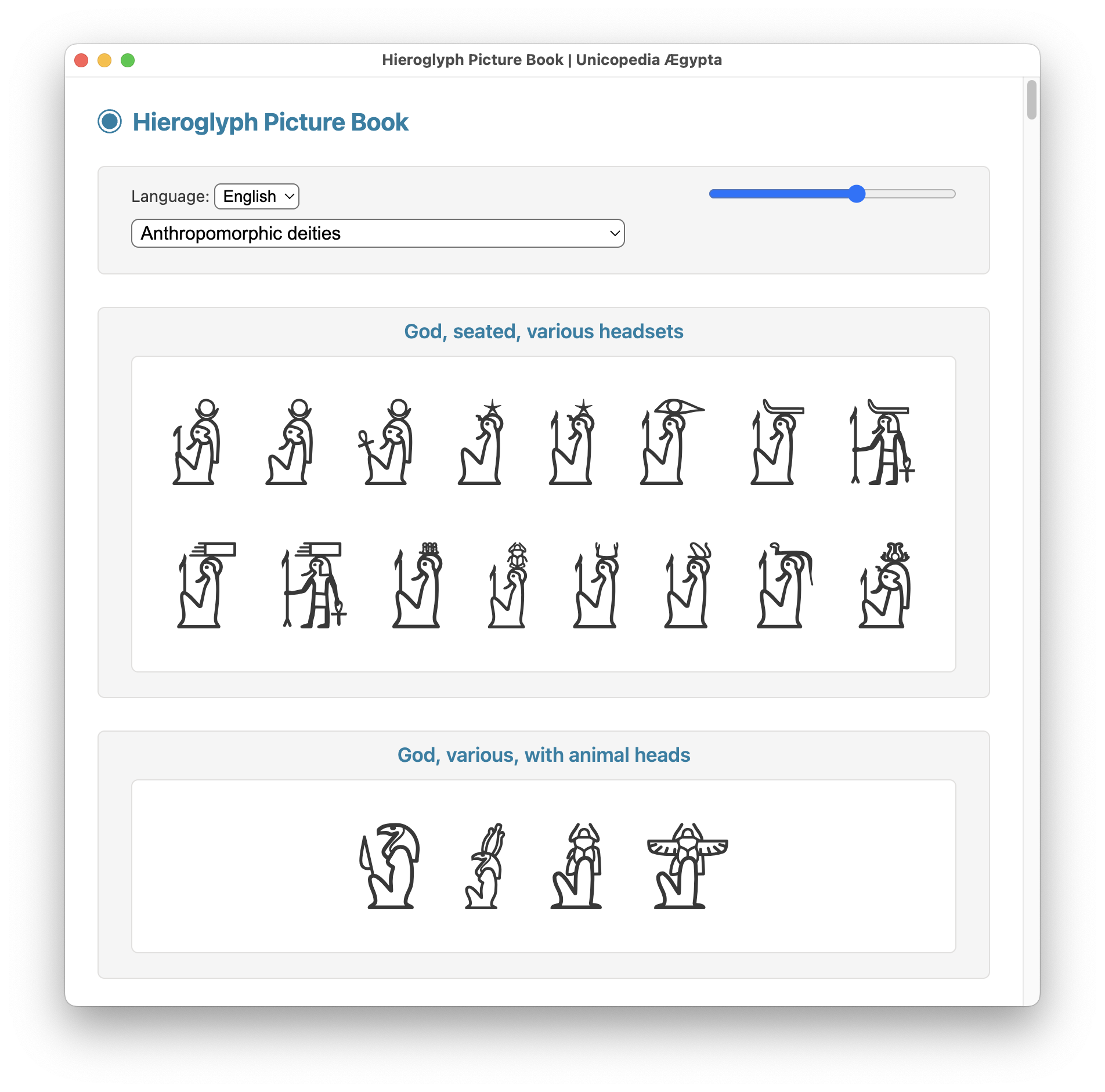
ALT text
Screenshot of the Hieroglyph Picture Book utility of the open-source application Unicopedia Ægypta v.3.0.0
@mikaeru@mastodon.social
Unicode Emoji: Pan-CJK Flags
• <U+1F1E8, U+1F1F3> flag: China [CN]
• <U+1F1ED, U+1F1F0> flag: Hong Kong SAR China [HK]
• <U+1F1EF, U+1F1F5> flag: Japan [JP]
• <U+1F1F0, U+1F1F5> flag: North Korea [KP]
• <U+1F1F0, U+1F1F7> flag: South Korea [KR]
• <U+1F1F2, U+1F1F4> flag: Macao SAR China [MO]
• <U+1F1F2, U+1F1FE> flag: Malaysia [MY]
• <U+1F1F8, U+1F1EC> flag: Singapore [SG]
• <U+1F1F9, U+1F1FC> flag: Taiwan [TW]
• <U+1F1FB, U+1F1F3> flag: Vietnam [VN]

ALT text
Unicode Emoji: Pan-CJK Flags 🇨🇳🇭🇰🇯🇵🇰🇵🇰🇷🇲🇴🇲🇾🇸🇬🇹🇼🇻🇳
@mikaeru@mastodon.social
U+2640 FEMALE SIGN
U+2642 MALE SIGN
U+26A2 DOUBLED FEMALE SIGN
U+26A3 DOUBLED MALE SIGN
U+26A4 INTERLOCKED FEMALE AND MALE SIGN
U+26A5 MALE AND FEMALE SIGN
U+26A6 MALE WITH STROKE SIGN
U+26A7 MALE WITH STROKE AND MALE AND FEMALE SIGN
U+26A8 VERTICAL MALE WITH STROKE SIGN
U+26A9 HORIZONTAL MALE WITH STROKE SIGN
U+26B2 NEUTER

ALT text
Unicode Symbols: Diversity ♀♂⚢⚣⚤⚥⚦⚧⚨⚩⚲
@mikaeru@mastodon.social
#Unicode #Emoji: #Hearts #Galore
U+2764 U+FE0F U+1FA77 U+1F9E1 U+1F49B U+1F49A U+1F499 U+1FA75 U+1F49C U+1F90E U+1F5A4 U+1FA76 U+1F90D
U+1F49F U+2764 U+FE0F U+200D U+1F525 U+1F494 U+2764 U+FE0F U+200D U+1FA79 U+2763 U+FE0F U+1F498 U+1F493 U+1F497 U+1F496 U+1F49D U+1F495 U+1F49E
U+1F970 U+1F60D U+1F618 U+1F63B U+1F48C U+1FAF6 U+1FAF6 U+1F3FB U+1FAF6 U+1F3FC U+1FAF6 U+1F3FD U+1FAF6 U+1F3FE U+1FAF6 U+1F3FF U+1FAC0

ALT text
Unicode Emoji: Hearts Galore ❤️🩷🧡💛💚💙🩵💜🤎🖤🩶🤍 💟❤️🔥💔❤️🩹❣️💘💓💗💖💝💕💞 🥰😍😘😻💌🫶🫶🏻🫶🏼🫶🏽🫶🏾🫶🏿🫀
@mikaeru@mastodon.social

@mikaeru@mastodon.social
U+1F473 U+1F473 U+1F3FB U+1F473 U+1F3FC U+1F473 U+1F3FD U+1F473 U+1F3FE U+1F473 U+1F3FF
U+1F478 U+1F478 U+1F3FB U+1F478 U+1F3FC U+1F478 U+1F3FD U+1F478 U+1F3FE U+1F478 U+1F3FF

ALT text
Unicode Emoji: Skin Tones 👳➔👳🏻👳🏼👳🏽👳🏾👳🏿 👸➔👸🏻👸🏼👸🏽👸🏾👸🏿
@mikaeru@mastodon.social
#Unicode #Emoji: #Math #Geekiness
<U+1F605> <U+1F4A7> <U+1F604>
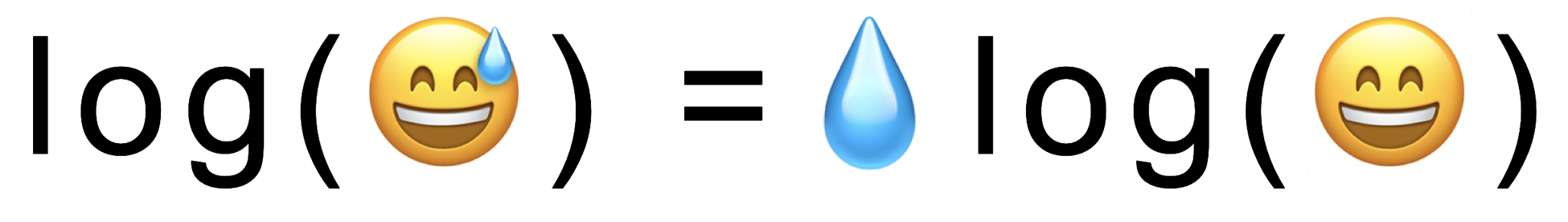
ALT text
Unicode Emoji: Math Geekiness log(😅) =💧log(😄)
@mikaeru@mastodon.social

@mikaeru@mastodon.social · Reply to Michel Mariani
The icon of the new #Unicopedia #Sigilla application shows the provisional #Seal character U+3FBB5 whose equivalent #CJK #ideograph is U+5B57 字, meaning "letter, character, word".

ALT text
Icon of the Unicopedia Sigilla application, with the provisional Seal character U+3FBB5 whose equivalent CJK ideograph is U+5B57 字
@jdlh@mstdn.ca · Reply to Mike Williamson
@sleepycat this paper doesn't cite two relevant official #Unicode reports on the subject: "Unicode Security Mechanisms" https://unicode.org/reports/tr39/ and "Unicode Identifiers and Syntax" https://www.unicode.org/reports/tr31/ . Was the paper interested in solving problems, or just in collecting the engagement from pointing them out?
unicode.org
UAX #31: Unicode Identifiers and Syntax
@mikaeru@mastodon.social
Very interesting insights into currency symbols in Unicode and how their implementation involves decisions and actions on so many different levels:
🔗 https://blog.unicode.org/2026/02/from-central-bank-to-code-point-roadmap.html

blog.unicode.org
From Central Bank to Code Point: A Roadmap for Currency Symbol Implementation
I n the past year, several new currency symbols have been proposed for encoding in the Unicode Standard: February 2025: The Saudi Central Ba...
@aslakr@mastodon.social
This #Unicode technical report (tr58) on non-ASCII characters in urls and email addresses might be relevant for #ActivityPub implementations
unicode.org
UTS #58: Unicode Link Detection and Formatting: URLs and Email Addresses
@Edent@mastodon.social
In *theory* you should be able to follow this test user:
@你好@i18n.viii.fi
But I can't find any Fediverse software which actually supports non-ASCII usernames.
If you are able to see the user, its description, and its avatar - please send me a screenshot 🙂
@aslakr@mastodon.social
This #Unicode technical report (tr58) on non-ASCII characters in urls and email addresses might be relevant for #ActivityPub implementations
unicode.org
UTS #58: Unicode Link Detection and Formatting: URLs and Email Addresses
@mikaeru@mastodon.social · Reply to Michel Mariani
Full members (voting) of the Unicode Consortium (2026-02-25): Amazon, Apple, Meta, Microsoft, Salesforce, Translated.
🔗 https://home.unicode.org/membership/members/
Exit Adobe, Airbnb, Google... Ça sent le roussi !

ALT text
Full members (voting) of the Unicode Consortium (2026-02-25): Amazon, Apple, Meta, Microsoft, Salesforce, Translated.
@mikaeru@mastodon.social
The current version of Unicopedia Sigilla is marked as "alpha", since it relies on #Unicode 18.0-alpha, which is still a draft: assigned code points for Seal characters, as well as their source references and glyphs, may evolve before the final release planned for September 2026.
Consequently, no Unicode-aware font exists yet for Seal characters, at least until the new Seal block gets stable. So, display of characters in the application is "Tōfu Matsuri" for the time being...

mastodon.social
Michel Mariani (@mikaeru@mastodon.social)
Attached: 1 image Unicopedia Sigilla is a developer-oriented set of #Unicode utilities related to Seal characters, wrapped into one single app, built with #Electron. Repository: 🔗 https://codeberg.org/tonton-pixel/unicopedia-sigilla #Unicopedia #Seal #Characters #JavaScript #CodePoints #Glyphs #OpenSource #DesktopApplication
@mikaeru@mastodon.social
Unicopedia Sigilla is a developer-oriented set of #Unicode utilities related to Seal characters, wrapped into one single app, built with #Electron.
Repository: 🔗 https://codeberg.org/tonton-pixel/unicopedia-sigilla
#Unicopedia #Seal #Characters #JavaScript #CodePoints #Glyphs #OpenSource #DesktopApplication
ALT text
Unicopedia Sigilla Social Preview
@mikaeru@mastodon.social
Unicopedia Sigilla is a developer-oriented set of #Unicode utilities related to Seal characters, wrapped into one single app, built with #Electron.
Repository: 🔗 https://codeberg.org/tonton-pixel/unicopedia-sigilla
#Unicopedia #Seal #Characters #JavaScript #CodePoints #Glyphs #OpenSource #DesktopApplication
ALT text
Unicopedia Sigilla Social Preview
@mikaeru@mastodon.social
Unicopedia Sigilla is a developer-oriented set of #Unicode utilities related to Seal characters, wrapped into one single app, built with #Electron.
Repository: 🔗 https://codeberg.org/tonton-pixel/unicopedia-sigilla
#Unicopedia #Seal #Characters #JavaScript #CodePoints #Glyphs #OpenSource #DesktopApplication
ALT text
Unicopedia Sigilla Social Preview
@jordanhipwell@mastodon.world
I just released version 8.0 of UniChar, the Unicode character viewer app I created nearly 12 years ago! Has some big new features. I spent a good amount of time polishing it for iOS 26 ✍︎
https://apps.apple.com/us/app/unichar-unicode-keyboard/id880811847
#iOSDev #IndieDev #Unicode

apps.apple.com
UniChar — Unicode Keyboard App - App Store
Download UniChar — Unicode Keyboard by Jordan Hipwell on the App Store. See screenshots, ratings and reviews, user tips, and more apps like UniChar — Unicode…
@jordanhipwell@mastodon.world
I just released version 8.0 of UniChar, the Unicode character viewer app I created nearly 12 years ago! Has some big new features. I spent a good amount of time polishing it for iOS 26 ✍︎
https://apps.apple.com/us/app/unichar-unicode-keyboard/id880811847
#iOSDev #IndieDev #Unicode
apps.apple.com
UniChar — Unicode Keyboard App - App Store
Download UniChar — Unicode Keyboard by Jordan Hipwell on the App Store. See screenshots, ratings and reviews, user tips, and more apps like UniChar — Unicode…
@leffe@social.linux.pizza
I found this reply that I made in 1984 to Dennis Ritchie in the net.followup newsgroup. I was at the time lobbying Sun to add 8-bit character set support to the firmware, but they wanted to hold out for a 16-bit system, like the as yet unnamed Unicode. There was eventually an interim solution but my memory of that is a bit foggy.
#Usenet #DennisRitchie #C #Pascal #emacs #VT100 #charactersets #ISO8859 #languages #Swedish #programming #unicode #SunMicrosystems #Värmland
![› ... The problem was that, to the Swedes, characters like
› {}|\ were letters, not syntactic symbols.
›
› It's a real problem. I gather that the best-equipped users
› had terminals that would switch graphics depending on
› whether they were writing C or documents.
›
› Dennis Ritchie
That's right, writing C and shell commands is almost impossible on a terminal with a swedish character set. Even Pascal is a bit hard, but some compilers will accept (* *) instead of { } and (. .) instead of [ ].
If you have a terminal with selectable character sets, you can train your editor to switch, depending on what type of text you are editing. I have set up EMACS so that it selects the right character set on my VT100 depending on what mode I'm in (which in turn is controlled by filename suffixes). This works even if I have two windows, one with C code in it and the other holding a document in swedish.
Leif Samuelsson
LM ERICSSON Tel. Co.
S-126 25 STOCKHOLM
SWEDEN
..{decvax, philabs}!mcvax!enea!erix!leif
"E { e }, } i }a { e |"
"It is a river, and in the river there is an island"
(This is a dialect of swedish. My apologies to the people in the
province of V{rmland for the lack of a V{rmland character set).](https://cdn.social.linux.pizza/system/media_attachments/files/116/120/055/788/894/695/original/bb2612902825c1df.png)
ALT text
› ... The problem was that, to the Swedes, characters like › {}|\ were letters, not syntactic symbols. › › It's a real problem. I gather that the best-equipped users › had terminals that would switch graphics depending on › whether they were writing C or documents. › › Dennis Ritchie That's right, writing C and shell commands is almost impossible on a terminal with a swedish character set. Even Pascal is a bit hard, but some compilers will accept (* *) instead of { } and (. .) instead of [ ]. If you have a terminal with selectable character sets, you can train your editor to switch, depending on what type of text you are editing. I have set up EMACS so that it selects the right character set on my VT100 depending on what mode I'm in (which in turn is controlled by filename suffixes). This works even if I have two windows, one with C code in it and the other holding a document in swedish. Leif Samuelsson LM ERICSSON Tel. Co. S-126 25 STOCKHOLM SWEDEN ..{decvax, philabs}!mcvax!enea!erix!leif "E { e }, } i }a { e |" "It is a river, and in the river there is an island" (This is a dialect of swedish. My apologies to the people in the province of V{rmland for the lack of a V{rmland character set).
@blog@shkspr.mobi
Internationalise The Fediverse
https://shkspr.mobi/blog/2024/02/internationalise-the-fediverse/We live in the future now. It is OK to use Unicode everywhere.
It seems bizarre to me that modern Internet services sometimes "forget" that there's a world outside the Anglosphere. Some people have the temerity to speak foreign languages! And some of those languages have accents on their letters!! Even worse, some don't use English letters at all!!!
A decade ago, I was miffed that GitHub only supported some ASCII characters in its project names. There's no technical reason why your repo can't be called "ഹലോ വേൾഡ്".
Similarly, I'm frustrated that Mastodon (the largest ActivityPub service) doesn't allow Unicode usernames and has resisted efforts to change.
So I built a small ActivityPub server which publishes content from an Actor called @你好@i18n.viii.fi - it is only a demo account, but it works!
Some ActivityPub clients report that they are able to follow it and receive messages from it. Others - like Mastodon - simply can't see anything from it. Take a look at the replies on Mastodon to see which services work. You can also see some of its posts on the Fediverse.
What Does The Fox Spec Say?
The ActivityPub specification says:
Building an international base of users is important in a federated network. Internationalization
I can't find anything in the specifications which limits what languages a username can be written in. But there are a few clues scattered about.
The user's @ name is defined by preferredUsername which is:
A short username which may be used to refer to the actor, with no uniqueness guarantees. 4.1 Actor objects
There's nothing in there about what scripts it can contain. However, later on, the spec says:
Properties containing natural language values, such as
name,preferredUsername, orsummary, make use of natural language support defined in ActivityStreams. 4. Actors
So it is expected that a preferred username could be written in multiple scripts. Which implies that the default need not be limited to A-Z0-9.
The ActivityStreams specification talks about language mapping.
Finally, the ActivityPub specification has some examples on non-Latin text in names.
So, I think that it is acceptable for usernames to be written in a variety of non-Latin scripts.
But What About...?
There are usually a few objections to "Unicode Everywhere" zealots like me. I'd like to forestall any arguments.
What about homograph attacks?
Well, what about them? ASCII has plenty of similar looking characters. I doubt most people would notice when a capital i is replaced by a lower L - and vice-versa. Similarly the kerning issue of an r and n looking like an m is well known. Are mixed language homographs more dangerous? I don't think so.
What if people make names that can't be typed?
Well, what if they do? Maybe not being found by people who can't type your language is a feature, not a bug. But, anyway, clients can let users search for other people, or copy and paste their names.
What about weird "Zalgo" text?
It is up to a client to decide how they want to render text input. The "problems" of strange Unicode combinations are well known. This is not a hard computer-science problem.
What about bi-directional text?
The spec makes clear this is allowed.
Do people even want a username in their own script?
I have no evidence for this. But I bet you'd get pretty frustrated if you had to switch keyboard just to type your own name, wouldn't you? In any case, why can't I have a username of @😉
What's Next?
If you build ActivityPub software, give some thought to the billions of people who don't have names which easily fit into ASCII.
If your software can see @你好@i18n.viii.fi and its posts, please let me know.
@blog@shkspr.mobi
Internationalise The Fediverse
https://shkspr.mobi/blog/2024/02/internationalise-the-fediverse/We live in the future now. It is OK to use Unicode everywhere.
It seems bizarre to me that modern Internet services sometimes "forget" that there's a world outside the Anglosphere. Some people have the temerity to speak foreign languages! And some of those languages have accents on their letters!! Even worse, some don't use English letters at all!!!
A decade ago, I was miffed that GitHub only supported some ASCII characters in its project names. There's no technical reason why your repo can't be called "ഹലോ വേൾഡ്".
Similarly, I'm frustrated that Mastodon (the largest ActivityPub service) doesn't allow Unicode usernames and has resisted efforts to change.
So I built a small ActivityPub server which publishes content from an Actor called @你好@i18n.viii.fi - it is only a demo account, but it works!
Some ActivityPub clients report that they are able to follow it and receive messages from it. Others - like Mastodon - simply can't see anything from it. Take a look at the replies on Mastodon to see which services work. You can also see some of its posts on the Fediverse.
What Does The Fox Spec Say?
The ActivityPub specification says:
Building an international base of users is important in a federated network. Internationalization
I can't find anything in the specifications which limits what languages a username can be written in. But there are a few clues scattered about.
The user's @ name is defined by preferredUsername which is:
A short username which may be used to refer to the actor, with no uniqueness guarantees. 4.1 Actor objects
There's nothing in there about what scripts it can contain. However, later on, the spec says:
Properties containing natural language values, such as
name,preferredUsername, orsummary, make use of natural language support defined in ActivityStreams. 4. Actors
So it is expected that a preferred username could be written in multiple scripts. Which implies that the default need not be limited to A-Z0-9.
The ActivityStreams specification talks about language mapping.
Finally, the ActivityPub specification has some examples on non-Latin text in names.
So, I think that it is acceptable for usernames to be written in a variety of non-Latin scripts.
But What About...?
There are usually a few objections to "Unicode Everywhere" zealots like me. I'd like to forestall any arguments.
What about homograph attacks?
Well, what about them? ASCII has plenty of similar looking characters. I doubt most people would notice when a capital i is replaced by a lower L - and vice-versa. Similarly the kerning issue of an r and n looking like an m is well known. Are mixed language homographs more dangerous? I don't think so.
What if people make names that can't be typed?
Well, what if they do? Maybe not being found by people who can't type your language is a feature, not a bug. But, anyway, clients can let users search for other people, or copy and paste their names.
What about weird "Zalgo" text?
It is up to a client to decide how they want to render text input. The "problems" of strange Unicode combinations are well known. This is not a hard computer-science problem.
What about bi-directional text?
The spec makes clear this is allowed.
Do people even want a username in their own script?
I have no evidence for this. But I bet you'd get pretty frustrated if you had to switch keyboard just to type your own name, wouldn't you? In any case, why can't I have a username of @😉
What's Next?
If you build ActivityPub software, give some thought to the billions of people who don't have names which easily fit into ASCII.
If your software can see @你好@i18n.viii.fi and its posts, please let me know.
@blog@shkspr.mobi
Internationalise The Fediverse
https://shkspr.mobi/blog/2024/02/internationalise-the-fediverse/We live in the future now. It is OK to use Unicode everywhere.
It seems bizarre to me that modern Internet services sometimes "forget" that there's a world outside the Anglosphere. Some people have the temerity to speak foreign languages! And some of those languages have accents on their letters!! Even worse, some don't use English letters at all!!!
A decade ago, I was miffed that GitHub only supported some ASCII characters in its project names. There's no technical reason why your repo can't be called "ഹലോ വേൾഡ്".
Similarly, I'm frustrated that Mastodon (the largest ActivityPub service) doesn't allow Unicode usernames and has resisted efforts to change.
So I built a small ActivityPub server which publishes content from an Actor called @你好@i18n.viii.fi - it is only a demo account, but it works!
Some ActivityPub clients report that they are able to follow it and receive messages from it. Others - like Mastodon - simply can't see anything from it. Take a look at the replies on Mastodon to see which services work. You can also see some of its posts on the Fediverse.
What Does The Fox Spec Say?
The ActivityPub specification says:
Building an international base of users is important in a federated network. Internationalization
I can't find anything in the specifications which limits what languages a username can be written in. But there are a few clues scattered about.
The user's @ name is defined by preferredUsername which is:
A short username which may be used to refer to the actor, with no uniqueness guarantees. 4.1 Actor objects
There's nothing in there about what scripts it can contain. However, later on, the spec says:
Properties containing natural language values, such as
name,preferredUsername, orsummary, make use of natural language support defined in ActivityStreams. 4. Actors
So it is expected that a preferred username could be written in multiple scripts. Which implies that the default need not be limited to A-Z0-9.
The ActivityStreams specification talks about language mapping.
Finally, the ActivityPub specification has some examples on non-Latin text in names.
So, I think that it is acceptable for usernames to be written in a variety of non-Latin scripts.
But What About...?
There are usually a few objections to "Unicode Everywhere" zealots like me. I'd like to forestall any arguments.
What about homograph attacks?
Well, what about them? ASCII has plenty of similar looking characters. I doubt most people would notice when a capital i is replaced by a lower L - and vice-versa. Similarly the kerning issue of an r and n looking like an m is well known. Are mixed language homographs more dangerous? I don't think so.
What if people make names that can't be typed?
Well, what if they do? Maybe not being found by people who can't type your language is a feature, not a bug. But, anyway, clients can let users search for other people, or copy and paste their names.
What about weird "Zalgo" text?
It is up to a client to decide how they want to render text input. The "problems" of strange Unicode combinations are well known. This is not a hard computer-science problem.
What about bi-directional text?
The spec makes clear this is allowed.
Do people even want a username in their own script?
I have no evidence for this. But I bet you'd get pretty frustrated if you had to switch keyboard just to type your own name, wouldn't you? In any case, why can't I have a username of @😉
What's Next?
If you build ActivityPub software, give some thought to the billions of people who don't have names which easily fit into ASCII.
If your software can see @你好@i18n.viii.fi and its posts, please let me know.
@blog@shkspr.mobi
Internationalise The Fediverse
https://shkspr.mobi/blog/2024/02/internationalise-the-fediverse/We live in the future now. It is OK to use Unicode everywhere.
It seems bizarre to me that modern Internet services sometimes "forget" that there's a world outside the Anglosphere. Some people have the temerity to speak foreign languages! And some of those languages have accents on their letters!! Even worse, some don't use English letters at all!!!
A decade ago, I was miffed that GitHub only supported some ASCII characters in its project names. There's no technical reason why your repo can't be called "ഹലോ വേൾഡ്".
Similarly, I'm frustrated that Mastodon (the largest ActivityPub service) doesn't allow Unicode usernames and has resisted efforts to change.
So I built a small ActivityPub server which publishes content from an Actor called @你好@i18n.viii.fi - it is only a demo account, but it works!
Some ActivityPub clients report that they are able to follow it and receive messages from it. Others - like Mastodon - simply can't see anything from it. Take a look at the replies on Mastodon to see which services work. You can also see some of its posts on the Fediverse.
What Does The Fox Spec Say?
The ActivityPub specification says:
Building an international base of users is important in a federated network. Internationalization
I can't find anything in the specifications which limits what languages a username can be written in. But there are a few clues scattered about.
The user's @ name is defined by preferredUsername which is:
A short username which may be used to refer to the actor, with no uniqueness guarantees. 4.1 Actor objects
There's nothing in there about what scripts it can contain. However, later on, the spec says:
Properties containing natural language values, such as
name,preferredUsername, orsummary, make use of natural language support defined in ActivityStreams. 4. Actors
So it is expected that a preferred username could be written in multiple scripts. Which implies that the default need not be limited to A-Z0-9.
The ActivityStreams specification talks about language mapping.
Finally, the ActivityPub specification has some examples on non-Latin text in names.
So, I think that it is acceptable for usernames to be written in a variety of non-Latin scripts.
But What About...?
There are usually a few objections to "Unicode Everywhere" zealots like me. I'd like to forestall any arguments.
What about homograph attacks?
Well, what about them? ASCII has plenty of similar looking characters. I doubt most people would notice when a capital i is replaced by a lower L - and vice-versa. Similarly the kerning issue of an r and n looking like an m is well known. Are mixed language homographs more dangerous? I don't think so.
What if people make names that can't be typed?
Well, what if they do? Maybe not being found by people who can't type your language is a feature, not a bug. But, anyway, clients can let users search for other people, or copy and paste their names.
What about weird "Zalgo" text?
It is up to a client to decide how they want to render text input. The "problems" of strange Unicode combinations are well known. This is not a hard computer-science problem.
What about bi-directional text?
The spec makes clear this is allowed.
Do people even want a username in their own script?
I have no evidence for this. But I bet you'd get pretty frustrated if you had to switch keyboard just to type your own name, wouldn't you? In any case, why can't I have a username of @😉
What's Next?
If you build ActivityPub software, give some thought to the billions of people who don't have names which easily fit into ASCII.
If your software can see @你好@i18n.viii.fi and its posts, please let me know.
@mikaeru@mastodon.social
All documents published by the Ideographic Research Group (IRG) are now available on the Unicode web site, and can be easily and efficiently found through the new search bar provided on the IRG homepage.
🔗 https://www.unicode.org/irg/
This long-awaited search feature is very convenient, and so useful to find what you're interested in, and even more (ah, the wonderful power of serendipity!)...
#Unicode #IRG #IdeographicResearchGroup #CJK #Ideographs #Unihan

ALT text
Screenshot of the IRG home page, looking for "taboo" from the search bar

ALT text
Screenshot of list of search results in the IRG documents
@SnoopJ@hachyderm.io
Whoa, I just noticed:
#Unicode Technical Standard #58 was published two weeks ago!
Unicode Link Detection and Formatting:
URLs and Email Addresses
https://www.unicode.org/reports/tr58/
---
【This document specifies two consistent, standardized mechanisms that address [URL] problems, consisting of:
1 )link detection: detecting URLs and email addresses embedded in plain text that properly handles non-ASCII characters, and
2) minimally escaping: minimal escaping of non-ASCII code points in the Path, Query, and Fragment portions of a URL.】
unicode.org
UTS #58: Unicode Link Detection and Formatting: URLs and Email Addresses
@mikaeru@mastodon.social
All documents published by the Ideographic Research Group (IRG) are now available on the Unicode web site, and can be easily and efficiently found through the new search bar provided on the IRG homepage.
🔗 https://www.unicode.org/irg/
This long-awaited search feature is very convenient, and so useful to find what you're interested in, and even more (ah, the wonderful power of serendipity!)...
#Unicode #IRG #IdeographicResearchGroup #CJK #Ideographs #Unihan
ALT text
Screenshot of the IRG home page, looking for "taboo" from the search bar
ALT text
Screenshot of list of search results in the IRG documents
@mikaeru@mastodon.social
All documents published by the Ideographic Research Group (IRG) are now available on the Unicode web site, and can be easily and efficiently found through the new search bar provided on the IRG homepage.
🔗 https://www.unicode.org/irg/
This long-awaited search feature is very convenient, and so useful to find what you're interested in, and even more (ah, the wonderful power of serendipity!)...
#Unicode #IRG #IdeographicResearchGroup #CJK #Ideographs #Unihan
ALT text
Screenshot of the IRG home page, looking for "taboo" from the search bar
ALT text
Screenshot of list of search results in the IRG documents
@jspath55@chaos.social
Red Dot of the day.
🔴
Could not show this in #Python with #Unicode '\u' escape codes and ended up pasting it from https://www.compart.com/en/unicode/U+1F534
compart.com
Unicode
U+1F534 is the unicode hex value of the character Large Red Circle. Char U+1F534, Encodings, HTML Entitys:🔴,🔴, UTF-8 (hex), UTF-16 (hex), UTF-32 (hex)
@mikaeru@mastodon.social
All Tangut-related utilities and sample scripts have been moved from 'Unicopedia Sinica' to a new dedicated application: 'Unicopedia Tangutica'

ALT text
Screenshot of the Tangut Components utility of the Unicopedia Tangutica application
@mikaeru@mastodon.social · Reply to Michel Mariani
For the record, the icon of the new #Unicopedia #Tangutica application shows the #Tangut #ideograph U+173C7 𗏇 meaning "written character".

ALT text
Icon of the Unicopedia Tangutica application, with the Tangut ideograph U+173C7 𗏇 meaning "written character"
@mikaeru@mastodon.social
All Tangut-related utilities and sample scripts have been moved from 'Unicopedia Sinica' to a new dedicated application: 'Unicopedia Tangutica'
ALT text
Screenshot of the Tangut Components utility of the Unicopedia Tangutica application
@unwirehk_mirror@mastodon.hongkongers.net
跨性別專屬中文代名詞「X也」 正式納入 Unicode 系統
由跨性別社群自創的中文代名詞「X也」在 2025 年 9 月正式獲統一碼(Unicode)批准納入 Unico […]
#社交網絡 #科技新聞 #LGBTQ #Unicode
https://unwire.hk/2026/02/11/x-unicode/fun-tech/?utm_source=rss&utm_medium=rss&utm_campaign=x-unicode
@mikaeru@mastodon.social · Reply to Michel Mariani
Full members (voting) of the Unicode Consortium (2026-02-08): Adobe, Airbnb, Amazon, Apple, Google, Meta, Microsoft, Salesforce, Translated.
🔗 https://home.unicode.org/membership/members/
Salesforce is back, once again... on and off, and on and off, and on... Part-time member, possibly?

ALT text
Full members (voting) of the Unicode Consortium (2026-02-08): Adobe, Airbnb, Amazon, Apple, Google, Meta, Microsoft, Salesforce, Translated.
@mikaeru@mastodon.social · Reply to Michel Mariani
Full members (voting) of the Unicode Consortium (2026-01-25): Adobe, Airbnb, Amazon, Apple, Google, Meta, Microsoft, Translated.
🔗 https://home.unicode.org/membership/members/
Salesforce is gone, once again... on and off and on and off...
Some avatar of #Schrödinger's cat, perhaps?

ALT text
Full members (voting) of the Unicode Consortium (2026-01-25): Adobe, Airbnb, Amazon, Apple, Google, Meta, Microsoft, Translated.
@mikaeru@mastodon.social · Reply to Michel Mariani
Full members (voting) of the Unicode Consortium (2026-02-08): Adobe, Airbnb, Amazon, Apple, Google, Meta, Microsoft, Salesforce, Translated.
🔗 https://home.unicode.org/membership/members/
Salesforce is back, once again... on and off, and on and off, and on... Part-time member, possibly?
ALT text
Full members (voting) of the Unicode Consortium (2026-02-08): Adobe, Airbnb, Amazon, Apple, Google, Meta, Microsoft, Salesforce, Translated.
@ada@catcatnya.com · Reply to Aada is kitty :blobCat_verified_badge:
does #Unicode or someone have tables of similar-looking characters somewhere? Since that particular code is in a way dealing with typesetting that could be quite handy.
@saadat@saadatmand.pk
New blog post, in which I geek out over Urdu digits, Unicode, and CSS counter styles: https://saadatmand.pk/blog/of-urdu-digits-and-css-counter-styles/

saadatmand.pk
Of Urdu digits and CSS counter styles
Imagine a numbered list in Urdu. How will you implement it in HTML and CSS?
@saadat@saadatmand.pk
New blog post, in which I geek out over Urdu digits, Unicode, and CSS counter styles: https://saadatmand.pk/blog/of-urdu-digits-and-css-counter-styles/
saadatmand.pk
Of Urdu digits and CSS counter styles
Imagine a numbered list in Urdu. How will you implement it in HTML and CSS?
@w3c@w3c.social · Reply to :blobcatverified2:
@Jain We'd love to have you, Jain!
https://www.w3.org/membership/
For Emoji standardization however, you'll have to rely on the #unicode consortium :blobcat3c:
https://home.unicode.org/emoji/about-emoji/
home.unicode.org
About Emoji
About Emoji 92% of the world’s online population use emoji in their communications – and Unicode defines the characters that make those human connections possible. These 3,600+ emoji represent faces, weather, vehicles
@calvin@fedi.sphericalcow.space
What's the difference between ☄ and ☄️?
The hexcodes start the same but the latter is longer:
☄: e2 98 84
☄️: e2 98 84 ef b8 8f
Are both considered to be "emoji"?
fedi.sphericalcow.space
Pleroma
@jdlh@mstdn.ca · Reply to Mike Williamson
@sleepycat this paper doesn't cite two relevant official #Unicode reports on the subject: "Unicode Security Mechanisms" https://unicode.org/reports/tr39/ and "Unicode Identifiers and Syntax" https://www.unicode.org/reports/tr31/ . Was the paper interested in solving problems, or just in collecting the engagement from pointing them out?
unicode.org
UAX #31: Unicode Identifiers and Syntax
@mikaeru@mastodon.social · Reply to Michel Mariani
Full members (voting) of the Unicode Consortium (2026-01-25): Adobe, Airbnb, Amazon, Apple, Google, Meta, Microsoft, Translated.
🔗 https://home.unicode.org/membership/members/
Salesforce is gone, once again... on and off and on and off...
Some avatar of #Schrödinger's cat, perhaps?
ALT text
Full members (voting) of the Unicode Consortium (2026-01-25): Adobe, Airbnb, Amazon, Apple, Google, Meta, Microsoft, Translated.
@sleepycat@infosec.exchange
"Rather than inserting logical bugs, adversaries can attack the encoding of source code files to inject vulnerabilities.
These adversarial encodings produce no visual artifacts.
The trick is to use Unicode control characters to reorder tokens in source code at the encoding level."
trojansource.codes
Trojan Source Attacks
Some vulnerabilities are invisible. Rather than inserting logical bugs, adversaries can attack the encoding of source code files to inject vulnerabilities.
@blog@shkspr.mobi
A small collection of text-only websites
https://shkspr.mobi/blog/2025/12/a-small-collection-of-text-only-websites/A couple of years ago, I started serving my blog posts as plain text. Add .txt to the end of any URl and get a deliciously lo-fi, UTF-8, mono[chrome|space] alternative.
Here's this post in plain text - https://shkspr.mobi/blog/2025/12/a-small-collection-of-text-only-websites.txt
Obviously a webpage without links is like a fish without a bicycle, but the joy of the web is that there are no gatekeepers. People can try new concepts and, if enough people join in, it becomes normal. I'm not saying the plain-text is the best web experience. But it is an experience. Perfect if you like your browsing fast, simple, and readable. There are no cookie banners, pop-ups, permission prompts, autoplaying videos, or garish colour schemes.
I'm certainly not the first person to do this, so I thought it might be fun to gather a list of websites which you browse in text-only mode. If you know of any more - including your own site - please drop a comment in the box!
- Terence Eden's blog - add
.txtto any URl. - Daring Fireball - add
.textto any URl. - Zach Flowers - replace
.htmlwith.txt. - Fabien Benetou's PIM - add
?action=sourceto any URl. - M0YNG - add
.txtto any URl. - Gwern - add
.mdto any URl or send an HTTP Accept for Markdown. - Dan Q's textplain.blog - the entire blog is plain text!
- Matt Hobbs - there is a feed of plaintext which allows you to read recent posts.
If you'd like to add a site, please get in touch. The rules are simple - content which has the MIME type of text/plain. No HTML, no multimedia, no RTF, no XML, no ANSI colour escape sequences.
Emoji are fine though; emoji are cool.
#blogging #blogs #text #unicode #utf8@shaft@piaille.fr
#Unicode 18.0 will add at least 13,000 characters.
“At UTC #185, nearly 13,000 additional characters were approved for encoding in Unicode 18.0.
The approved additions include encoding of Small Seal script ("Seal"), a repertoire of 11,328 ideographic characters. Seal is distinct from modern Han ideographs (aka, "CJK"), but is an important precursor of CJK resulting from the first efforts to standardize writing across Chinese-speaking regions during China's Qin Dynasty. As such, Seal has important cultural significance in China and for Chinese speakers throughout the world”
https://blog.unicode.org/2025/12/utc-185-highlights.html?m=1
More on seal script: https://en.wikipedia.org/wiki/Seal_script
en.wikipedia.org
Seal script - Wikipedia
@xChaos@f.cz
@xChaos@f.cz
@xChaos@f.cz
@mikaeru@mastodon.social
The latest version of the open-source application "Unicopedia Plus" is now available, adding support for all the new characters, scripts, and blocks defined in Unicode 17.0.
🔗 https://codeberg.org/tonton-pixel/unicopedia-plus
This current app version is a pre-release (Beta), since full support for Unicode 17.0 is not yet available in the Electron framework. More specifically, results from the "Unicode Foldings", "Unicode Normalizer", and "Unicode Segmenter" utilities cannot be fully trusted...

ALT text
Unicopedia Plus application screenshot
@Jay16K@chaos.social
Was da wohl schon so kaputt gegangen ist, Unicode ist aber in Ordnung? 😬
#MaliciousCompliance #Unicode

ALT text
Screenshot einer Bestellwebsite: "Zusätzliche Bemerkungen (bitte keine Emojis verwenden):" darunter ein leeres Eingabefeld
@kagan@wandering.shop
Fun tip for anyone who's wondering how I got the "hashtags" in my last toot to not be *actual* hashtags: after the # symbol, and before the next letter, I put a Unicode Word Joiner character. That breaks up the string so it no longer counts as a hashtag, but also makes it so there can't be a line-break after the # symbol.
https://unicode-explorer.com/c/2060
You can type one in Linux Mint by doing Ctrl+Shift+U then "2060" and Enter.
unicode-explorer.com
U+2060 WORD JOINER - Unicode Explorer
U+2060 WORD JOINER, copy and paste, unicode character symbol info, commonly abbreviated WJ, a zero width non-breaking space (only), intended for disambiguation of functions for byte order mark
@pandoc@fosstodon.org
Off-label uses of pandoc: conversion between text encodings.
E.g., UTF-8 to UTF-16:
echo 'X' | pandoc lua -e 'io.write(pandoc.text.toencoding(io.read"a", "utf-16"))'
Other direction:
echo 'X' | pandoc lua -e 'io.write(pandoc.text.fromencoding(io.read"a", "utf-16"))'
The set of supported encodings is platform dependent, but always includes UTF-8, UTF-16, UTF-32, and latin1.
@pandoc@fosstodon.org
Off-label uses of pandoc: conversion between text encodings.
E.g., UTF-8 to UTF-16:
echo 'X' | pandoc lua -e 'io.write(pandoc.text.toencoding(io.read"a", "utf-16"))'
Other direction:
echo 'X' | pandoc lua -e 'io.write(pandoc.text.fromencoding(io.read"a", "utf-16"))'
The set of supported encodings is platform dependent, but always includes UTF-8, UTF-16, UTF-32, and latin1.

@PurpleJillybeans@kind.social · Reply to jenny
@Marmalade Wouldn't surprise me if it were floating around somewhere in #Unicode already. @codepoints
@mikaeru@mastodon.social
New in Unicopedia Sinica:
- Added new Tangut Inspector utility.
- Added new Tangut Data Finder utility.

ALT text
Unicopedia Sinica - Tangut Inspector utility screenshot

ALT text
Unicopedia Sinica - Tangut Data Finder utility screenshot
@mikaeru@mastodon.social
New in Unicopedia Sinica:
- Added new Tangut Inspector utility.
- Added new Tangut Data Finder utility.
ALT text
Unicopedia Sinica - Tangut Inspector utility screenshot
ALT text
Unicopedia Sinica - Tangut Data Finder utility screenshot
@mikaeru@mastodon.social
There is a very interesting article about gender-inclusive pronouns in Chinese, including mentions of characters yet to be added to the Unicode set, making use of Ideographic Description Sequences (IDS): ⿰无也, ⿰㐅也, ⿰男也...
Janet Davey. (2025). Taking "TA" Beyond the Binary: In Search of Multimodal Gender-inclusive Pronouns in Chinese. Image & Narrative, 25(03), 131–163. Retrieved from https://imageandnarrative.be/index.php/imagenarrative/article/view/3417
🔗 [PDF] https://imageandnarrative.be/index.php/imagenarrative/article/view/3417/2829
imageandnarrative.be
View of Taking "TA" Beyond the Binary
@mikaeru@mastodon.social
Unicode 17.0 introduces five new CJK Unified Ideographs related to Chinese personal pronouns, four of them having been proposed by Andrew West (BabelStone):
« The other Chinese pronoun coming to Unicode v. 17.0 next year, in addition to ⿰㐅也 (3p gender-neutral, ⿰男也 (3p explicitly male), ⿱妳心 ( f. equivalent of 您), ⿱我心 (Taiwanese 1p plural), is ⿱她心 (f. equivalent to 怹) »
🔗 https://bsky.app/profile/babelstone.co.uk/post/3lbrxowqt7k24
ALT text
Screenshot of CJK Related data from Unicopedia Sinica: Chinese Personal Pronouns
@sir_pepe@mastodon.social
No matter how badly you screw up at work, at least your silly mistake won't be absolutely IMMORTALIZED in the #Unicode specification. Unless you work at Unicode, in which case, good luck. We're all counting on you.

ALT text
FE18 PRESENTATION FORM FOR VERTICAL RIGHT WHITE LENTICULAR BRAKCET
@mikaeru@mastodon.social
The latest version of the open-source application "Unicopedia Sinica" is now available, adding support for all the new CJK/Unihan characters defined in Unicode 17.0.
ALT text
Screenshot of the open-source application Unicopedia Sinica v.17.0.0
@mikaeru@mastodon.social
New in Unicopedia Sinica:
- Added new Tangut Components utility.
- Added new Tangut References utility.

ALT text
Screenshot of Unicopedia Sinica app: Look Up IDS feature of Tangut Components utility
@mikaeru@mastodon.social
New in Unicopedia Sinica:
- Added new Tangut Components utility.
- Added new Tangut References utility.
ALT text
Screenshot of Unicopedia Sinica app: Look Up IDS feature of Tangut Components utility
@sir_pepe@mastodon.social
No matter how badly you screw up at work, at least your silly mistake won't be absolutely IMMORTALIZED in the #Unicode specification. Unless you work at Unicode, in which case, good luck. We're all counting on you.
ALT text
FE18 PRESENTATION FORM FOR VERTICAL RIGHT WHITE LENTICULAR BRAKCET
@blog@shkspr.mobi
A small collection of text-only websites
https://shkspr.mobi/blog/2025/12/a-small-collection-of-text-only-websites/A couple of years ago, I started serving my blog posts as plain text. Add .txt to the end of any URl and get a deliciously lo-fi, UTF-8, mono[chrome|space] alternative.
Here's this post in plain text - https://shkspr.mobi/blog/2025/12/a-small-collection-of-text-only-websites.txt
Obviously a webpage without links is like a fish without a bicycle, but the joy of the web is that there are no gatekeepers. People can try new concepts and, if enough people join in, it becomes normal. I'm not saying the plain-text is the best web experience. But it is an experience. Perfect if you like your browsing fast, simple, and readable. There are no cookie banners, pop-ups, permission prompts, autoplaying videos, or garish colour schemes.
I'm certainly not the first person to do this, so I thought it might be fun to gather a list of websites which you browse in text-only mode. If you know of any more - including your own site - please drop a comment in the box!
- Terence Eden's blog - add
.txtto any URl. - Daring Fireball - add
.textto any URl. - Zach Flowers - replace
.htmlwith.txt. - Fabien Benetou's PIM - add
?action=sourceto any URl. - M0YNG - add
.txtto any URl. - Gwern - add
.mdto any URl or send an HTTP Accept for Markdown. - Dan Q's textplain.blog - the entire blog is plain text!
- Matt Hobbs - there is a feed of plaintext which allows you to read recent posts.
If you'd like to add a site, please get in touch. The rules are simple - content which has the MIME type of text/plain. No HTML, no multimedia, no RTF, no XML, no ANSI colour escape sequences.
Emoji are fine though; emoji are cool.
#blogging #blogs #text #unicode #utf8@blog@shkspr.mobi
A small collection of text-only websites
https://shkspr.mobi/blog/2025/12/a-small-collection-of-text-only-websites/A couple of years ago, I started serving my blog posts as plain text. Add .txt to the end of any URl and get a deliciously lo-fi, UTF-8, mono[chrome|space] alternative.
Here's this post in plain text - https://shkspr.mobi/blog/2025/12/a-small-collection-of-text-only-websites.txt
Obviously a webpage without links is like a fish without a bicycle, but the joy of the web is that there are no gatekeepers. People can try new concepts and, if enough people join in, it becomes normal. I'm not saying the plain-text is the best web experience. But it is an experience. Perfect if you like your browsing fast, simple, and readable. There are no cookie banners, pop-ups, permission prompts, autoplaying videos, or garish colour schemes.
I'm certainly not the first person to do this, so I thought it might be fun to gather a list of websites which you browse in text-only mode. If you know of any more - including your own site - please drop a comment in the box!
- Terence Eden's blog - add
.txtto any URl. - Daring Fireball - add
.textto any URl. - Zach Flowers - replace
.htmlwith.txt. - Fabien Benetou's PIM - add
?action=sourceto any URl. - M0YNG - add
.txtto any URl. - Gwern - add
.mdto any URl or send an HTTP Accept for Markdown. - Dan Q's textplain.blog - the entire blog is plain text!
- Matt Hobbs - there is a feed of plaintext which allows you to read recent posts.
If you'd like to add a site, please get in touch. The rules are simple - content which has the MIME type of text/plain. No HTML, no multimedia, no RTF, no XML, no ANSI colour escape sequences.
Emoji are fine though; emoji are cool.
#blogging #blogs #text #unicode #utf8@timotimo@peoplemaking.games
It was the best of times, it was the

ALT text
Screenshot of a unicode information website showing an image (empty) of the character called "INVISIBLE TIMES", which is codepoint U+2062
@timotimo@peoplemaking.games
It was the best of times, it was the
ALT text
Screenshot of a unicode information website showing an image (empty) of the character called "INVISIBLE TIMES", which is codepoint U+2062
@mikaeru@mastodon.social · Reply to Michel Mariani
Full members (voting) of the Unicode Consortium (2025-12-24): Adobe, Airbnb, Amazon, Apple, Google, Meta, Microsoft, Salesforce, Translated.
https://home.unicode.org/membership/members/
Salesforce is back, as if by magic, just in time for Christmas... A true miracle!

ALT text
Full members (voting) of the Unicode Consortium (2025-12-24): Adobe, Airbnb, Amazon, Apple, Google, Meta, Microsoft, Salesforce, Translated.
@mikaeru@mastodon.social · Reply to Michel Mariani
Today (April Fools' Day), Adobe is apparently back to the list of full members (voting) of the Unicode Consortium, but for how long this time: one full year?
« Ça s’en va et ça revient
C’est fait de tout petits riens
Ça se chante et ça se danse
Et ça revient, ça se retient
Comme une chanson populaire »
Full members (voting) of the Unicode Consortium: Adobe, Airbnb, Amazon, Apple, Google, Meta, Microsoft, Salesforce, Translated.

ALT text
Full members (voting) of the Unicode Consortium: Adobe, Airbnb, Amazon, Apple, Google, Meta, Microsoft, Salesforce, Translated.
@mikaeru@mastodon.social · Reply to Michel Mariani
Full members (voting) of the Unicode Consortium (2025-12-24): Adobe, Airbnb, Amazon, Apple, Google, Meta, Microsoft, Salesforce, Translated.
https://home.unicode.org/membership/members/
Salesforce is back, as if by magic, just in time for Christmas... A true miracle!
ALT text
Full members (voting) of the Unicode Consortium (2025-12-24): Adobe, Airbnb, Amazon, Apple, Google, Meta, Microsoft, Salesforce, Translated.

@reiver@mastodon.social · Reply to @reiver ⊼ (Charles) :batman:
This probably means that someone should modernize HTTP by creating HTTP/1.4.
mastodon.social
@reiver ⊼ (Charles) :batman: (@reiver@mastodon.social)
Google more-or-less created 2 new versions of the HTTP protocol — HTTP/2 and HTTP/3 — But didn't bother make either of them (officially) support UTF-8 in the HTTP request. #HTTP #Unicode #UTF8 #WorldWideWeb
@reiver@mastodon.social
Google more-or-less created 2 new versions of the HTTP protocol — HTTP/2 and HTTP/3 —
But didn't bother make either of them (officially) support UTF-8 in the HTTP request.
@SnoopJ@hachyderm.io
the most important part of #Unicode history is when a mouse fell out of a light fixture and got added to the count of members present at a Technical Committee meeting (9 Nov 2016)
![Screenshot of meeting notes for UTC Meeting 149. Text reads:
Mouse now present. 6.502 members represented.
[149-A94] Action Item for Landlord: Capture and exile the mouse that just fell out of the light fixture.](https://media.hachyderm.io/media_attachments/files/109/920/998/412/413/368/original/184121b17961bc57.png)
ALT text
Screenshot of meeting notes for UTC Meeting 149. Text reads: Mouse now present. 6.502 members represented. [149-A94] Action Item for Landlord: Capture and exile the mouse that just fell out of the light fixture.
@mikaeru@mastodon.social
Generally, new CJK Ideographs proposed by members of the IRG (Ideographic Research Group) go through several rounds of exchanges/discussions until they get approved or possibly postponed or rejected.
For instance, here is the page dedicated to UK-20538 ⿰㐅也 (with images as "pieces of evidence"), which eventually made its way to Unicode 17.0, encoded as U+323BF :
hc.jsecs.org
00029 | ⿰㐅也 | WS2021v7.0
@mikaeru@mastodon.social
Unicode 17.0 introduces five new CJK Unified Ideographs related to Chinese personal pronouns, four of them having been proposed by Andrew West (BabelStone):
« The other Chinese pronoun coming to Unicode v. 17.0 next year, in addition to ⿰㐅也 (3p gender-neutral, ⿰男也 (3p explicitly male), ⿱妳心 ( f. equivalent of 您), ⿱我心 (Taiwanese 1p plural), is ⿱她心 (f. equivalent to 怹) »
🔗 https://bsky.app/profile/babelstone.co.uk/post/3lbrxowqt7k24
ALT text
Screenshot of CJK Related data from Unicopedia Sinica: Chinese Personal Pronouns
@DoctorG_1@vivaldi.net
@amake@mastodon.social
I see various #JavaScript and #Dart libraries offering functions for detecting #Japanese kanji characters, but they almost always do this in a limited way that misses a huge number of characters, i.e. nothing beyond the #Unicode BMP, or even missing ranges in the BMP.
The only way to do this right is to
1. Work with codepoints, not UTF-16 code units
2. Look at the Unicode script property, which should be `Han` for kanji/hanzi
@amake@mastodon.social · Reply to Aaron “#e14n pro” Madlon-Kay
I used the new Unicode script matchers in Orgro (https://orgro.org/) to improve text reflow for Japanese and Chinese text.
Previously all text would reflow like the Latin text above—with a space where line breaks were. Now I remove the space when appropriate based on the script of the abutting non-whitespace characters.
ALT text
Screen capture of Orgro demonstrating text reflow that correctly handles spaces between Japanese and Chinese characters
@amake@mastodon.social · Reply to Aaron “#e14n pro” Madlon-Kay
I used the new Unicode script matchers in Orgro (https://orgro.org/) to improve text reflow for Japanese and Chinese text.
Previously all text would reflow like the Latin text above—with a space where line breaks were. Now I remove the space when appropriate based on the script of the abutting non-whitespace characters.
ALT text
Screen capture of Orgro demonstrating text reflow that correctly handles spaces between Japanese and Chinese characters
@amake@mastodon.social
I see various #JavaScript and #Dart libraries offering functions for detecting #Japanese kanji characters, but they almost always do this in a limited way that misses a huge number of characters, i.e. nothing beyond the #Unicode BMP, or even missing ranges in the BMP.
The only way to do this right is to
1. Work with codepoints, not UTF-16 code units
2. Look at the Unicode script property, which should be `Han` for kanji/hanzi
@TheKeystoneCollective@infosec.exchange
Unicode isn't a standard. It's a geopolitical fever dream where linguistics, cyber warfare, influence ops, censorship, OSINT, and national identity all collide.
Homoglyph attacks, script politics, emoji diplomacy, etc.
"The Geopolitics of Unicode: How Scripts, Fonts, and Character Sets Become Cybersecurity Issues"
New read at:
https://www.keystone-collective.org/the-geopolitics-of-unicode-how-scripts-fonts-and-character-sets-become-cybersecurity-issues/ #politics #geopolitics #technology #unicode #cybersecurity #osint #diplomacy

@mikaeru@mastodon.social
Unicode Emoji: Pan-CJK Flags
• <U+1F1E8, U+1F1F3> flag: China [CN]
• <U+1F1ED, U+1F1F0> flag: Hong Kong SAR China [HK]
• <U+1F1EF, U+1F1F5> flag: Japan [JP]
• <U+1F1F0, U+1F1F5> flag: North Korea [KP]
• <U+1F1F0, U+1F1F7> flag: South Korea [KR]
• <U+1F1F2, U+1F1F4> flag: Macao SAR China [MO]
• <U+1F1F2, U+1F1FE> flag: Malaysia [MY]
• <U+1F1F8, U+1F1EC> flag: Singapore [SG]
• <U+1F1F9, U+1F1FC> flag: Taiwan [TW]
• <U+1F1FB, U+1F1F3> flag: Vietnam [VN]
ALT text
Unicode Emoji: Pan-CJK Flags 🇨🇳🇭🇰🇯🇵🇰🇵🇰🇷🇲🇴🇲🇾🇸🇬🇹🇼🇻🇳
@mikaeru@mastodon.social
The latest post on the Unicode Blog gives some important details about the future character repertoire in Unicode 18.0, notably the addition of 11,328 "Small Seal" ideographic characters, plus 965 "Jurchen" characters and radicals . It also offers very clear insights about the work of the UTC (Unicode Technical Committee) on CJK & Unihan characters, in collaboration with the IRG (Ideographic Research Group).

blog.unicode.org
UTC #185 Highlights
Unicode Technical Committee meeting #185 was held October 27 – 29 in Cupertino, CA, hosted by Apple. Here are some highlights. Starting th...
@mikaeru@mastodon.social
The Ideographic Research Group (IRG) is responsible for preparing and reviewing sets of CJK unified ideographs to be included in the Unicode Standard.
It has recently made available a useful list of so-called disunified CJK ideographs, coming with images of glyphs and IRG source references, which also provides links to documents giving the rationale behind each disunification:
unicode.org
IRG Disunified Ideographs
@TheKeystoneCollective@infosec.exchange
Unicode isn't a standard. It's a geopolitical fever dream where linguistics, cyber warfare, influence ops, censorship, OSINT, and national identity all collide.
Homoglyph attacks, script politics, emoji diplomacy, etc.
"The Geopolitics of Unicode: How Scripts, Fonts, and Character Sets Become Cybersecurity Issues"
New read at:
https://www.keystone-collective.org/the-geopolitics-of-unicode-how-scripts-fonts-and-character-sets-become-cybersecurity-issues/ #politics #geopolitics #technology #unicode #cybersecurity #osint #diplomacy
@scy@chaos.social
@scy@chaos.social
@mikaeru@mastodon.social
Unicode 17.0 introduces five new CJK Unified Ideographs related to Chinese personal pronouns, four of them having been proposed by Andrew West (BabelStone):
« The other Chinese pronoun coming to Unicode v. 17.0 next year, in addition to ⿰㐅也 (3p gender-neutral, ⿰男也 (3p explicitly male), ⿱妳心 ( f. equivalent of 您), ⿱我心 (Taiwanese 1p plural), is ⿱她心 (f. equivalent to 怹) »
🔗 https://bsky.app/profile/babelstone.co.uk/post/3lbrxowqt7k24
ALT text
Screenshot of CJK Related data from Unicopedia Sinica: Chinese Personal Pronouns
@mikaeru@mastodon.social
Unicode 17.0 introduces five new CJK Unified Ideographs related to Chinese personal pronouns, four of them having been proposed by Andrew West (BabelStone):
« The other Chinese pronoun coming to Unicode v. 17.0 next year, in addition to ⿰㐅也 (3p gender-neutral, ⿰男也 (3p explicitly male), ⿱妳心 ( f. equivalent of 您), ⿱我心 (Taiwanese 1p plural), is ⿱她心 (f. equivalent to 怹) »
🔗 https://bsky.app/profile/babelstone.co.uk/post/3lbrxowqt7k24
ALT text
Screenshot of CJK Related data from Unicopedia Sinica: Chinese Personal Pronouns
@mikaeru@mastodon.social
> This increases the number of encoded CJK ideographs to over 100,000!
十万字【じゅうまんじ】!
mastodon.social
Michel Mariani (@mikaeru@mastodon.social)
New additions include 4,298 additional CJK unified ideographs in a new block, CJK Unified Ideographs Extension J, as well as 18 other CJK ideographs added to the existing Extension C and Extension E blocks. This increases the number of encoded CJK ideographs to over 100,000! Also, nearly 2,500 already-encoded CJK ideographs are horizontally extended by the addition of source references and glyphs reflecting use of those ideographs in China and Korea. 🔗 https://blog.unicode.org/2025/09/unicode-170-release-announcement.html #Unicode #CJK
@mikaeru@mastodon.social
RE: https://mastodon.social/@mikaeru/115567152437555585
New additions include 4,298 additional CJK unified ideographs in a new block, CJK Unified Ideographs Extension J, as well as 18 other CJK ideographs added to the existing Extension C and Extension E blocks.
This increases the number of encoded CJK ideographs to over 100,000!
Also, nearly 2,500 already-encoded CJK ideographs are horizontally extended by the addition of source references and glyphs reflecting use of those ideographs in China and Korea.
🔗 https://blog.unicode.org/2025/09/unicode-170-release-announcement.html

blog.unicode.org
Unicode 17.0 Release Announcement
Announcing The Unicode® Standard, Version 17.0 The Unicode Standard is the foundation for all global digital communications, providing the e...
@mikaeru@mastodon.social
New additions include 4,298 additional CJK unified ideographs in a new block, CJK Unified Ideographs Extension J, as well as 18 other CJK ideographs added to the existing Extension C and Extension E blocks.
This increases the number of encoded CJK ideographs to over 100,000!
Also, nearly 2,500 already-encoded CJK ideographs are horizontally extended by the addition of source references and glyphs reflecting use of those ideographs in China and Korea.
🔗 https://blog.unicode.org/2025/09/unicode-170-release-announcement.html
blog.unicode.org
Unicode 17.0 Release Announcement
Announcing The Unicode® Standard, Version 17.0 The Unicode Standard is the foundation for all global digital communications, providing the e...
@mikaeru@mastodon.social
The latest version of the open-source application "Unicopedia Sinica" is now available, adding support for all the new CJK/Unihan characters defined in Unicode 17.0.
ALT text
Screenshot of the open-source application Unicopedia Sinica v.17.0.0
@mikaeru@mastodon.social
The latest version of the open-source application "Unicopedia Sinica" is now available, adding support for all the new CJK/Unihan characters defined in Unicode 17.0.
ALT text
Screenshot of the open-source application Unicopedia Sinica v.17.0.0
@mikaeru@mastodon.social
The latest version of the open-source application "Unicopedia Sinica" is now available, adding support for all the new CJK/Unihan characters defined in Unicode 17.0.
ALT text
Screenshot of the open-source application Unicopedia Sinica v.17.0.0
@SnoopJ@hachyderm.io
the most important part of #Unicode history is when a mouse fell out of a light fixture and got added to the count of members present at a Technical Committee meeting (9 Nov 2016)
ALT text
Screenshot of meeting notes for UTC Meeting 149. Text reads: Mouse now present. 6.502 members represented. [149-A94] Action Item for Landlord: Capture and exile the mouse that just fell out of the light fixture.
@mikaeru@mastodon.social
In Unicode, up to 11,328 "Small Seal" characters are finally making their way through the "Pipeline"...
"WG2 N5341 - Small Seal Code charts and Data set"
🔗 https://www.unicode.org/wg2/docs/n5341-SmallSealChart.pdf
"Topical Document List: Seal Script"
🔗 https://www.unicode.org/L2/topical/seal/
"Proposed New Characters: The Pipeline"
🔗 https://www.unicode.org/alloc/Pipeline.html
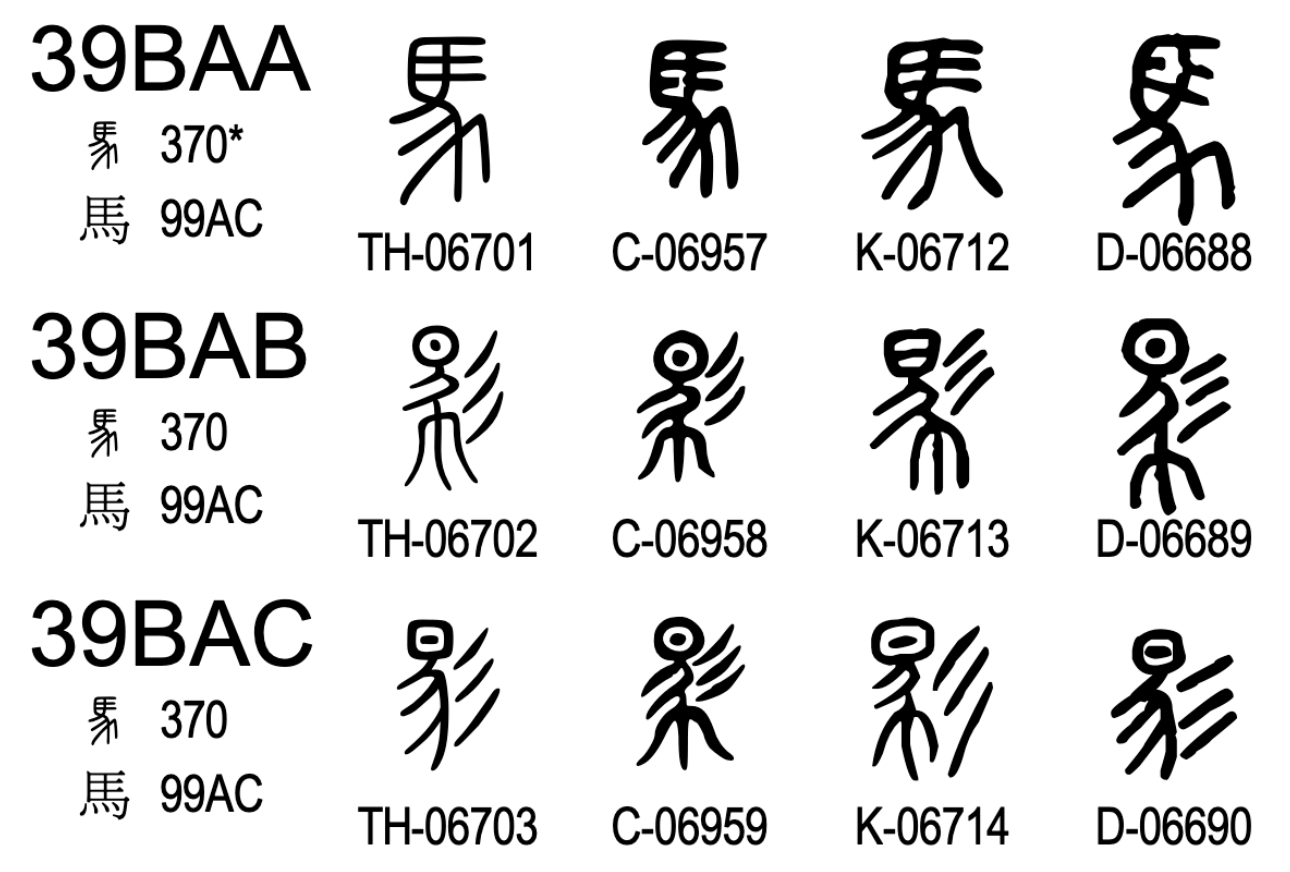
ALT text
Screenshot of the "Small Seal" forms of 馬 (Horse) in the WG2 document n5341: "Small Seal Codecharts and Data Set"
@mikaeru@mastodon.social
New in Unicopedia Ægypta:
- Added all Unikemet-related utilities from Unicopedia Plus.
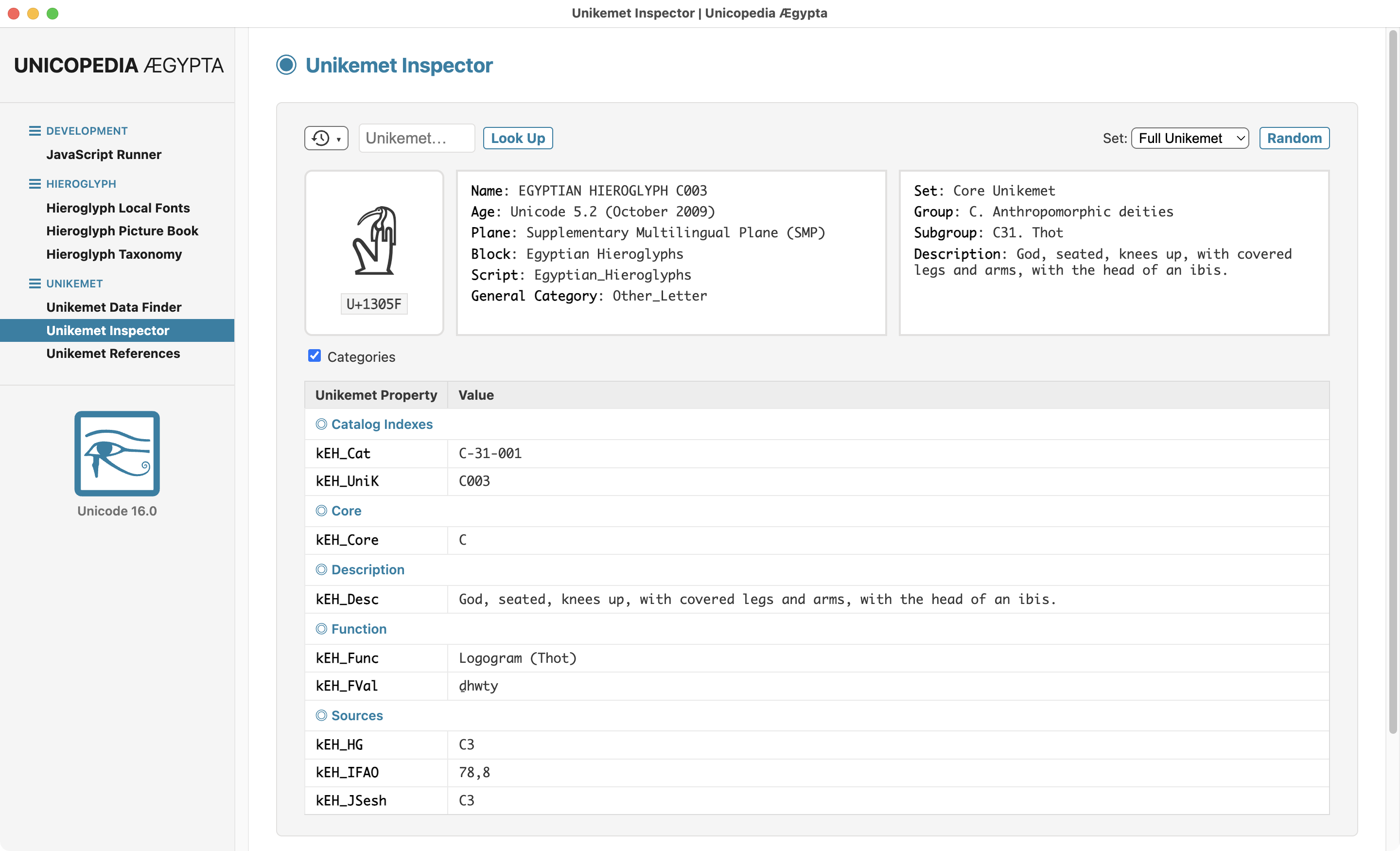
ALT text
Screenshot of Unicopedia Ægypta app: Unikemet Inspector utility
@mikaeru@mastodon.social
New in Unicopedia Ægypta:
- Added all Unikemet-related utilities from Unicopedia Plus.
ALT text
Screenshot of Unicopedia Ægypta app: Unikemet Inspector utility
@mikaeru@mastodon.social
New in Unicopedia Sinica:
- Added all Unihan-related utilities from Unicopedia Plus.
- Added typeface selector between serif and sans-serif in the Pan-CJK Font Variants utility.
Planned:
- Utilities for non-Han scripts: Khitan Small Script, Nüshu, Tangut.
- Utilities for Jurchen, Small Seal (Unicode 18.0?)
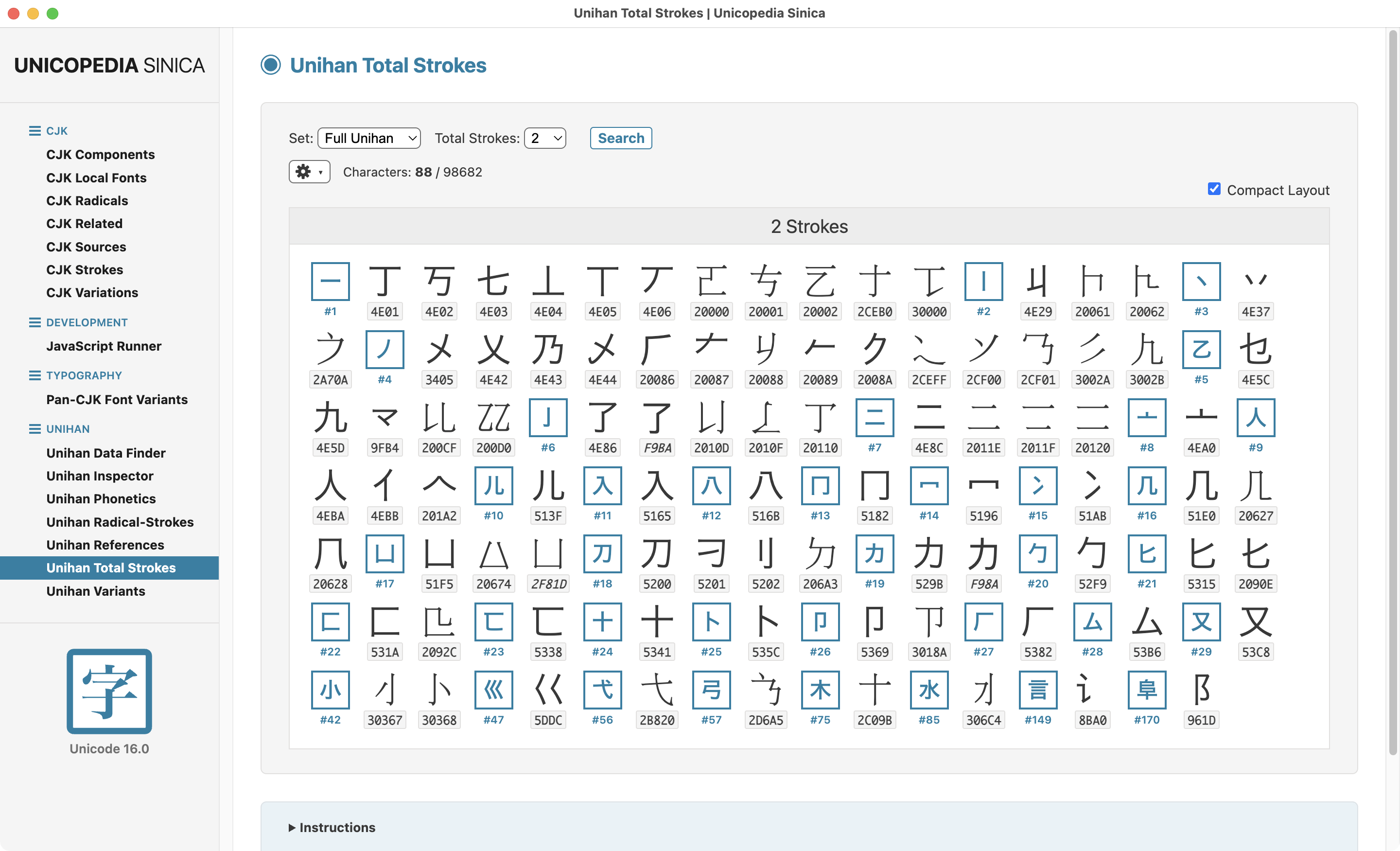
ALT text
Screenshot of Unicopedia Sinica app: Unihan Total Strokes utility
@mikaeru@mastodon.social
New in Unicopedia Sinica:
- Added all Unihan-related utilities from Unicopedia Plus.
- Added typeface selector between serif and sans-serif in the Pan-CJK Font Variants utility.
Planned:
- Utilities for non-Han scripts: Khitan Small Script, Nüshu, Tangut.
- Utilities for Jurchen, Small Seal (Unicode 18.0?)
ALT text
Screenshot of Unicopedia Sinica app: Unihan Total Strokes utility
@mikaeru@mastodon.social
New in Unicopedia Plus:
- All Unihan-related utilities have been moved to Unicopedia Sinica.
- All Unikemet-related utilities have been moved to Unicopedia Ægypta.
🔗 https://codeberg.org/tonton-pixel/unicopedia-plus
🔗 https://codeberg.org/tonton-pixel/unicopedia-sinica
🔗 https://codeberg.org/tonton-pixel/unicopedia-aegypta
![Screenshot of Unicopedia Plus app: log(😅) =💧log(😄) [Math Geekiness]](https://files.mastodon.social/media_attachments/files/115/515/779/327/041/625/original/a3e194873e53df94.png)
ALT text
Screenshot of Unicopedia Plus app: log(😅) =💧log(😄) [Math Geekiness]
@mikaeru@mastodon.social
New in Unicopedia Plus:
- All Unihan-related utilities have been moved to Unicopedia Sinica.
- All Unikemet-related utilities have been moved to Unicopedia Ægypta.
🔗 https://codeberg.org/tonton-pixel/unicopedia-plus
🔗 https://codeberg.org/tonton-pixel/unicopedia-sinica
🔗 https://codeberg.org/tonton-pixel/unicopedia-aegypta
ALT text
Screenshot of Unicopedia Plus app: log(😅) =💧log(😄) [Math Geekiness]
@mikaeru@mastodon.social · Reply to Michel Mariani
[Follow-Up]
Reference links:
- UTS #18: Unicode Regular Expressions
🔗 https://www.unicode.org/reports/tr18/
- UTS #18: Unicode Regular Expressions [Proposed Update]
🔗 https://www.unicode.org/reports/tr18/proposed.html
- Issues - tonton-pixel/unicopedia-plus - Codeberg.org
🔗 https://codeberg.org/tonton-pixel/unicopedia-plus/issues
codeberg.org
unicopedia-plus
Developer-oriented set of Unicode, Unihan, Unikemet & emoji utilities wrapped into one single app, built with Electron.
@mikaeru@mastodon.social
The "official" Unicode Regular Expressions (UTS #18) document, dated February 8, 2022, has never been updated since then, and the four new Unicode properties introduced in Unicode 15.1 are only listed in the Proposed Update *draft*, dated May 11, 2023...
This could explain why #Safari, #Firefox, and the #Electron framework (#Chromium) trigger an "invalid property" error for the /\p{IDS_Unary_Operator}/u #regex in JavaScript, while /\p{IDS_Binary_Operator}/u is ok...
@argv_minus_one@mastodon.sdf.org
Back in the 1990s, I was kind of annoyed by #GNU people's fondness for misusing the grave accent character ` as an open-quote character. They would write quoted text ``like this''.
I assume it looked good on some 1970s terminal or another, but it looked atrocious in your average '90s GUI font.
Thankfully, #Unicode came along and defined actual open-quote and close-quote characters, and this whole issue exists largely in the past now.
@mikaeru@mastodon.social
“I'm still waiting for him to learn about Unicode, then mandate US ASCII on all government websites”
[Andrew West 魏安 - January 2025]
https://bsky.app/profile/babelstone.co.uk/post/3lgdbhazfps2f

bsky.app
Andrew West 魏安 (@babelstone.co.uk)
I'm still waiting for him to learn about Unicode, then mandate US ASCII on all government websites
@mikaeru@mastodon.social
Some people in the US are possibly nostalgic of the "ASCII" acronym where "A" stands for "American"... Unicode is definitely more "universal", some might even say "woke":
- It encodes characters of writing systems from all around the world.
- The Script Encoding Initiative (SEI) comes from the University of Berkeley, CA.
- It encodes "diversity" symbols such as ♀♂⚢⚣⚤⚥⚦⚧⚨⚩⚲, 🏳️🌈 🏳️⚧️, or even 🇪🇺 🇺🇳.
- More than two-thirds of the Unicode characters originate from China.
@mikaeru@mastodon.social
Some people in the US are possibly nostalgic of the "ASCII" acronym where "A" stands for "American"... Unicode is definitely more "universal", some might even say "woke":
- It encodes characters of writing systems from all around the world.
- The Script Encoding Initiative (SEI) comes from the University of Berkeley, CA.
- It encodes "diversity" symbols such as ♀♂⚢⚣⚤⚥⚦⚧⚨⚩⚲, 🏳️🌈 🏳️⚧️, or even 🇪🇺 🇺🇳.
- More than two-thirds of the Unicode characters originate from China.
@mikaeru@mastodon.social
According to the "Can I Unicode‽" web page, as of today, the #Chrome navigator is still "stuck" in Unicode 15.1, while the latest version of #Unicode is 17.0!
https://mathiasbynens.github.io/caniunicode/
The fact that the #Electron framework is based on #Chromium probably explains why it is still lagging behind too...
Supporting Unicode 16.0 would allow me to produce a final stable version of my Unicopedia Plus app, before I can start working on a version for Unicode 17.0.
mathiasbynens.github.io
Can I Unicode‽ Unicode support across JavaScript engines
@mikaeru@mastodon.social
Until now, I've been able to provide a working (pre-release though) edition of my Unicopedia Plus app, targeting a specific #Unicode version not yet supported by the #Electron framework, by embedding a copy of all the up-to-date Unicode data files, and making use of the `regexpu-core` module to emulate the most "critical" regular expressions, but this is merely a workaround, not what it has been designed for in the first place...
github.com
GitHub - mathiasbynens/regexpu-core: regexpu’s core functionality, i.e. `rewritePattern(pattern, flag, options)`, which enables rewriting regular expressions that make use of the ES6 `u` flag into equivalent ES5-compatible regular expression patterns.
regexpu’s core functionality, i.e. `rewritePattern(pattern, flag, options)`, which enables rewriting regular expressions that make use of the ES6 `u` flag into equivalent ES5-compatible regular exp...
@mikaeru@mastodon.social
As you might expect, my main application Unicopedia Plus relies heavily on #Unicode...
Today, I updated the #Electron framework to its latest major version 39.0.0, hoping it would at last bring full support to Unicode 16.0, published by the UTC in September 2024 , but unfortunately no; it is still stuck in Unicode 15.1, published in September 2023! Moreover, Unicode 17.0 has already been officially released...
codeberg.org
unicopedia-plus
Developer-oriented set of Unicode, Unihan, Unikemet & emoji utilities wrapped into one single app, built with Electron.
@kirschwipfel@nerdculture.de
Wer hat Details dazu, wie sich der #GlassWorm via #Unicode versteckt?
Der Wurm ist sehr ausgefeilt, mich interessiert jedoch dieser Aspekt besonders, weil dadurch angeblich auch "normale" Code-Analyser es nicht erkennen, aber der JavaScript-Interpreter es akzeptiert. Das wurde ich mir gerne mit anderen Interpreten und anderen Editoren ansehen.
Perfekt wäre, wenn jemand den Wurm (oder Teile davon) hätte. Ich nehme aber auch detaillierte Beschreibungen, mit denen ich FAS nachstellen könnte.
@mikaeru@mastodon.social
New utility in Unicopedia Plus:
- Unihan Total Strokes
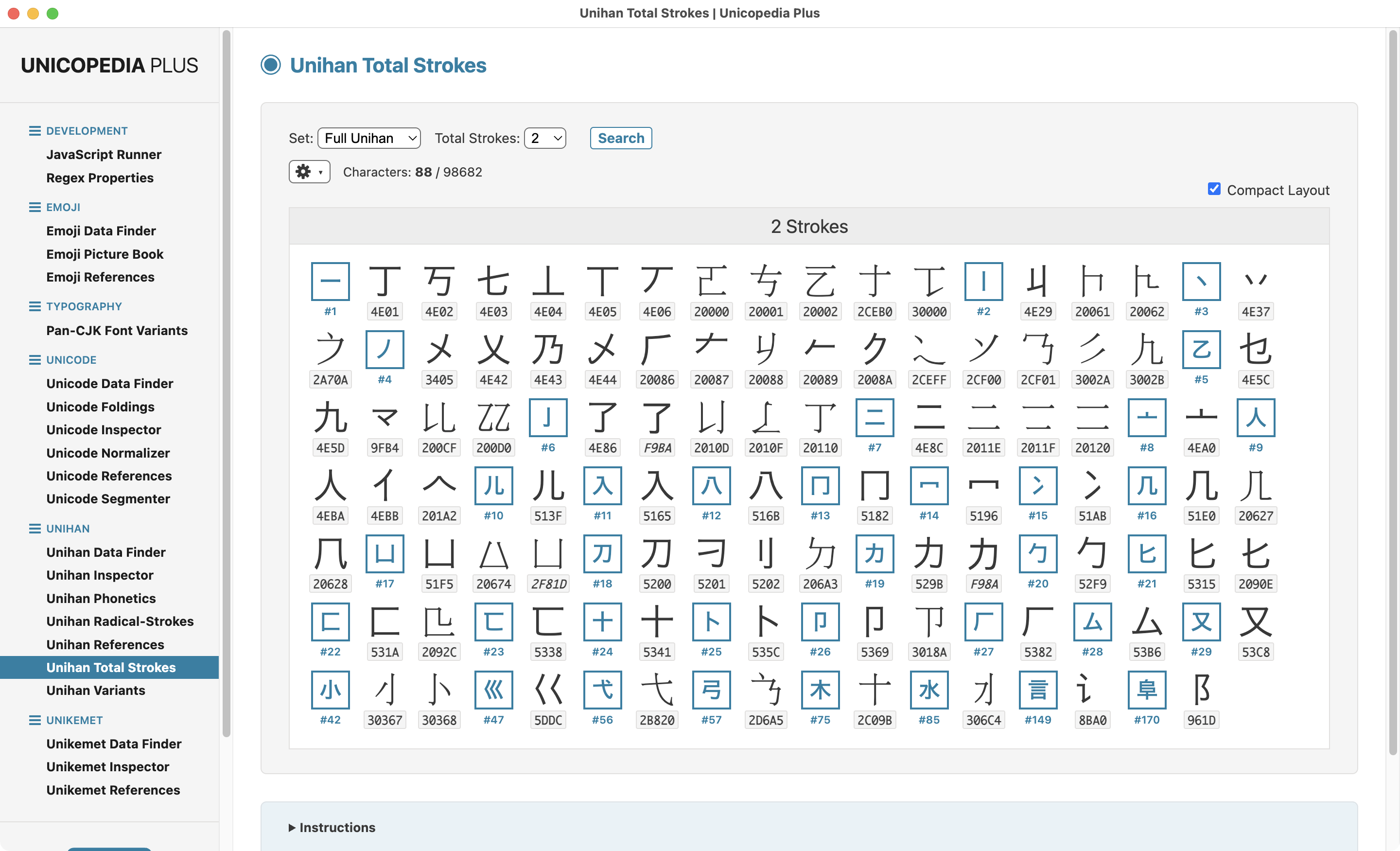
ALT text
Screenshot of the Unihan Total Strokes utility of the Unicopedia Plus application
@stefan@stefanbohacek.online · Reply to Stefan Bohacek
Not enough time to do anything too interesting for today's #WeirdWebOctober.
weirdweboctober.stefanbohacek.com
Weird Web October 2025 #15: Unicode
Doubling the size.
@kkarhan@infosec.space · Reply to ari :ariYeah:
@reiver@mastodon.social · Reply to @reiver ⊼ (Charles) :batman:
This probably means that someone should modernize HTTP by creating HTTP/1.4.
mastodon.social
@reiver ⊼ (Charles) :batman: (@reiver@mastodon.social)
Google more-or-less created 2 new versions of the HTTP protocol — HTTP/2 and HTTP/3 — But didn't bother make either of them (officially) support UTF-8 in the HTTP request. #HTTP #Unicode #UTF8 #WorldWideWeb
@reiver@mastodon.social
Google more-or-less created 2 new versions of the HTTP protocol — HTTP/2 and HTTP/3 —
But didn't bother make either of them (officially) support UTF-8 in the HTTP request.
@screambiogenesis@mastodon.social
Thanks to a ~3700 year old clay disc found in Crete a hundred years ago, Unicode has a dude with a mohawk.
U+101D1: 𐇑

ALT text
Detail shot of the Phaistos Disc, a presumably Minoan artifact from the second millennium BCE, found in southern Crete in 1908. In the picture, many pictographic characters from the spiral track on the as-yet-undeciphered disc are visible, such as shields, eagles, horns, combs, tuna fish, and more. The "plumed head" character is seen at least four times in this small inlay, indicating that punk rock was very important to Minoan culture.
@screambiogenesis@mastodon.social
Thanks to a ~3700 year old clay disc found in Crete a hundred years ago, Unicode has a dude with a mohawk.
U+101D1: 𐇑
ALT text
Detail shot of the Phaistos Disc, a presumably Minoan artifact from the second millennium BCE, found in southern Crete in 1908. In the picture, many pictographic characters from the spiral track on the as-yet-undeciphered disc are visible, such as shields, eagles, horns, combs, tuna fish, and more. The "plumed head" character is seen at least four times in this small inlay, indicating that punk rock was very important to Minoan culture.
@reiver@mastodon.social
Google more-or-less created 2 new versions of the HTTP protocol — HTTP/2 and HTTP/3 —
But didn't bother make either of them (officially) support UTF-8 in the HTTP request.
@michels@mastodon.social
That was new to me. You can combine any character with COMBINING ENCLOSING KEYCAP (U+20E3) to get a character for a keyboard shortcut.
#Unicode
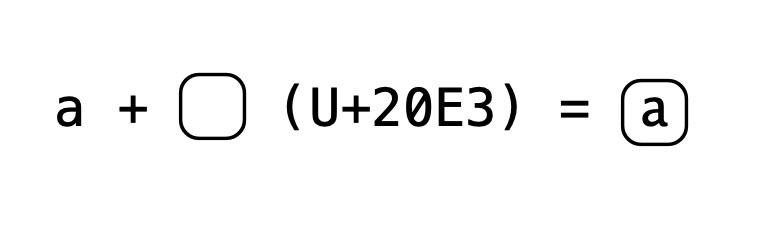
@michels@mastodon.social
That was new to me. You can combine any character with COMBINING ENCLOSING KEYCAP (U+20E3) to get a character for a keyboard shortcut.
#Unicode
@rnd@toot.cat
one thing i don't understand at all is why #unicode is specifically set up so codepoints larger than U+10FFFF are treated as invalid, not even "reserved for future use"
are we completely sure that we NEVER end up needing more than 1114112 codepoints? sure, right now we're at 159801, less than 15%, but who knows what will happen in the future
@frontenddogma@mas.to
Targeting Specific Characters With CSS Rules, by @Edent:
https://shkspr.mobi/blog/2025/09/targetting-specific-characters-with-css-rules/
shkspr.mobi
Targetting specific characters with CSS rules
You can't. There is no way to use CSS to apply a style to every letter "E". It simply can't be done. At least, that's what they want you to think… What if I told you there was a secret and forbidden way to target specific characters in text and apply some styles to them? As part of my experiments in creating a "drunk" CSS theme, I thought it would be useful to change the presentation of s…
@frontenddogma@mas.to
Targeting Specific Characters With CSS Rules, by @Edent:
https://shkspr.mobi/blog/2025/09/targetting-specific-characters-with-css-rules/
shkspr.mobi
Targetting specific characters with CSS rules
You can't. There is no way to use CSS to apply a style to every letter "E". It simply can't be done. At least, that's what they want you to think… What if I told you there was a secret and forbidden way to target specific characters in text and apply some styles to them? As part of my experiments in creating a "drunk" CSS theme, I thought it would be useful to change the presentation of s…

@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@amake@mastodon.social
Newly covered #Unicode code points in iOS 26.
I have to admit I have not updated anything to 26 yet. At least on Mac I usually wait for #MacPorts issues to be cleared up, but this one might take me a while...
㇀㇁㇂㇃㇄㇅㇆㇇㇈㇉㇊㇋㇌㇍㇎㇏㇐㇑㇒㇓㇔㇕㇖㇗㇘㇙㇚㇛㇜㇝㇞㇟㇠㇡㇢㇣𞓐𞓑𞓒𞓓𞓔𞓕𞓖𞓗𞓘𞓙𞓚𞓛𞓜𞓝𞓞𞓟𞓠𞓡𞓢𞓣𞓤𞓥𞓦𞓧𞓨𞓩𞓪𞓫𞓮𞓯𞓬𞓭𞓰𞓱𞓲𞓳𞓴𞓵𞓶𞓷𞓸𞓹𠁣𠃛𠊎𠖄𠖫𠗻𠘆𠜖𠞩𠞭𠠃𠠝𠠫𠢕𠴭𠺅𠺣𠻞𡌴𡟓𡨞𡳞𡽜𢄧𢎙𢒉𢓜𢛟𢜳𢬳𢯭𢯾𢱤𢲴𢳪𢶀𢺴𢻷𢼌𢼛𢿞𣁳𣍐𣗺𣦼𣩈𣮈𣲩𣸤𣼎𤁢𤊶𤍒𤐙𤐰𤖯𤘅𤞚𤡯𤲍𤶃𤸁𤺅𤺪𤿎𥉔𥌚𥍉𥏘𥐵𥯟𥯥𥰔𥴊𥽕𦃓𦉎𦊓𦒨𦘅𦜆𧉅𧉟𧌄𧜞𧩣𧮙𧰵𧺤𧻴𧿳𨂿𨅔𨒇𨢑𩏠𩑾𩔵𩚨𩛩𩜄𩜇𩜰𩟗𩣳𩨑𩵱𩸙𩼧𪀋𪐞𪖐𪖶𪘒𪜶𪢼𪳕𪹚𫓩𫝏𫝘𫝙𫝞𫝺𫝻𫞭𫞼𫟂𫟊𫟧𫠄𫠛𫣆𫰡𬈜𬏛𬠖𬤐𬦰𬬺𬮤𮀎𮣳𮭦𮯴𰣻𰵝𰵞𰵧𰹬𰾫𱂐𱮒𱱿𱳪𲂎
@amake@mastodon.social
Newly covered #Unicode code points in iOS 26.
I have to admit I have not updated anything to 26 yet. At least on Mac I usually wait for #MacPorts issues to be cleared up, but this one might take me a while...
㇀㇁㇂㇃㇄㇅㇆㇇㇈㇉㇊㇋㇌㇍㇎㇏㇐㇑㇒㇓㇔㇕㇖㇗㇘㇙㇚㇛㇜㇝㇞㇟㇠㇡㇢㇣𞓐𞓑𞓒𞓓𞓔𞓕𞓖𞓗𞓘𞓙𞓚𞓛𞓜𞓝𞓞𞓟𞓠𞓡𞓢𞓣𞓤𞓥𞓦𞓧𞓨𞓩𞓪𞓫𞓮𞓯𞓬𞓭𞓰𞓱𞓲𞓳𞓴𞓵𞓶𞓷𞓸𞓹𠁣𠃛𠊎𠖄𠖫𠗻𠘆𠜖𠞩𠞭𠠃𠠝𠠫𠢕𠴭𠺅𠺣𠻞𡌴𡟓𡨞𡳞𡽜𢄧𢎙𢒉𢓜𢛟𢜳𢬳𢯭𢯾𢱤𢲴𢳪𢶀𢺴𢻷𢼌𢼛𢿞𣁳𣍐𣗺𣦼𣩈𣮈𣲩𣸤𣼎𤁢𤊶𤍒𤐙𤐰𤖯𤘅𤞚𤡯𤲍𤶃𤸁𤺅𤺪𤿎𥉔𥌚𥍉𥏘𥐵𥯟𥯥𥰔𥴊𥽕𦃓𦉎𦊓𦒨𦘅𦜆𧉅𧉟𧌄𧜞𧩣𧮙𧰵𧺤𧻴𧿳𨂿𨅔𨒇𨢑𩏠𩑾𩔵𩚨𩛩𩜄𩜇𩜰𩟗𩣳𩨑𩵱𩸙𩼧𪀋𪐞𪖐𪖶𪘒𪜶𪢼𪳕𪹚𫓩𫝏𫝘𫝙𫝞𫝺𫝻𫞭𫞼𫟂𫟊𫟧𫠄𫠛𫣆𫰡𬈜𬏛𬠖𬤐𬦰𬬺𬮤𮀎𮣳𮭦𮯴𰣻𰵝𰵞𰵧𰹬𰾫𱂐𱮒𱱿𱳪𲂎
@bortzmeyer@mastodon.gougere.fr
Dans le coffre aux trésors d’Unicode 17 : des chameaux et un trombone : https://linuxfr.org/news/dans-le-coffre-aux-tresors-d-unicode-17-des-chameaux-et-un-trombone
linuxfr.org
Dans le coffre aux trésors d’Unicode 17 : des chameaux et un trombone - LinuxFr.org
L’actualité du logiciel libre et des sujets voisins (DIY, Open Hardware, Open Data, les Communs, etc.), sur un site francophone contributif géré par une équipe bénévole par et pour des libristes enthousiastes
@bortzmeyer@mastodon.gougere.fr
Dans le coffre aux trésors d’Unicode 17 : des chameaux et un trombone : https://linuxfr.org/news/dans-le-coffre-aux-tresors-d-unicode-17-des-chameaux-et-un-trombone
linuxfr.org
Dans le coffre aux trésors d’Unicode 17 : des chameaux et un trombone - LinuxFr.org
L’actualité du logiciel libre et des sujets voisins (DIY, Open Hardware, Open Data, les Communs, etc.), sur un site francophone contributif géré par une équipe bénévole par et pour des libristes enthousiastes
@Edent@mastodon.social
Android will *not* be getting most of the Unicode 17 updates.
Some of its fonts are over a decade out of date - and Google refuses to re-use its own Noto font stack.
I've raised the issue at:
https://issuetracker.google.com/issues/366415133
If you're a Googler please ask someone to prioritise this issue. Can everyone else please hit the +1 button.
issuetracker.google.com
Google Issue Tracker
@Edent@mastodon.social
Android will *not* be getting most of the Unicode 17 updates.
Some of its fonts are over a decade out of date - and Google refuses to re-use its own Noto font stack.
I've raised the issue at:
https://issuetracker.google.com/issues/366415133
If you're a Googler please ask someone to prioritise this issue. Can everyone else please hit the +1 button.
issuetracker.google.com
Google Issue Tracker
@triker@mstdn.plus
I just learned how to type unicode letters and dingbats in Linux!
Ctrl + Shift + U press all 3 keys at once then let all three letters go.
then type in the unicode and press enter.
https://en.wikipedia.org/wiki/List_of_Unicode_characters
IE.
Ctrl + Shift + U 2713 is a tick or check mark
✓
Similarly, I can write ñ (n tilde) with:
ctrl + shift + U 00f1
See dingbats block for more check mark choices.
https://en.wikipedia.org/wiki/Dingbats_(Unicode_block)
All of unicode here:
https://home.unicode.org/
home.unicode.org
Home
@crickxson@post.lurk.org
Each time i use https://shapecatcher.com
I'm gratefull to #BenjaminMilde to have build it and keep it running.
"You know what some #character looks like, but you've forgotten its name or its #Unicode code point. Now what do you do? #Shapecatcher is a new website, that helps you to find specific Unicode characters, just by #sketching their shape. Currently about 10000 of the most important Unicode characters are compared to your sketch and are analysed for similarities.
Under the hood, Shapecatcher uses so called "#shape contexts" to find similarities between two shapes. Shape contexts, a robust mathematical way of describing the concept of similarity between shapes, is a feature descriptor first proposed by #SergeBelongie and #JitendraMalik."

ALT text
Screen capture of the drawing zone of ShapeCatcher.

ALT text
1st results of the recognizing process

ALT text
Following results of the recognizing process

ALT text
Following results of the recognizing process
@crickxson@post.lurk.org
Each time i use https://shapecatcher.com
I'm gratefull to #BenjaminMilde to have build it and keep it running.
"You know what some #character looks like, but you've forgotten its name or its #Unicode code point. Now what do you do? #Shapecatcher is a new website, that helps you to find specific Unicode characters, just by #sketching their shape. Currently about 10000 of the most important Unicode characters are compared to your sketch and are analysed for similarities.
Under the hood, Shapecatcher uses so called "#shape contexts" to find similarities between two shapes. Shape contexts, a robust mathematical way of describing the concept of similarity between shapes, is a feature descriptor first proposed by #SergeBelongie and #JitendraMalik."
ALT text
Screen capture of the drawing zone of ShapeCatcher.
ALT text
1st results of the recognizing process
ALT text
Following results of the recognizing process
ALT text
Following results of the recognizing process
@xfq@w3c.social
Today marks 37 years since Joe Becker's landmark "Unicode 88" document!
@xfq@w3c.social
Today marks 37 years since Joe Becker's landmark "Unicode 88" document!
@timbray@cosocial.ca
Three small announcements:
1. RFC 9839, a guide to which Unicode characters you should never use: https://www.rfc-editor.org/rfc/rfc9839.html
2. Blog piece with background and context, “RFC 9839 and Bad Unicode”: https://www.tbray.org/ongoing/When/202x/2025/08/14/RFC9839
3. A little Go library that implements 9839’s exclusion subsets: https://github.com/timbray/RFC9839
github.com
GitHub - timbray/RFC9839: Go-language library to check for problematic Unicode code points
Go-language library to check for problematic Unicode code points - timbray/RFC9839
@timbray@cosocial.ca
Three small announcements:
1. RFC 9839, a guide to which Unicode characters you should never use: https://www.rfc-editor.org/rfc/rfc9839.html
2. Blog piece with background and context, “RFC 9839 and Bad Unicode”: https://www.tbray.org/ongoing/When/202x/2025/08/14/RFC9839
3. A little Go library that implements 9839’s exclusion subsets: https://github.com/timbray/RFC9839
github.com
GitHub - timbray/RFC9839: Go-language library to check for problematic Unicode code points
Go-language library to check for problematic Unicode code points - timbray/RFC9839
@timbray@cosocial.ca
Three small announcements:
1. RFC 9839, a guide to which Unicode characters you should never use: https://www.rfc-editor.org/rfc/rfc9839.html
2. Blog piece with background and context, “RFC 9839 and Bad Unicode”: https://www.tbray.org/ongoing/When/202x/2025/08/14/RFC9839
3. A little Go library that implements 9839’s exclusion subsets: https://github.com/timbray/RFC9839
github.com
GitHub - timbray/RFC9839: Go-language library to check for problematic Unicode code points
Go-language library to check for problematic Unicode code points - timbray/RFC9839
@idontlikenames@mastodon.gamedev.place
american: OwO
cyrilic: ꙮшꙮ
armenian: ՕաՕ
georgian: ტოტ ႣⴍႣ
gothic: 𐍈𐌸𐍈
greek: ΘωΘ ΩωΩ ΦωΦ ΟωΟ
coptic: ⲐⲱⲐ ⲪⲱⲪ ⲞⲱⲞ
hebrew: סשס
ge'ez: ዐሠዐ
chinese: 口山口
inuktitut: ᑭᓚᓗᑫ ᐁᓚᓗᐁ
vai: ꖘꕀꖘ ꖴꕀꖴ
khmer: ឰឃឰ ២ឃ២ ៙ឃ៙
sinhala: ඞ෴ඞ ට෴ට මයම
tibetan: ༠ྻ ༠ ༠ྏ ༠
jap: ᶘᵒᴥᵒᶅ
#owo #protoworld #linguistics #language #unicode #writing #kaomoji
@idontlikenames@mastodon.gamedev.place
american: OwO
cyrilic: ꙮшꙮ
armenian: ՕաՕ
georgian: ტოტ ႣⴍႣ
gothic: 𐍈𐌸𐍈
greek: ΘωΘ ΩωΩ ΦωΦ ΟωΟ
coptic: ⲐⲱⲐ ⲪⲱⲪ ⲞⲱⲞ
hebrew: סשס
ge'ez: ዐሠዐ
chinese: 口山口
inuktitut: ᑭᓚᓗᑫ ᐁᓚᓗᐁ
vai: ꖘꕀꖘ ꖴꕀꖴ
khmer: ឰឃឰ ២ឃ២ ៙ឃ៙
sinhala: ඞ෴ඞ ට෴ට මයම
tibetan: ༠ྻ ༠ ༠ྏ ༠
jap: ᶘᵒᴥᵒᶅ
#owo #protoworld #linguistics #language #unicode #writing #kaomoji
@jdlh@mstdn.ca
My quest at #fedicon2025 is to find #Fediverse services and handles with non-Latin characters. Can you link me to examples?
I hear there are many #Japan ese people active in Fediverse, but all the examples I see have only Latin script. #Unicode #Fedicon #Mastodon #UniversalAcceptance
@jdlh@mstdn.ca
My quest at #fedicon2025 is to find #Fediverse services and handles with non-Latin characters. Can you link me to examples?
I hear there are many #Japan ese people active in Fediverse, but all the examples I see have only Latin script. #Unicode #Fedicon #Mastodon #UniversalAcceptance
@jdlh@mstdn.ca
My quest at #fedicon2025 is to find #Fediverse services and handles with non-Latin characters. Can you link me to examples?
I hear there are many #Japan ese people active in Fediverse, but all the examples I see have only Latin script. #Unicode #Fedicon #Mastodon #UniversalAcceptance
@mikaeru@mastodon.social
Beautifully crafted BabelStone Han font, by Andrew West 魏安
#BabelStone Han v. 15.1.3 is a free #Unicode #CJK #font with over 57,000 Han characters (#hanzi, #kanji, #hanja), and 62,061 Unicode characters in total. It is a Song/Ming style (宋体/明體) font, with glyphs modelled on the official character forms used in the People's Republic of China, and is primarily intended for writing Modern Standard #Chinese, Classical Chinese, and various Sinitic languages and dialects.

ALT text
Repeated: 龙 U+9F99 U+31342 U+2EE5D
@mikaeru@mastodon.social
New in the CJK Variations utility of Unicopedia Sinica:
- Support for the latest Ideographic Variation Database (IVD 2025), adding the new CAAPH Collection.
- Support for the updated BabelStone Collection (unregistered), based on the latest BabelStone Han font (v17.0.0 BETA), by Andrew C. West (魏安), 1960-2025 RIP (安息吧).
🔗 https://https://codeberg.org/tonton-pixel/unicopedia-sinica
#Unicopedia #Unicode #Unihan #CJK #IdeographicVariationDatabase #IVD #CAAPH #BabelStone
ALT text
Screenshot of the CJK Variations utility of Unicopedia Sinica for Unicode character U+3AB4
ALT text
Screenshot of the CJK Variations utility of Unicopedia Sinica for Unicode character U+4E9B
@mikaeru@mastodon.social
New in the CJK Variations utility of Unicopedia Sinica:
- Support for the latest Ideographic Variation Database (IVD 2025), adding the new CAAPH Collection.
- Support for the updated BabelStone Collection (unregistered), based on the latest BabelStone Han font (v17.0.0 BETA), by Andrew C. West (魏安), 1960-2025 RIP (安息吧).
🔗 https://https://codeberg.org/tonton-pixel/unicopedia-sinica
#Unicopedia #Unicode #Unihan #CJK #IdeographicVariationDatabase #IVD #CAAPH #BabelStone
ALT text
Screenshot of the CJK Variations utility of Unicopedia Sinica for Unicode character U+3AB4
ALT text
Screenshot of the CJK Variations utility of Unicopedia Sinica for Unicode character U+4E9B
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@Timwi@nerdculture.de
I just found out that #Unicode has segment-display digit characters. The below screenshot is all in one font (#JuliaMono). The characters are U+1FBF0 to U+1FBF9. Unicode is gorgeous
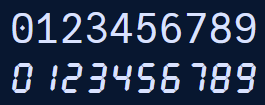
@ParisWeb@mamot.fr
Avec @MoritzBrouhaha, découvrez l'histoire du standard informatique Unicode, utilisé par tout le monde à travers le globe dans nos communications quotidiennes.
https://www.paris-web.fr/2025/conference/a-la-decouverte-du-monde-au-travers-de-lunicode

ALT text
« À la découverte du monde au travers de l’Unicode » par Loïc Marleix
@ParisWeb@mamot.fr
Avec @MoritzBrouhaha, découvrez l'histoire du standard informatique Unicode, utilisé par tout le monde à travers le globe dans nos communications quotidiennes.
https://www.paris-web.fr/2025/conference/a-la-decouverte-du-monde-au-travers-de-lunicode
ALT text
« À la découverte du monde au travers de l’Unicode » par Loïc Marleix
@ParisWeb@mamot.fr
Avec @MoritzBrouhaha, découvrez l'histoire du standard informatique Unicode, utilisé par tout le monde à travers le globe dans nos communications quotidiennes.
https://www.paris-web.fr/2025/conference/a-la-decouverte-du-monde-au-travers-de-lunicode
ALT text
« À la découverte du monde au travers de l’Unicode » par Loïc Marleix
@paulmelis@social.edu.nl
The recycling symbol ♻ in a git branch name, what a time to be alive 😎
Also, nice of #github to warn about possibly hidden characters, but not sure it applies in this case
@paulmelis@social.edu.nl
The recycling symbol ♻ in a git branch name, what a time to be alive 😎
Also, nice of #github to warn about possibly hidden characters, but not sure it applies in this case
@mikaeru@mastodon.social · Reply to Michel Mariani
No Electron support for the latest Unicode version is a major hindrance for my open-source Unicopedia Plus application, which I have to keep in Beta version for a long time because of that...
codeberg.org
unicopedia-plus
Developer-oriented set of Unicode, Unihan, Unikemet & emoji utilities wrapped into one single app, built with Electron.
@mikaeru@mastodon.social · Reply to Michel Mariani
No Electron support for the latest Unicode version is a major hindrance for my open-source Unicopedia Plus application, which I have to keep in Beta version for a long time because of that...
codeberg.org
unicopedia-plus
Developer-oriented set of Unicode, Unihan, Unikemet & emoji utilities wrapped into one single app, built with Electron.
@headword@lingo.lol · Reply to Unicode Watch �🔍
Interesting to see letters like 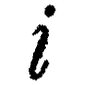 ,
, 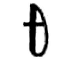 , and
, and  proposed for inclusion in Unicode!
proposed for inclusion in Unicode! 
#EnglishPhonotypicAlphabet #PhonotypicAlphabet #Phonotypic #Dania #Phonetic #Phonetics #PhoneticTranscription #Unicode
@mikaeru@mastodon.social
The Ideographic Research Group (IRG) is responsible for preparing and reviewing sets of CJK unified ideographs to be included in the Unicode Standard.
Current and future IRG source prefixes used to be listed in the main IRG homepage, but are now available in a separate dedicated page:
unicode.org
Current & Future IRG Source Prefixes
@mikaeru@mastodon.social · Reply to Le Monde.fr
![Emoji: drapeaux de la Bulgarie [BG] et de la Hongrie [HU]](https://files.mastodon.social/media_attachments/files/114/631/037/896/085/311/original/551d87cccc6dbeb2.png)
@mikaeru@mastodon.social · Reply to Le Monde.fr
@michels@mastodon.social
I added typographic guides to my Unicode viewer. I first tried the new TextRenderer, but found it too limited. I then switched back to CoreText. However, I then noticed that SwiftUI was cutting off some parts of the glyphs. It seems that they don’t expect the glyphs to extend beyond their bounding box.
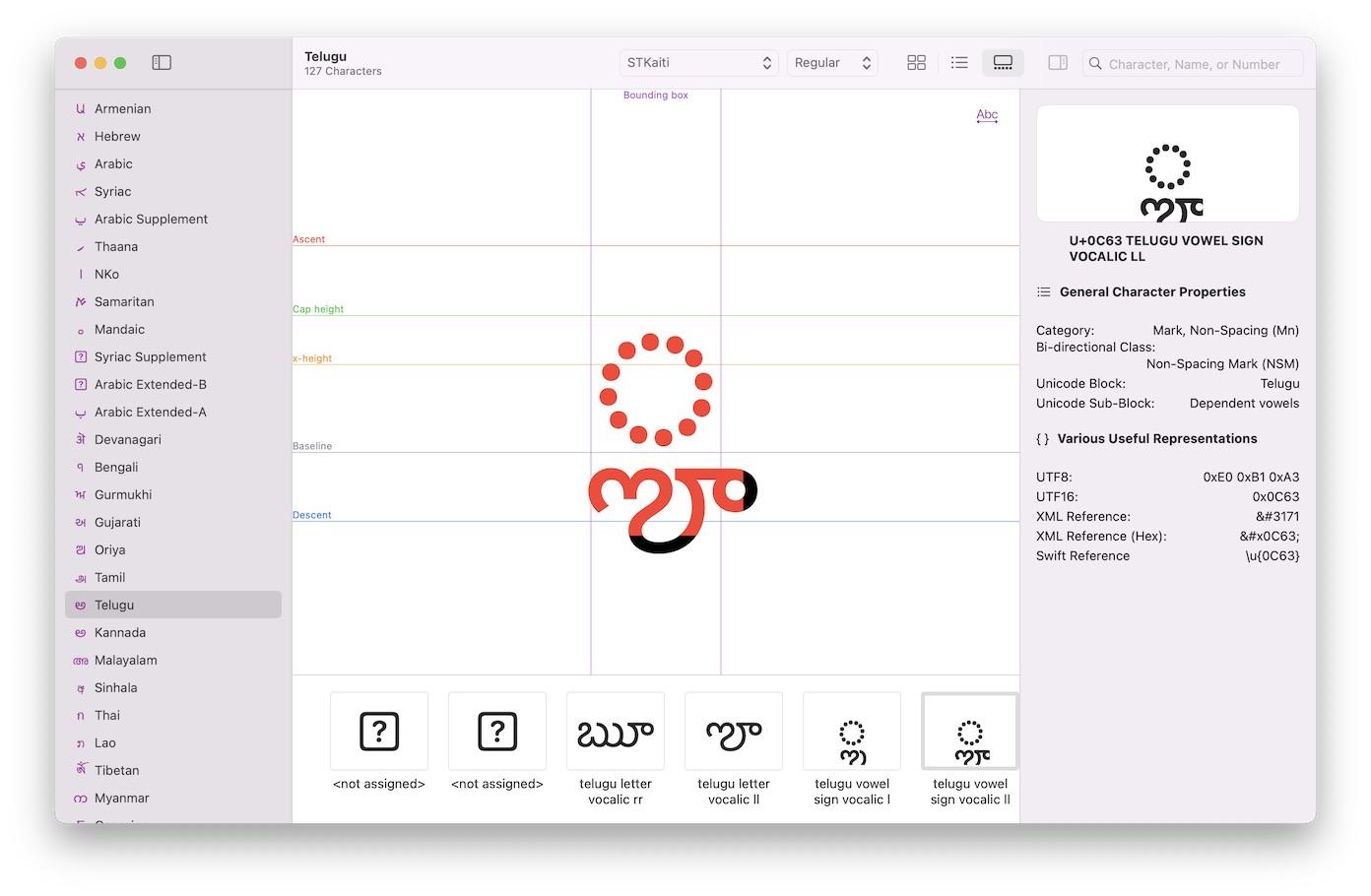
@michels@mastodon.social
I added typographic guides to my Unicode viewer. I first tried the new TextRenderer, but found it too limited. I then switched back to CoreText. However, I then noticed that SwiftUI was cutting off some parts of the glyphs. It seems that they don’t expect the glyphs to extend beyond their bounding box.
@mikaeru@mastodon.social
Apart from the issue of line formatting of plain text in the new Unicode contact form <https://support.unicode.org/osticket/open.php>, it appears that some pretty innocuous characters such as the vertical bar | or the degree sign ° are getting stripped out from the latest reports, in <https://www.unicode.org/review/pri526/> for instance.
Ironically enough, it seems that the Unicode contact form is not Unicode-conformant/compliant then. Maybe some kind of "Make ASCII Great Again" thing?

ALT text
Example of vertical bar | character getting stripped out from a PRI 526 report

ALT text
Example of degree sign ° character getting stripped out from a PRI 526 report
@mikaeru@mastodon.social
Apart from the issue of line formatting of plain text in the new Unicode contact form <https://support.unicode.org/osticket/open.php>, it appears that some pretty innocuous characters such as the vertical bar | or the degree sign ° are getting stripped out from the latest reports, in <https://www.unicode.org/review/pri526/> for instance.
Ironically enough, it seems that the Unicode contact form is not Unicode-conformant/compliant then. Maybe some kind of "Make ASCII Great Again" thing?
ALT text
Example of vertical bar | character getting stripped out from a PRI 526 report
ALT text
Example of degree sign ° character getting stripped out from a PRI 526 report
@amake@mastodon.social
@amake@mastodon.social
@mikaeru@mastodon.social · Reply to Michel Mariani
Unicode's new contact form at <https://support.unicode.org/osticket/open.php> is apparently an HTML editor "in disguise"; the only way I found to force it to keep the formatting of my plain text messages was to select the HTML mode and paste the text inside a <pre></pre> tag...
Still, some contents gets unexpectedly stripped out after submission of the report, like text between "<" and ">".
support.unicode.org
Unicode Consortium Support
customer support platform
@mikaeru@mastodon.social · Reply to Michel Mariani
Unicode's new contact form at <https://support.unicode.org/osticket/open.php> is apparently an HTML editor "in disguise"; the only way I found to force it to keep the formatting of my plain text messages was to select the HTML mode and paste the text inside a <pre></pre> tag...
Still, some contents gets unexpectedly stripped out after submission of the report, like text between "<" and ">".
support.unicode.org
Unicode Consortium Support
customer support platform
@Timwi@nerdculture.de
I just found out that #Unicode has segment-display digit characters. The below screenshot is all in one font (#JuliaMono). The characters are U+1FBF0 to U+1FBF9. Unicode is gorgeous
@Timwi@nerdculture.de
I just found out that #Unicode has segment-display digit characters. The below screenshot is all in one font (#JuliaMono). The characters are U+1FBF0 to U+1FBF9. Unicode is gorgeous
@mikaeru@mastodon.social
New utilities in Unicopedia Ægypta:
- Hieroglyph Picture Book
- Hieroglyph Taxonomy
🔗 https://codeberg.org/tonton-pixel/unicopedia-aegypta
#unicopedia #egyptian #hieroglyphs #taxonomy #picturebook #javascript #desktopapplication #electronjs #unicode

ALT text
Hieroglyph Picture Book utility screenshot
ALT text
Hieroglyph Taxonomy utility screenshot
@mikaeru@mastodon.social
New utilities in Unicopedia Ægypta:
- Hieroglyph Picture Book
- Hieroglyph Taxonomy
🔗 https://codeberg.org/tonton-pixel/unicopedia-aegypta
#unicopedia #egyptian #hieroglyphs #taxonomy #picturebook #javascript #desktopapplication #electronjs #unicode
ALT text
Hieroglyph Picture Book utility screenshot
ALT text
Hieroglyph Taxonomy utility screenshot
@mikaeru@mastodon.social
In case my feedback to the UTC gets garbled once again, here are the links to the plain text messages I attempted to submit through copy-paste from their new contact page <https://support.unicode.org/osticket/open.php>: no truly WYSIWYG editor, no basic preview mode either...
https://tonton-pixel.codeberg.page/PRI-519-Feedback-2025-05-19.txt
https://tonton-pixel.codeberg.page/PRI-519-Feedback-2025-05-18.txt
https://tonton-pixel.codeberg.page/PRI-519-Feedback-2025-05-13.txt
I'm dreaming of a simple world without technology wanting to "help" us so much. We shouldn't have to struggle to achieve simple tasks...
@mikaeru@mastodon.social
In case my feedback to the UTC gets garbled once again, here are the links to the plain text messages I attempted to submit through copy-paste from their new contact page <https://support.unicode.org/osticket/open.php>: no truly WYSIWYG editor, no basic preview mode either...
https://tonton-pixel.codeberg.page/PRI-519-Feedback-2025-05-19.txt
https://tonton-pixel.codeberg.page/PRI-519-Feedback-2025-05-18.txt
https://tonton-pixel.codeberg.page/PRI-519-Feedback-2025-05-13.txt
I'm dreaming of a simple world without technology wanting to "help" us so much. We shouldn't have to struggle to achieve simple tasks...
@mikaeru@mastodon.social
From time to time (since this represents a tremendous amount of translation/adaptation work), a French version of the "code charts" gets published by the Unicode Consortium: the latest one is for Unicode 16.0:
https://www.unicode.org/Public/16.0.0/charts/fr/CodeCharts.pdf
This is especially useful for French speakers in #Canada, #France, #Belgium, #Switzerland, etc. but may soon be obsolete for #Quebec, in case it gets "absorbed" by a neighboring country whose official language is now English only...
@mikaeru@mastodon.social
From time to time (since this represents a tremendous amount of translation/adaptation work), a French version of the "code charts" gets published by the Unicode Consortium: the latest one is for Unicode 16.0:
https://www.unicode.org/Public/16.0.0/charts/fr/CodeCharts.pdf
This is especially useful for French speakers in #Canada, #France, #Belgium, #Switzerland, etc. but may soon be obsolete for #Quebec, in case it gets "absorbed" by a neighboring country whose official language is now English only...
@mikaeru@mastodon.social
De temps en temps (cela représente un énorme travail d'adaptation), une version française des "code charts" est publiée par le Consortium Unicode, la dernière en date est pour Unicode 16.0:
https://www.unicode.org/Public/16.0.0/charts/fr/CodeCharts.pdf
Malheureusement, celle-ci risque d'être bientôt obsolète pour les francophones de la belle province de Québec, dans le cas où celle-ci serait «absorbée» par un pays voisin dont la langue officielle est désormais uniquement l'anglais...
@mikaeru@mastodon.social
De temps en temps (cela représente un énorme travail d'adaptation), une version française des "code charts" est publiée par le Consortium Unicode, la dernière en date est pour Unicode 16.0:
https://www.unicode.org/Public/16.0.0/charts/fr/CodeCharts.pdf
Malheureusement, celle-ci risque d'être bientôt obsolète pour les francophones de la belle province de Québec, dans le cas où celle-ci serait «absorbée» par un pays voisin dont la langue officielle est désormais uniquement l'anglais...
@SteveFaulkner@mastodon.social
👁️short note on emoji text alternative variations
"Unicode symbols do not have inbuilt text alternatives. They are exposed in the browser accessibility tree as a text symbol"
#emoji #screenreaders #a11y #unicode #webDev
https://html5accessibility.com/stuff/2022/01/17/short-note-on-emoji-text-alternative-variations/

html5accessibility.com
short note on emoji text alternative variations – HTML Accessibility
@SteveFaulkner@mastodon.social
👁️short note on emoji text alternative variations
"Unicode symbols do not have inbuilt text alternatives. They are exposed in the browser accessibility tree as a text symbol"
#emoji #screenreaders #a11y #unicode #webDev
https://html5accessibility.com/stuff/2022/01/17/short-note-on-emoji-text-alternative-variations/
html5accessibility.com
short note on emoji text alternative variations – HTML Accessibility
@SteveFaulkner@mastodon.social
👁️short note on emoji text alternative variations
"Unicode symbols do not have inbuilt text alternatives. They are exposed in the browser accessibility tree as a text symbol"
#emoji #screenreaders #a11y #unicode #webDev
https://html5accessibility.com/stuff/2022/01/17/short-note-on-emoji-text-alternative-variations/
html5accessibility.com
short note on emoji text alternative variations – HTML Accessibility
@mikaeru@mastodon.social
Unicopedia Anatolica is a developer-oriented set of #Unicode utilities related to Anatolian hieroglyphs, wrapped into one single app, built with #Electron.
Repository: 🔗 https://codeberg.org/tonton-pixel/unicopedia-anatolica
#anatolian #hieroglyphs #unicopedia #javascript #unicode #characters #codepoints #codecharts #desktopapplication #electronjs #glyphs #localfonts
ALT text
Unicopedia Anatolica Social Preview
@mikaeru@mastodon.social
Unicopedia Anatolica is a developer-oriented set of #Unicode utilities related to Anatolian hieroglyphs, wrapped into one single app, built with #Electron.
Repository: 🔗 https://codeberg.org/tonton-pixel/unicopedia-anatolica
#anatolian #hieroglyphs #unicopedia #javascript #unicode #characters #codepoints #codecharts #desktopapplication #electronjs #glyphs #localfonts
ALT text
Unicopedia Anatolica Social Preview
@mikaeru@mastodon.social
Considerations about Egyptian Hieroglyph legacy characters, by Michel Suignard, proposing to add a new kEH_AltMapping property to the Unikemet database (UAX#57):
ALT text
Examples of Egyptian hieroglyph variants: 𓃺𓃹 𓅩𓅨 𓅫𓅪 𓂩𓂧
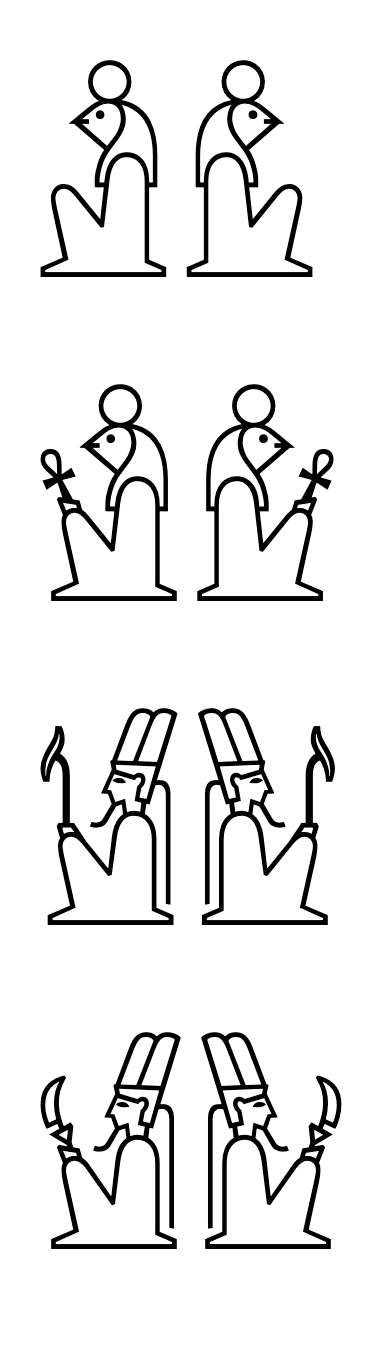
ALT text
Examples of pairs of horizontally mirrored Egyptian hieroglyphs: 𓁜𓁝 𓁛𓁞 𓁩𓁪 𓁫𓁬
@mikaeru@mastodon.social
Unicopedia Ægypta is a developer-oriented set of #Unicode utilities related to Egyptian hieroglyphs, wrapped into one single app, built with #Electron.
Repository: 🔗 https://codeberg.org/tonton-pixel/unicopedia-aegypta
#characters #codecharts #codepoints #desktopapplication #egyptian #electronjs #glyphs #hieroglyph #hieroglyphs #javascript #localfonts #unicode #unicopedia #unikemet
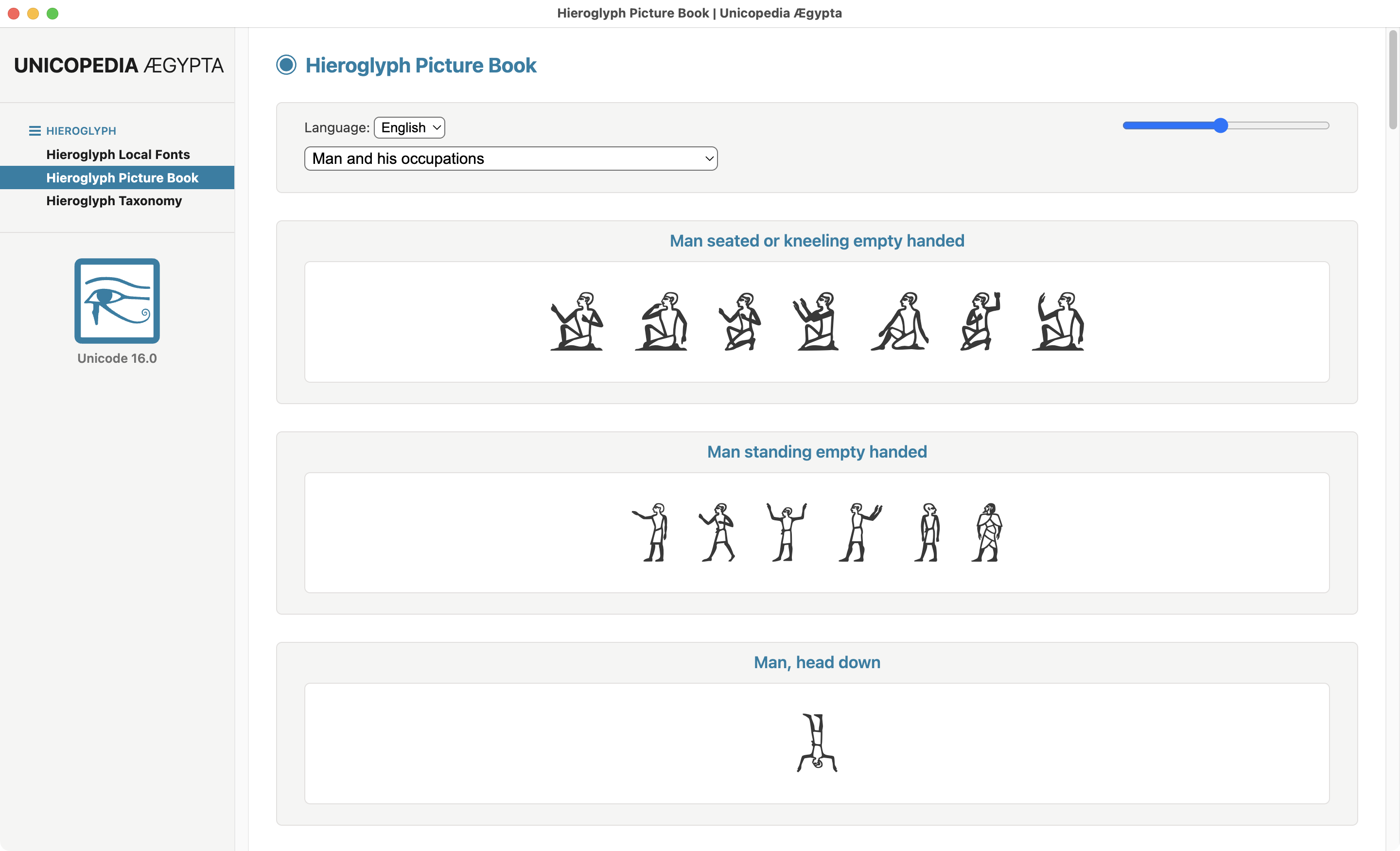
ALT text
Unicopedia Ægypta Social Preview
@mikaeru@mastodon.social
Unicopedia Plus is a developer-oriented set of Unicode, Unihan, Unikemet & emoji utilities wrapped into one single app, built with #Electron.
Repository: 🔗 https://codeberg.org/tonton-pixel/unicopedia-plus
#characters #chinese #cjk #codepoints #desktopapplication #electronjs #emoji #ivd #japanese #javascript #kangxi #kangxiradicals #korean #normalization #opensource #regex #segmentation #strokecount #unicode #unicopedia #unihan #unikemet

ALT text
Unicopedia Plus Social Preview
@mikaeru@mastodon.social
Unicopedia Sinica is a developer-oriented set of #Unicode utilities related to ideographs, wrapped into one single app, built with #Electron.
Repository: 🔗 https://codeberg.org/tonton-pixel/unicopedia-sinica
#characters #chinese #cjk #cjkrelated #cjkv #codecharts #codepoints #components #confusables #desktopapplication #electronjs #glyphs #ideographs #ideographicdescriptionsequences #ids #japanese #javascript #kangxi #kangxiradicals #korean #localfonts #opensource #strokes #tangut #unicode #unicopedia #unihan #vietnamese

ALT text
Unicopedia Sinica Social Preview
@mikaeru@mastodon.social
U+2640 FEMALE SIGN
U+2642 MALE SIGN
U+26A2 DOUBLED FEMALE SIGN
U+26A3 DOUBLED MALE SIGN
U+26A4 INTERLOCKED FEMALE AND MALE SIGN
U+26A5 MALE AND FEMALE SIGN
U+26A6 MALE WITH STROKE SIGN
U+26A7 MALE WITH STROKE AND MALE AND FEMALE SIGN
U+26A8 VERTICAL MALE WITH STROKE SIGN
U+26A9 HORIZONTAL MALE WITH STROKE SIGN
U+26B2 NEUTER
ALT text
Unicode Symbols: Diversity ♀♂⚢⚣⚤⚥⚦⚧⚨⚩⚲
@mikaeru@mastodon.social
#Unicode #Emoji: #Hearts #Galore
U+2764 U+FE0F U+1FA77 U+1F9E1 U+1F49B U+1F49A U+1F499 U+1FA75 U+1F49C U+1F90E U+1F5A4 U+1FA76 U+1F90D
U+1F49F U+2764 U+FE0F U+200D U+1F525 U+1F494 U+2764 U+FE0F U+200D U+1FA79 U+2763 U+FE0F U+1F498 U+1F493 U+1F497 U+1F496 U+1F49D U+1F495 U+1F49E
U+1F970 U+1F60D U+1F618 U+1F63B U+1F48C U+1FAF6 U+1FAF6 U+1F3FB U+1FAF6 U+1F3FC U+1FAF6 U+1F3FD U+1FAF6 U+1F3FE U+1FAF6 U+1F3FF U+1FAC0
ALT text
Unicode Emoji: Hearts Galore ❤️🩷🧡💛💚💙🩵💜🤎🖤🩶🤍 💟❤️🔥💔❤️🩹❣️💘💓💗💖💝💕💞 🥰😍😘😻💌🫶🫶🏻🫶🏼🫶🏽🫶🏾🫶🏿🫀
@mikaeru@mastodon.social
@mikaeru@mastodon.social
U+1F473 U+1F473 U+1F3FB U+1F473 U+1F3FC U+1F473 U+1F3FD U+1F473 U+1F3FE U+1F473 U+1F3FF
U+1F478 U+1F478 U+1F3FB U+1F478 U+1F3FC U+1F478 U+1F3FD U+1F478 U+1F3FE U+1F478 U+1F3FF
ALT text
Unicode Emoji: Skin Tones 👳➔👳🏻👳🏼👳🏽👳🏾👳🏿 👸➔👸🏻👸🏼👸🏽👸🏾👸🏿
@mikaeru@mastodon.social
#Unicode #Emoji: #Math #Geekiness
<U+1F605> <U+1F4A7> <U+1F604>
ALT text
Unicode Emoji: Math Geekiness log(😅) =💧log(😄)
@mikaeru@mastodon.social
@liilliil@im-in.space
Offering a new #FediverseSymbol: ꙮ
The previously suggested symbol ⁂ is good for depict group and unity, but is poor in terms of associations: “3 snowflakes”.
Polish fediusers have noticed a piece of an old Russian manuscript, it says about ‘many-eyed seraphim’ (серафим многоокий). An unknown 15th-century monk played with the combination of the letters oo, turning them into a multi-eyed creature. The character found in only 1 manuscript, but despite this, it has been added into #Unicode.
Not only does the symbol beautifully reflect the unity of the fediverse, but it also shows an all-seeing open-minded wise and powerful being (Ezekiel 1:18, 10:12 etc)

@achadwick@urbanists.social
Hey, fedi #Unicode nerds! 
#OpenStreetMap's Andy Mabbett (@Pigsonthewing) is asking whether anyone knows about any instances of the #OrdnanceSurvey's bench mark symbol appearing in actual print, on a page. Looks a bit like ⭱ or ⤒ but a broader arrow. Usually found carved on stone or brick all over the UK/ROI.
Their goal is to propose it as a Unicode symbol! https://community.openstreetmap.org/t/os-bench-mark-symbol-in-printed-documents/128182
Any known international usage of this symbol would doubtless be appreciated too

ALT text
A non-print example. The most common form of the symbol, although other variants exist. It's carved into a smooth block of stone on the side of a building or monument plinth, and it looks like a capital T with an upside down V overlaid onto it so that the two angled lines from the V come together with the T's vertical stroke to meet its horizontal stroke at a single point. All the bottom lines taper toward that point. Looking at it another way, it's a horizontal line with an arrow pointing at it, saying "here, this level!" They were used for marking height reference points during various surveys of the British isles. Photo by Mike Taylor on geograph.org.uk, CC:by

ALT text
Another non-print example. This is another form of the symbol. I don't know how common. This one's a pre-cast metal (?) plaque with a serial number set into a wall. The arrow lacks the top bar, but above it, along with the O and S of Ordnance Survey, are some very specific-looking slots. Perhaps the slots accepted some sort of surveying equipment. Photo by Gary Rogers on geograph. Links can be found in this thread below.
@achadwick@urbanists.social
Hey, fedi #Unicode nerds!
#OpenStreetMap's Andy Mabbett (@Pigsonthewing) is asking whether anyone knows about any instances of the #OrdnanceSurvey's bench mark symbol appearing in actual print, on a page. Looks a bit like ⭱ or ⤒ but a broader arrow. Usually found carved on stone or brick all over the UK/ROI.
Their goal is to propose it as a Unicode symbol! https://community.openstreetmap.org/t/os-bench-mark-symbol-in-printed-documents/128182
Any known international usage of this symbol would doubtless be appreciated too
ALT text
A non-print example. The most common form of the symbol, although other variants exist. It's carved into a smooth block of stone on the side of a building or monument plinth, and it looks like a capital T with an upside down V overlaid onto it so that the two angled lines from the V come together with the T's vertical stroke to meet its horizontal stroke at a single point. All the bottom lines taper toward that point. Looking at it another way, it's a horizontal line with an arrow pointing at it, saying "here, this level!" They were used for marking height reference points during various surveys of the British isles. Photo by Mike Taylor on geograph.org.uk, CC:by
ALT text
Another non-print example. This is another form of the symbol. I don't know how common. This one's a pre-cast metal (?) plaque with a serial number set into a wall. The arrow lacks the top bar, but above it, along with the O and S of Ordnance Survey, are some very specific-looking slots. Perhaps the slots accepted some sort of surveying equipment. Photo by Gary Rogers on geograph. Links can be found in this thread below.
@mikaeru@mastodon.social · Reply to Michel Mariani
Today (April Fools' Day), Adobe is apparently back to the list of full members (voting) of the Unicode Consortium, but for how long this time: one full year?
« Ça s’en va et ça revient
C’est fait de tout petits riens
Ça se chante et ça se danse
Et ça revient, ça se retient
Comme une chanson populaire »
Full members (voting) of the Unicode Consortium: Adobe, Airbnb, Amazon, Apple, Google, Meta, Microsoft, Salesforce, Translated.
ALT text
Full members (voting) of the Unicode Consortium: Adobe, Airbnb, Amazon, Apple, Google, Meta, Microsoft, Salesforce, Translated.
@SnoopJ@hachyderm.io
the most important part of #Unicode history is when a mouse fell out of a light fixture and got added to the count of members present at a Technical Committee meeting (9 Nov 2016)
ALT text
Screenshot of meeting notes for UTC Meeting 149. Text reads: Mouse now present. 6.502 members represented. [149-A94] Action Item for Landlord: Capture and exile the mouse that just fell out of the light fixture.
@Edent@mastodon.social
Which is your favourite #Unicode telephone?
- 🕾1 (1%)
- 🕿5 (7%)
- ☏18 (27%)
- ☎43 (64%)
@Edent@mastodon.social
Which is your favourite #Unicode telephone?
- 🕾1 (1%)
- 🕿5 (7%)
- ☏18 (27%)
- ☎43 (64%)
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@sibaku@mas.to
Found out something interesting/annoying related to #unicode! There is an issue with the character 浅. You might see it one of two ways (see screenshots) depending on which font you use, which was the cause of my confusion. One form has 2 and the other 3 horizontal strokes. So why is that?

ALT text
The simplified Chinese Hanzi equivalent of 浅

ALT text
The Japanese kanji 浅
@mikaeru@mastodon.social
The Ideographic Research Group (IRG) is responsible for preparing and reviewing sets of CJK unified ideographs to be included in the Unicode Standard.
The IRG homepage is now including comprehensive lists of current and future IRG source prefixes...
unicode.org
Ideographic Research Group
@yngvem@fosstodon.org
It's happening, @marieroald and I are doing our third #PyConUS, this time with a tutorial on Packaging with uv and a talk about #Unicode in #Python!
@yngvem@fosstodon.org
It's happening, @marieroald and I are doing our third #PyConUS, this time with a tutorial on Packaging with uv and a talk about #Unicode in #Python!
@sibaku@mas.to
Found out something interesting/annoying related to #unicode! There is an issue with the character 浅. You might see it one of two ways (see screenshots) depending on which font you use, which was the cause of my confusion. One form has 2 and the other 3 horizontal strokes. So why is that?
ALT text
The simplified Chinese Hanzi equivalent of 浅
ALT text
The Japanese kanji 浅

@doctormo@floss.social
It might have taken an ungodly amount of time. But getting these corner cases right in this PDF export is going to mean the world to a lot of people.
Arabic and Hebrew and non messing up the glyphs.
#inkscape #pdf #cmyk #arabic #language #unicode #text #glyphs #hewbrew

ALT text
Sample Text on three PDF pages read: מילים נסתרות كلمات مخفية مرحبا بالعالم "Text on Path" curved on a thick line "تجربة نص على المنحى" curved on a thin line "What is Lorem Ipsum?" ... full text explaining lorum ipsum flowing around a large lack circle ... "Can we do Arabic?" ... A passage in arabic from the Quran flowing around a smaller black circle ...
@doctormo@floss.social
It might have taken an ungodly amount of time. But getting these corner cases right in this PDF export is going to mean the world to a lot of people.
Arabic and Hebrew and non messing up the glyphs.
#inkscape #pdf #cmyk #arabic #language #unicode #text #glyphs #hewbrew
ALT text
Sample Text on three PDF pages read: מילים נסתרות كلمات مخفية مرحبا بالعالم "Text on Path" curved on a thick line "تجربة نص على المنحى" curved on a thin line "What is Lorem Ipsum?" ... full text explaining lorum ipsum flowing around a large lack circle ... "Can we do Arabic?" ... A passage in arabic from the Quran flowing around a smaller black circle ...
@jake4480@c.im
Some Pac-Man and other alien space invadery type symbols now in Unicode, via this Symbols for Legacy Computing Supplement: https://unicode.org/charts//PDF/Unicode-16.0/U160-1CC00.pdf

ALT text
A portion from the linked PDF of Unicode symbols showing Pac-Man and Space Invaders type symbols
@jake4480@c.im
Some Pac-Man and other alien space invadery type symbols now in Unicode, via this Symbols for Legacy Computing Supplement: https://unicode.org/charts//PDF/Unicode-16.0/U160-1CC00.pdf
ALT text
A portion from the linked PDF of Unicode symbols showing Pac-Man and Space Invaders type symbols
@jake4480@c.im
Some Pac-Man and other alien space invadery type symbols now in Unicode, via this Symbols for Legacy Computing Supplement: https://unicode.org/charts//PDF/Unicode-16.0/U160-1CC00.pdf
ALT text
A portion from the linked PDF of Unicode symbols showing Pac-Man and Space Invaders type symbols
@phrawzty@hachyderm.io
Today I learned that there is a specific #unicode "record separator" symbol, formally known as "U+001E Information Separator Two".
It is meant to be used to indicate a separation between two units of information. An example of where this could be used is in a separated-value file, e.g. a CSV, but using this symbol instead of a comma.
This is interesting because there are vanishingly few instances where the record separator symbol would appear in most contexts, but many instances where a comma appears. Using this symbol instead of a comma (or a semi-colon, or an exclamation point, or any one of the usual separators) could make some data hygiene scenarios much more straightforward.
codepoints.net
U+001E INFORMATION SEPARATOR TWO*: ␞ – Unicode
␞, codepoint U+001E INFORMATION SEPARATOR TWO* in Unicode, is located in the block “Basic Latin”. It belongs to the Common script and is a Control.
@phrawzty@hachyderm.io
Today I learned that there is a specific #unicode "record separator" symbol, formally known as "U+001E Information Separator Two".
It is meant to be used to indicate a separation between two units of information. An example of where this could be used is in a separated-value file, e.g. a CSV, but using this symbol instead of a comma.
This is interesting because there are vanishingly few instances where the record separator symbol would appear in most contexts, but many instances where a comma appears. Using this symbol instead of a comma (or a semi-colon, or an exclamation point, or any one of the usual separators) could make some data hygiene scenarios much more straightforward.
codepoints.net
U+001E INFORMATION SEPARATOR TWO*: ␞ – Unicode
␞, codepoint U+001E INFORMATION SEPARATOR TWO* in Unicode, is located in the block “Basic Latin”. It belongs to the Common script and is a Control.
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@xtaran@chaos.social
#UserAgent based banning of #textmode browsers is sooooo lame.
$ lynx -useragent=🖕 https://[…]
@thias@mastodon.social
Treasure Hunt – Braille Hints
So I prepared a treasure hunt for my older daughter, which involved some form of coded message. I found a braille table I could 3D-print, using a real system instead of some made-up code gave me the opportunity to explain how/why this was used in reality, you find braille codes in lifts, staircase handrails.

wiesmann.codiferes.net
Treasure Hunt – Braille Hints
So I prepared a treasure hunt for my older daughter, which involved some form of coded message. I found a braille table I could 3D-print, using a real system instead of some made-up code gave me th…
@ausir@meowr.me
brand new combining diacritics dropping soon in Unicode 17, to be used for transcribing rare historical uses, and even more so for really tryhard conlangs!
@simontatham@hachyderm.io
In the old #ASCII days, you could change a letter between upper and lower case by XORing its character code with 0x20. Of course, if you tried this with anything that wasn't a letter, you'd get nonsense results.
If you try that with #Unicode code points, it sometimes works, and sometimes doesn't. But Unicode can deliver much more impressive nonsense when it doesn't.
A fun example I just found: the "lower-case" version of CAR is NO PEDESTRIANS.
>>> chr(ord('🚗') ^ 0x20)
'🚷'
@ptmcg@fosstodon.org
@simontatham@hachyderm.io
In the old #ASCII days, you could change a letter between upper and lower case by XORing its character code with 0x20. Of course, if you tried this with anything that wasn't a letter, you'd get nonsense results.
If you try that with #Unicode code points, it sometimes works, and sometimes doesn't. But Unicode can deliver much more impressive nonsense when it doesn't.
A fun example I just found: the "lower-case" version of CAR is NO PEDESTRIANS.
>>> chr(ord('🚗') ^ 0x20)
'🚷'
@simontatham@hachyderm.io
In the old #ASCII days, you could change a letter between upper and lower case by XORing its character code with 0x20. Of course, if you tried this with anything that wasn't a letter, you'd get nonsense results.
If you try that with #Unicode code points, it sometimes works, and sometimes doesn't. But Unicode can deliver much more impressive nonsense when it doesn't.
A fun example I just found: the "lower-case" version of CAR is NO PEDESTRIANS.
>>> chr(ord('🚗') ^ 0x20)
'🚷'
@simontatham@hachyderm.io
In the old #ASCII days, you could change a letter between upper and lower case by XORing its character code with 0x20. Of course, if you tried this with anything that wasn't a letter, you'd get nonsense results.
If you try that with #Unicode code points, it sometimes works, and sometimes doesn't. But Unicode can deliver much more impressive nonsense when it doesn't.
A fun example I just found: the "lower-case" version of CAR is NO PEDESTRIANS.
>>> chr(ord('🚗') ^ 0x20)
'🚷'
@simontatham@hachyderm.io
In the old #ASCII days, you could change a letter between upper and lower case by XORing its character code with 0x20. Of course, if you tried this with anything that wasn't a letter, you'd get nonsense results.
If you try that with #Unicode code points, it sometimes works, and sometimes doesn't. But Unicode can deliver much more impressive nonsense when it doesn't.
A fun example I just found: the "lower-case" version of CAR is NO PEDESTRIANS.
>>> chr(ord('🚗') ^ 0x20)
'🚷'
@simontatham@hachyderm.io
In the old #ASCII days, you could change a letter between upper and lower case by XORing its character code with 0x20. Of course, if you tried this with anything that wasn't a letter, you'd get nonsense results.
If you try that with #Unicode code points, it sometimes works, and sometimes doesn't. But Unicode can deliver much more impressive nonsense when it doesn't.
A fun example I just found: the "lower-case" version of CAR is NO PEDESTRIANS.
>>> chr(ord('🚗') ^ 0x20)
'🚷'
@simontatham@hachyderm.io
In the old #ASCII days, you could change a letter between upper and lower case by XORing its character code with 0x20. Of course, if you tried this with anything that wasn't a letter, you'd get nonsense results.
If you try that with #Unicode code points, it sometimes works, and sometimes doesn't. But Unicode can deliver much more impressive nonsense when it doesn't.
A fun example I just found: the "lower-case" version of CAR is NO PEDESTRIANS.
>>> chr(ord('🚗') ^ 0x20)
'🚷'
@fmeerkoetter@mountains.social
Love this book/comic the kids picked up from the library.


@fmeerkoetter@mountains.social
Love this book/comic the kids picked up from the library.
@mrdk@mathstodon.xyz · Reply to 0xDE
@11011110 At least these symbols have a meaning! But nobody knows what “Angzarr” (⍼) is and why it is in Unicode (https://en.wikipedia.org/wiki/Angzarr).
en.wikipedia.org
Angzarr - Wikipedia
@mrdk@mathstodon.xyz · Reply to 0xDE
@11011110 At least these symbols have a meaning! But nobody knows what “Angzarr” (⍼) is and why it is in Unicode (https://en.wikipedia.org/wiki/Angzarr).
en.wikipedia.org
Angzarr - Wikipedia

@revathskumar@fosstodon.org · Reply to Revath S Kumar :javascript:
Wrote a small web utility to visualize the different string normalization forms of a text.
https://string-normalize.surge.sh/?str=I+%e2%99%a5+K%c3%b6ln
Not the best design 😄 , but feedbacks are welcome.
ALT text
desktop view of string normalize web page, showing NFC, NFD, NFKC and NFKD normalization forms of text "I ♥ Köln" is visible
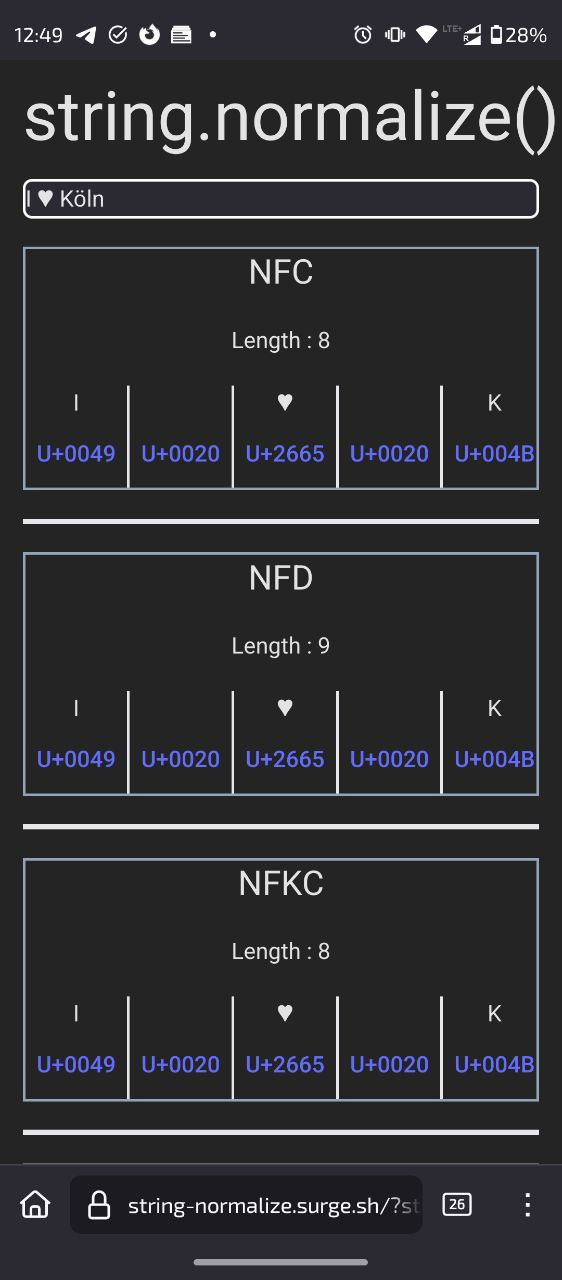
ALT text
mobile view of string normalize web page, showing NFC, NFD and NFKC normalization forms of text "I ♥ Köln" is visible
@mikaeru@mastodon.social
New utility in Unicopedia Sinica:
- Pan-CJK Font Variants
(port from Unicopedia Plus, with Serif/明朝体 font style instead of Sans-Serif/ゴシック体)
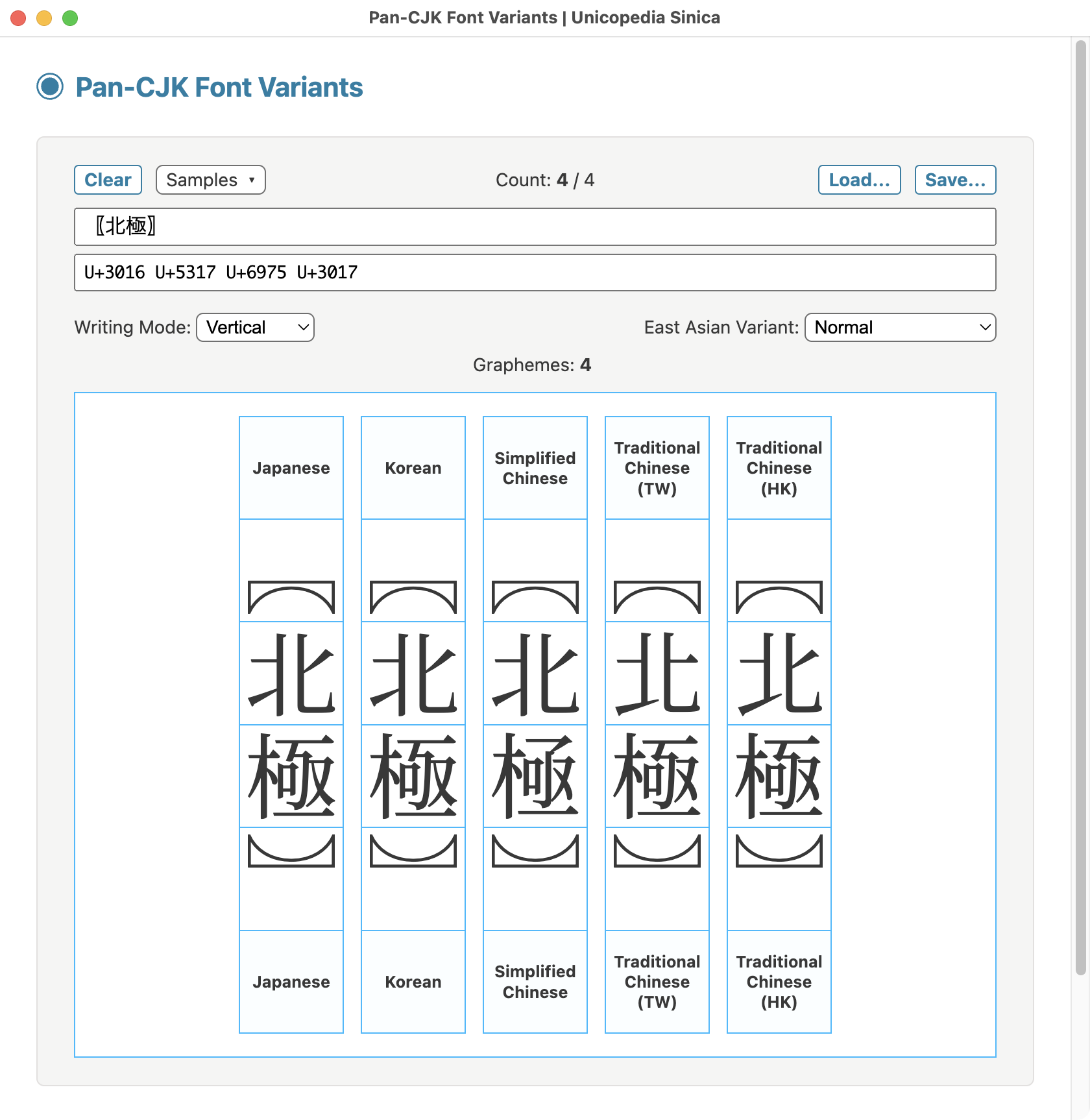
ALT text
Pan-CJK Font Variants utility screenshot
@mikaeru@mastodon.social
New utility in Unicopedia Plus:
- Unihan Phonetics
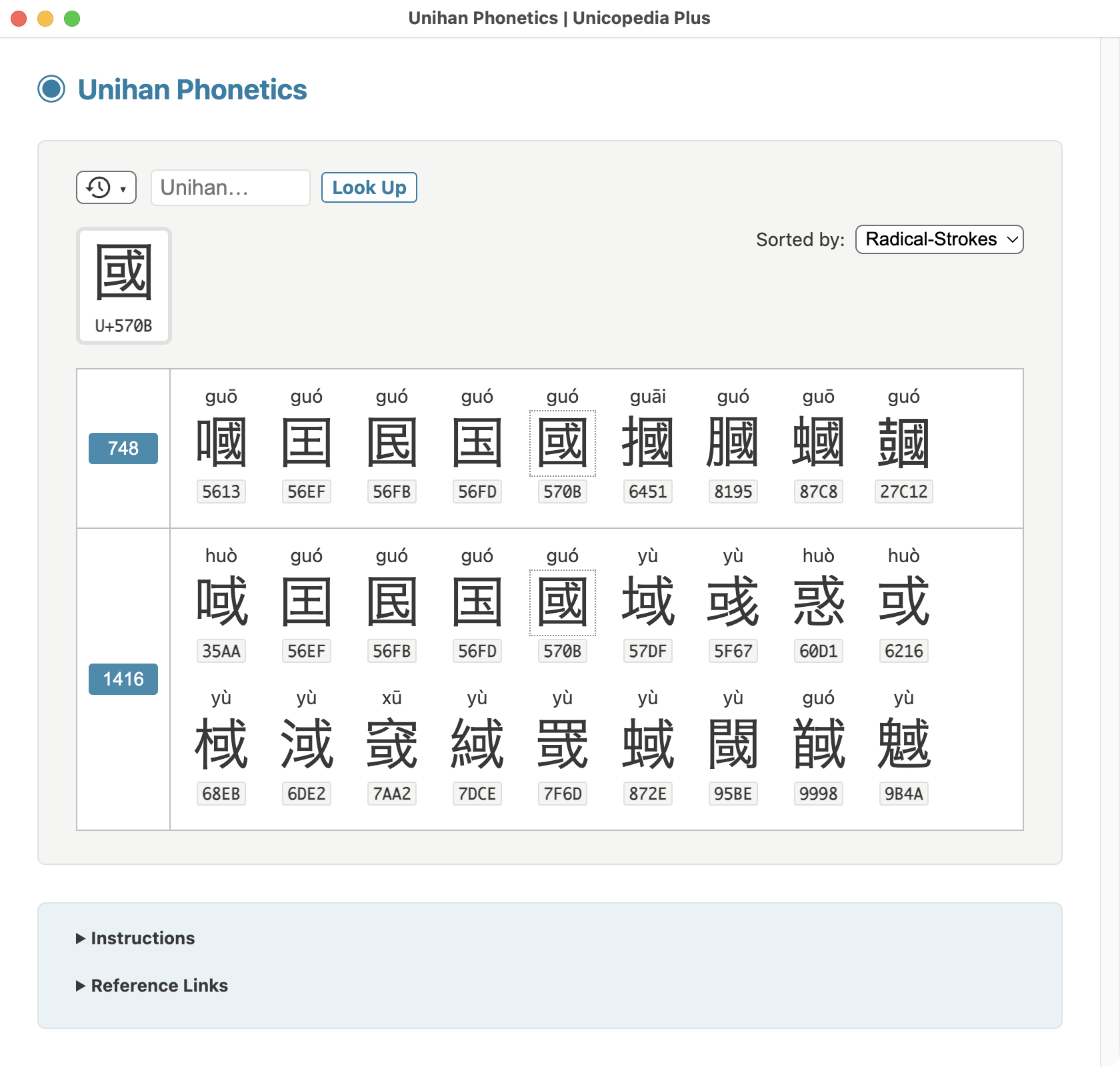
ALT text
Unihan Phonetics utility screenshot
@revathskumar@fosstodon.org · Reply to Revath S Kumar :javascript:
Wrote a small web utility to visualize the different string normalization forms of a text.
https://string-normalize.surge.sh/?str=I+%e2%99%a5+K%c3%b6ln
Not the best design 😄 , but feedbacks are welcome.
ALT text
desktop view of string normalize web page, showing NFC, NFD, NFKC and NFKD normalization forms of text "I ♥ Köln" is visible
ALT text
mobile view of string normalize web page, showing NFC, NFD and NFKC normalization forms of text "I ♥ Köln" is visible
@SnoopJ@hachyderm.io
have you ever "naturally" (i.e. not discussion among #Unicode experts) encountered a font that correctly renders ꙮ?
- yes0 (0%)
- no0 (0%)
- what the hell are you talking about0 (0%)
@revathskumar@fosstodon.org
New blog post : "JavaScript : understanding string normalize"
https://blog.revathskumar.com/2025/01/javascript-understanding-string-normalize.html
blog.revathskumar.com
JavaScript : understanding string normalize
JavaScript : understanding string normalize and different normalization forms
 Qiita - 人気の記事
Qiita - 人気の記事@qiita@rss-mstdn.studiofreesia.com

@qiita@rss-mstdn.studiofreesia.com
[謹賀新年] 世界中に配置した Oracle Active Data Guard から新年のご挨拶
https://qiita.com/shirok/items/1da55c23b33c5228049a?utm_campaign=popular_items&utm_medium=feed&utm_source=popular_items

qiita.com
[謹賀新年] 世界中に配置した Oracle Active Data Guard から新年のご挨拶 - Qiita
謹賀新年世界各国の言葉で新年のご挨拶をお届けします!Oracle Active Data Guard 19c では、スタンバイ・データベースで DML(INSERT/UPDATE/DELETE)…
@ptmcg@fosstodon.org · Reply to Axel Rauschmayer
@rauschma Ah! I did something similar in Python - this is valid Python code:
def ℎ𝕖𝐥l𝙤():
try:
ℎ𝙚𝕝𝗹𝘰_ = "Hello"
w𝔬𝓇ˡ𝚍﹎ = "World"
𝖕𝘳𝒊𝖓𝑡(f"{𝗵𝒆𝘭𝓵𝚘﹍}, {𝑤º𝘳l𝑑︴}!")
except T𝗒ₚ𝕖E𝗿𝗋𝗈𝓻 as ᵉ𝒙ⅽ:
𝐩ᵣ𝚒𝖓𝓉("failed: {}".𝕗𝕠r𝑚𝖺𝘵(ⅇ𝔵𝚌))
if _︳n𝗮𝖒𝓮﹍︳ == "__main__":
h𝙚ⅼ𝐥𝕠()
ptmcg.pythonanywhere.com
ᴾ𝘆𝙩𝚑𝓸𝔫 𝐹º𝑛t 𝘔ⅸᵉ𝐫
@vwbusguy@mastodon.online
"This coding interview is just going to be determining the human friendly length of a unicode utf-8 string."
Junior level dev: "Oh, this is going to be easy. How do they not know about len()?"
Senior level dev: "Oh, brilliant - a test of tolerance for pain by evaluating various code point chains with emoji, accents, and LTR/RTL markers. I'll start by writing some tests for 8-bit ord and char conversions with lookahead evals."

ALT text
Python docs showing how the same one letter can count for one or two character lengths in unicode depending on the code point definition.
@vwbusguy@mastodon.online
"This coding interview is just going to be determining the human friendly length of a unicode utf-8 string."
Junior level dev: "Oh, this is going to be easy. How do they not know about len()?"
Senior level dev: "Oh, brilliant - a test of tolerance for pain by evaluating various code point chains with emoji, accents, and LTR/RTL markers. I'll start by writing some tests for 8-bit ord and char conversions with lookahead evals."
ALT text
Python docs showing how the same one letter can count for one or two character lengths in unicode depending on the code point definition.
@omgubuntu@floss.social
Ubuntu LTS users will shortly be able to see and use the 8 new emoji included in Unicode 16.0.
https://www.omgubuntu.co.uk/2024/12/ubuntu-update-support-for-emoji-16-0
@mikaeru@mastodon.social
In the open-source application `Unicopedia Sinica`, both data files used for the `CJK Components` and the `CJK Related` utilities are now in a consistent JSON format with MIT license: `cjk-ids.json` and `cjk-related.json` respectively.

ALT text
CJK Related utility screenshot

ALT text
CJK Components utility screenshot
ALT text
CJK Related utility screenshot
@SnoopJ@hachyderm.io
HUH, #Unicode UAX#31 offers official guidance on hashtag identifiers, and I have somehow managed to miss that completely for several years (introduced along with Unicode 11.0 in 2018).
https://www.unicode.org/reports/tr31/#hashtag_identifiers
It's not like I re-read the whole document regularly or anything but yea huh
@amake@mastodon.social · Reply to Aaron “#e14n pro” Madlon-Kay
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@eniko@peoplemaking.games
Btw here's a little #gamedev unicode protip: unicode defines several character ranges as private use areas. You can map code points in these ranges to whatever glyph you want. This can be very handy for custom characters in your game that won't conflict with established unicode characters
In our games we use the PUA for keyboard and controller button glyphs
@ausir@meowr.me
brand new combining diacritics dropping soon in Unicode 17, to be used for transcribing rare historical uses, and even more so for really tryhard conlangs!
@emnullfuenf@chaos.social
My study "Unicode Spaces" will be published in Slanted Magazine - Experimental Type 3!

ALT text
Listing of Unicode white space characters

ALT text
Steamboat Willy formed with whitespaces in text.

ALT text
Flower formed with whitespaces in text.
@mro@digitalcourage.social · Reply to zirias (on snac)
@zirias @stefano #hashtags are #unicode defined: https://www.unicode.org/reports/tr31/#D2
read 'em like this https://codeberg.org/seppo/seppo/src/commit/87bf300/lib/tag.ml#L31
@Edent@mastodon.social
iOS 14 gets support for the Unicode Power Symbol!
https://shkspr.mobi/blog/2020/09/ios-14-gets-support-for-the-power-symbol/
@jdlh@mstdn.ca · Reply to Jim DeLaHunt
A cool change is that the Core Specification of the Unicode Standard is now released as a static HTML subsite, backed up by an archiveable #PDF of 1,140 pages.
https://unicode.org/versions/Unicode16.0.0/core-spec/
You can now link to specific sections and paragraphs, e.g.
"Unicode is about plain text, see: https://unicode.org/versions/Unicode16.0.0/core-spec/chapter-2/#G642" .
I helped out in a small way with the project to produce the core spec as HTML + PDF. I think it is a marvellous improvement.
@jdlh@mstdn.ca
@liilliil@mastodon.online
Народ, айда форсить наш, славянский, кириллический #fediverseSymbol!
«Три снежинки» — ⁂ — потенциальный повод для многочисленных подъёбок
Польские ребята (@brie) нашли лучшего кандидата — ꙮ, «серафим многꙮкий». Символ, найденный в 1928 году только в одной (!) рукописи, и только из-за этого (!) добавленный в #Unicode несколько веков ждал своего часа
https://ru.wikipedia.org/wiki/Мультиокулярная_О
(English version https://im-in.space/@liilliil/113028392518272881 )

@amyfou@lingo.lol
I am a #linguist (non-tenure track, uni) interested in every single thing about #languages, esp #Indigenous ones, #academics & #teaching Side gig in #ComunityBased #LanguageTech (#webdev #React #postgres #hasura #graphQL #nodeJS #nginx #linux #podman #kubernetes #docker #unicode lol). I love #animals and will ask you too many questions about your #dogs #cats #horses #sheep #goats #chickens #bunnies #piggies #cows etc . Proud #UglyDogs fan. Love #nature #birds #photography #art 👋
@hongminhee@fosstodon.org · Reply to 洪 民憙 (Hong Minhee)
@hongminhee@fosstodon.org
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, and @hollo, a fediverse microblog for single users.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文/#漢文)!

@chunshek@prettyaweso.me
#Introduction post for my own Mastodon instance!
• I’m a 44-year-old jack-of-all-trades.
• I grew up in #HongKong, lived in the #US. My partner of 15 years and I moved to #Taiwan in 2020.
• We are “parents” to one remaining dog.
• I speak 6 #languages, and have dabbled in many others.
• Things I will nerd out about: #Unicode, #typography, #typhoons.
• I am a person of faith, but not a fan of organized religions.
• I type in #Dvorak.
• I curate pop music at @soniccruise.

ALT text
A man kneels down next to two tilted mailboxes in Taipei, Taiwan, pretending to be carrying one of the mailboxes on his back.

ALT text
A man standing in front of a wall covered in dozens of containers of various types of instant ramen and udon noodles. The man's facial expression shows amusement.

ALT text
A top-down shot of a man lying down, looking into the eyes of a shiba inu dog. The dog has curled up into a resting position.
ALT text
A man standing in front of a wall covered in dozens of containers of various types of instant ramen and udon noodles. The man's facial expression shows amusement.

ALT text
A man happily holding a ripe yellow pineapple in his left hand, while pointing at the pineapple with his right hand, smiling at the camera.
ALT text
A man kneels down next to two tilted mailboxes in Taipei, Taiwan, pretending to be carrying one of the mailboxes on his back.
ALT text
A man standing in front of a wall covered in dozens of containers of various types of instant ramen and udon noodles. The man's facial expression shows amusement.
ALT text
A top-down shot of a man lying down, looking into the eyes of a shiba inu dog. The dog has curled up into a resting position.
ALT text
A man kneels down next to two tilted mailboxes in Taipei, Taiwan, pretending to be carrying one of the mailboxes on his back.
ALT text
A top-down shot of a man lying down, looking into the eyes of a shiba inu dog. The dog has curled up into a resting position.
@hongminhee@fosstodon.org · Reply to 洪 民憙 (Hong Minhee)
@hongminhee@fosstodon.org
@liilliil@im-in.space
Offering a new #FediverseSymbol: ꙮ
The previously suggested symbol ⁂ is good for depict group and unity, but is poor in terms of associations: “3 snowflakes”.
Polish fediusers have noticed a piece of an old Russian manuscript, it says about ‘many-eyed seraphim’ (серафим многоокий). An unknown 15th-century monk played with the combination of the letters oo, turning them into a multi-eyed creature. The character found in only 1 manuscript, but despite this, it has been added into #Unicode.
Not only does the symbol beautifully reflect the unity of the fediverse, but it also shows an all-seeing open-minded wise and powerful being (Ezekiel 1:18, 10:12 etc)
@xChaos@f.cz
Nebaví vás googlit unicode znaky pro subscript a superscript? Mě už taky ne :-)
Akordy pro psaní horního a dolního indexu (ve smyslu Unicode) na klávesnici Windows se dají snadno vygooglit. Pod Linuxem je to ovšem trochu věda:
1) nejdřív Pravý alt + pravý shift + backspace + 2 (ano, čtyřhmat)
2) potom znak, který má být dolní index, třeba číslovka (což ovšem na české klávesnici, na kterou jste přepnutí, taky s shiftem, takže dvouhmat).
H₂O
Pro horní index ve stejném čtyřhmatu akorát nahradíte tu dvojku trojkou:
a² + b² = c²
Slušné akordy, ne? problém je, že pokud čtyřhmat nedomáčknete přesně (?) tak ten Backspace má tendenci fungovat jako backspace, takže umaže jeden znak... no zkrátka, dělám to pokaždé na několikátý pokus, zatím :-)
Vůbec jsem nepochopil návod
https://www.abclinuxu.cz/blog/kenyho_stesky/2020/8/psani-hornich-a-dolnich-indexu-pres-compose-key
... asi proto, že nevím, která PC klávesa je "compose key", ale v komentářích čtenářů jsem si všiml návodu pro slovenskou klávesnici a funguje mi i pro český layout a tak to předávám dál.
@SnoopJ@hachyderm.io
the most important part of #Unicode history is when a mouse fell out of a light fixture and got added to the count of members present at a Technical Committee meeting (9 Nov 2016)
ALT text
Screenshot of meeting notes for UTC Meeting 149. Text reads: Mouse now present. 6.502 members represented. [149-A94] Action Item for Landlord: Capture and exile the mouse that just fell out of the light fixture.
@nemobis@mamot.fr
Re-#introduction: recurring topics here.
#Wikimedia #Wikidata #Wikipedia #MediaWiki #OpenStreetMap #Wikimania #Wikisource #WikiCite #OpenRefine #wiki #Wiktionary #WikiLovesMonuments #Wikibase #Wikiquote
#i18n #L10n #translatewiki.net #Unicode #CLDR #languages
#Copyright #PublicDomain #PubblicoDominio #Copyleft #CreativeCommons #OpenData #UploadFilters #LicenzaLibera #DatiAperti
#InternetArchive #books #biblioteche #library #Koha #KohaILS #GLAM
#WikiTeam #digipres #ArchiveTeam #XSLT
1/4
@mikaeru@mastodon.social · Reply to Design Brouhaha
Je viens tout juste d'acquérir les cinq premiers numéros d’Unicode à Gogo ! Tous disponibles à la boutique du Musée de l'Imprimerie et de la Communication graphique.
Excellent ! 💮

ALT text
Les cinq premiers numéros d’Unicode à Gogo !
@mikaeru@mastodon.social
Unicopedia Ægypta is a developer-oriented set of #Unicode utilities related to Egyptian hieroglyphs, wrapped into one single app, built with #Electron.
Repository: 🔗 https://codeberg.org/tonton-pixel/unicopedia-aegypta
#characters #codecharts #codepoints #desktopapplication #egyptian #electronjs #glyphs #hieroglyph #hieroglyphs #javascript #localfonts #unicode #unicopedia #unikemet
ALT text
Unicopedia Ægypta Social Preview
@thias@mastodon.social
Treasure Hunt – Braille Hints
So I prepared a treasure hunt for my older daughter, which involved some form of coded message. I found a braille table I could 3D-print, using a real system instead of some made-up code gave me the opportunity to explain how/why this was used in reality, you find braille codes in lifts, staircase handrails.
wiesmann.codiferes.net
Treasure Hunt – Braille Hints
So I prepared a treasure hunt for my older daughter, which involved some form of coded message. I found a braille table I could 3D-print, using a real system instead of some made-up code gave me th…
@mikaeru@mastodon.social · Reply to Michel Mariani
@mikaeru@mastodon.social
@mikaeru@mastodon.social
Beautifully crafted BabelStone Han font, by Andrew West 魏安
#BabelStone Han v. 15.1.3 is a free #Unicode #CJK #font with over 57,000 Han characters (#hanzi, #kanji, #hanja), and 62,061 Unicode characters in total. It is a Song/Ming style (宋体/明體) font, with glyphs modelled on the official character forms used in the People's Republic of China, and is primarily intended for writing Modern Standard #Chinese, Classical Chinese, and various Sinitic languages and dialects.
ALT text
Repeated: 龙 U+9F99 U+31342 U+2EE5D
@Edent@mastodon.social
🆕 blog! “Internationalise The Fediverse”
We live in the future now. It is OK to use Unicode everywhere. It seems bizarre to me that modern Internet services sometimes "forget" that there's a world outside the Anglosphere. Some people have the temerity to speak foreign languages! And some of those languages have accents on their letters!! Even worse, some …
👀 Read more: https://shkspr.mobi/blog/2024/02/internationalise-the-fediverse/
⸻
#ActivityPub #fediverse #i18n #mastodon #unicode
shkspr.mobi
Internationalise The Fediverse
We live in the future now. It is OK to use Unicode everywhere. It seems bizarre to me that modern Internet services sometimes "forget" that there's a world outside the Anglosphere. Some people have the temerity to speak foreign languages! And some of those languages have accents on their letters!! Even worse, some don't use English letters at all!!! A decade ago, I was miffed that GitHub only…
@blog@shkspr.mobi
Internationalise The Fediverse
https://shkspr.mobi/blog/2024/02/internationalise-the-fediverse/We live in the future now. It is OK to use Unicode everywhere.
It seems bizarre to me that modern Internet services sometimes "forget" that there's a world outside the Anglosphere. Some people have the temerity to speak foreign languages! And some of those languages have accents on their letters!! Even worse, some don't use English letters at all!!!
A decade ago, I was miffed that GitHub only supported some ASCII characters in its project names. There's no technical reason why your repo can't be called "ഹലോ വേൾഡ്".
Similarly, I'm frustrated that Mastodon (the largest ActivityPub service) doesn't allow Unicode usernames and has resisted efforts to change.
So I built a small ActivityPub server which publishes content from an Actor called @你好@i18n.viii.fi - it is only a demo account, but it works!
Some ActivityPub clients report that they are able to follow it and receive messages from it. Others - like Mastodon - simply can't see anything from it. Take a look at the replies on Mastodon to see which services work. You can also see some of its posts on the Fediverse.
What Does The Fox Spec Say?
The ActivityPub specification says:
Building an international base of users is important in a federated network. Internationalization
I can't find anything in the specifications which limits what languages a username can be written in. But there are a few clues scattered about.
The user's @ name is defined by preferredUsername which is:
A short username which may be used to refer to the actor, with no uniqueness guarantees. 4.1 Actor objects
There's nothing in there about what scripts it can contain. However, later on, the spec says:
Properties containing natural language values, such as
name,preferredUsername, orsummary, make use of natural language support defined in ActivityStreams. 4. Actors
So it is expected that a preferred username could be written in multiple scripts. Which implies that the default need not be limited to A-Z0-9.
The ActivityStreams specification talks about language mapping.
Finally, the ActivityPub specification has some examples on non-Latin text in names.
So, I think that it is acceptable for usernames to be written in a variety of non-Latin scripts.
But What About...?
There are usually a few objections to "Unicode Everywhere" zealots like me. I'd like to forestall any arguments.
What about homograph attacks?
Well, what about them? ASCII has plenty of similar looking characters. I doubt most people would notice when a capital i is replaced by a lower L - and vice-versa. Similarly the kerning issue of an r and n looking like an m is well known. Are mixed language homographs more dangerous? I don't think so.
What if people make names that can't be typed?
Well, what if they do? Maybe not being found by people who can't type your language is a feature, not a bug. But, anyway, clients can let users search for other people, or copy and paste their names.
What about weird "Zalgo" text?
It is up to a client to decide how they want to render text input. The "problems" of strange Unicode combinations are well known. This is not a hard computer-science problem.
What about bi-directional text?
The spec makes clear this is allowed.
Do people even want a username in their own script?
I have no evidence for this. But I bet you'd get pretty frustrated if you had to switch keyboard just to type your own name, wouldn't you? In any case, why can't I have a username of @😉
What's Next?
If you build ActivityPub software, give some thought to the billions of people who don't have names which easily fit into ASCII.
If your software can see @你好@i18n.viii.fi and its posts, please let me know.
@mikaeru@mastodon.social
Unicopedia Plus is a developer-oriented set of Unicode, Unihan, Unikemet & emoji utilities wrapped into one single app, built with #Electron.
Repository: 🔗 https://codeberg.org/tonton-pixel/unicopedia-plus
#characters #chinese #cjk #codepoints #desktopapplication #electronjs #emoji #ivd #japanese #javascript #kangxi #kangxiradicals #korean #normalization #opensource #regex #segmentation #strokecount #unicode #unicopedia #unihan #unikemet
ALT text
Unicopedia Plus Social Preview
@mikaeru@mastodon.social
Unicopedia Sinica is a developer-oriented set of #Unicode utilities related to ideographs, wrapped into one single app, built with #Electron.
Repository: 🔗 https://codeberg.org/tonton-pixel/unicopedia-sinica
#characters #chinese #cjk #cjkrelated #cjkv #codecharts #codepoints #components #confusables #desktopapplication #electronjs #glyphs #ideographs #ideographicdescriptionsequences #ids #japanese #javascript #kangxi #kangxiradicals #korean #localfonts #opensource #strokes #tangut #unicode #unicopedia #unihan #vietnamese
ALT text
Unicopedia Sinica Social Preview
@Edent@mastodon.social
In *theory* you should be able to follow this test user:
@你好@i18n.viii.fi
But I can't find any Fediverse software which actually supports non-ASCII usernames.
If you are able to see the user, its description, and its avatar - please send me a screenshot 🙂
@tirifto@jam.xwx.moe
So apparently server administrators on the #Fediverse won’t be able to name custom emoji in their native languages and expect them to work in Mastodon, because according to @Gargron non-ASCII signs are hard to input and diacritics shouldn’t change the meaning of words:
https://github.com/mastodon/mastodon/pull/28572#issuecomment-1878952504
No, in my view emoji identifiers shouldn’t be ‘straightforward to input for everyone’. Custom emoji are local to a server; they should be straightforward to input for the users of that server. People from other servers don’t ever have to type their names (unless their administrators choose to add them to their own server), so their ability to type them is completely irrelevant.
Why should a server made specifically for people speaking Russian or Japanese have to use ASCII for their emoji identifiers? Their users have no trouble typing Cyrillic or Kanji signs; it’s what they already do when they make a post; it’s how they normally talk. Why force them to use a different language/alphabet when typing emoji identifiers?
Moreover, linking the username issue makes no sense whatsoever. Usernames are typed across servers and it makes sense to impose stricter technical limitations so more people can read, write and recognise them. This is not the case for emoji; you rarely ever need to type other servers’ emoji identifiers. Normally you don’t even get to see them; you only get to see the picture they represent! Assuming server admins do their job responsibly, there is zero added confusion for anyone involved.
I understand that Unicode is complex, language support is challenging and compromises might be necessary at times. But can we please accept the existence of different languages and writing systems as a reality that we should try to accommodate for, rather than change or circumvent? Yes, a and á are different signs. Yes, they might radically change the meaning of a word. That’s not a proposition for us to accept or reject; that’s the reality of our multilingual world, and should be the basis of our discussion.
#lang_en #accessibility #a11y #custom_emoji #development #emoji #emojos #free_software #internationalisation #internationalization #i18n #languages #localisation #localization #l10n #Mastodon #multilingual #programming #software #Unicode
jam.xwx.moe
Mansardo Jamada
@idontlikenames@mastodon.gamedev.place
New 2d numeral system just dropped‽‽‽
It's based on ᚛ᚑᚌᚐᚋ᚜ & ☯ & bijective base 6, & works left→right or left←right
#math #unicode #linguistics #pixelart #ui #blackandwhite #design #inspiration #language
@amake@mastodon.social
@gimsieke@mastodon.cloud
Formatting people’s names correctly in a given context, for a given purpose, is hard. International linguists recently helped update the #Unicode Common Locale Data Repository (#CLDR). It will help programmers display person names correctly in many settings.
Mike McKenna wrote about it in “A Story Teller’s Case Study: Unlocking the Power of CLDR Person Name Formatting – A Solution for Formatting Names in a Globalized World” https://www.unicode.org/media/CLDR_Person_Name_White_Paper_June%202023.pdf
@eemeli@mefi.social
#introduction 1/2
Hello! My current Big Project is fixing #localization, making it easier for software and sites to communicate in various human languages. So I'm spending quite a bit of time in #unicode and #tc39 trying to shepherd along spec proposals so that we can fix this for everyone. Nowadays I even get paid for this, on account of being a staff software engineer on the l10n team at #mozilla.