@mikaeru@mastodon.social
Hashtag
#CJK
116 posts tagged with this hashtag.

@mikaeru@mastodon.social · Reply to Michel Mariani

@mikaeru@mastodon.social
The latest version v18.1.0 of the open-source application "Unicopedia Sinica" is now available, embedding all data files required to display CJK ideographs as SVG glyphs in the "CJK Sources" and "CJK Variations" utilities...
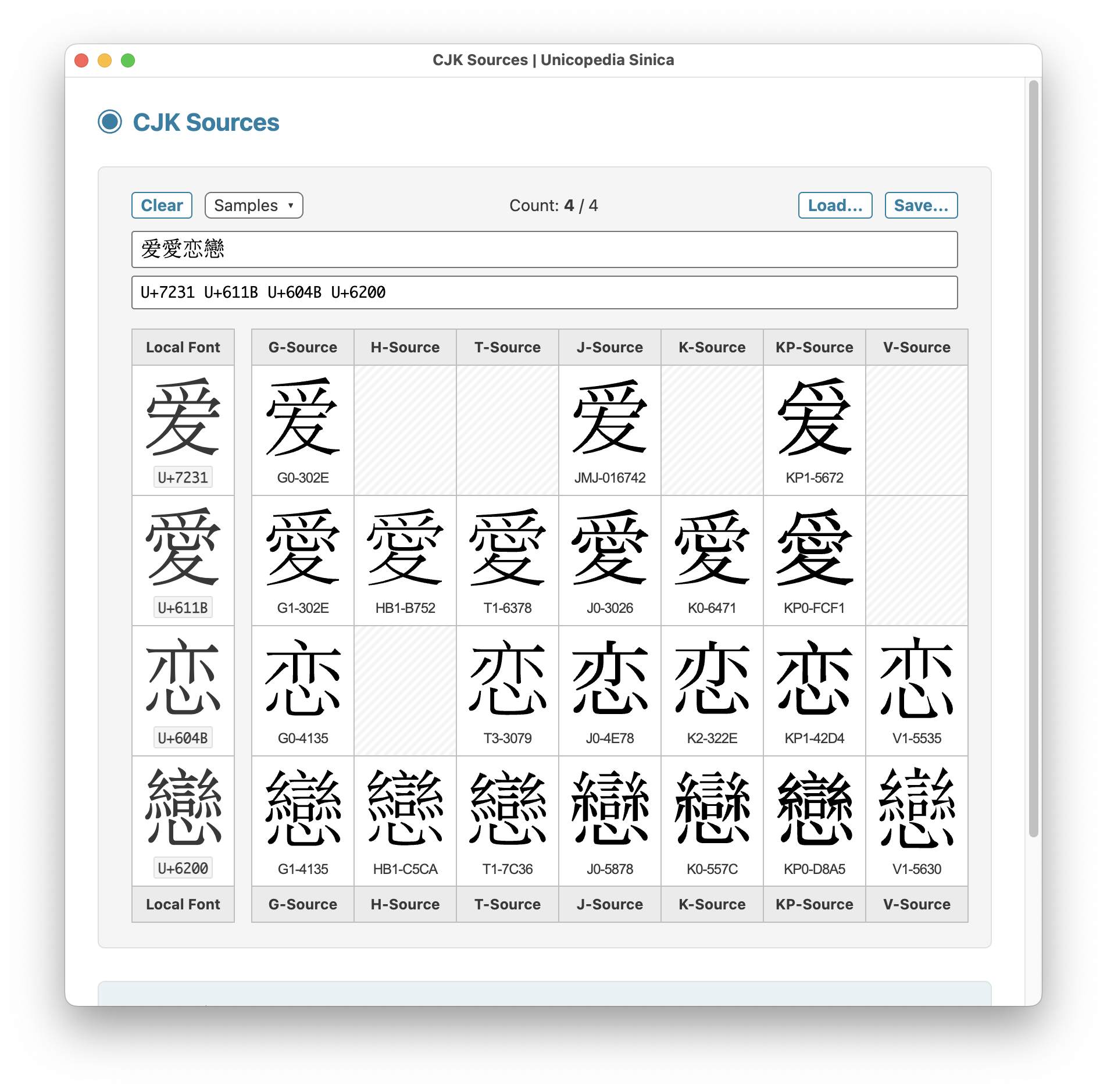
ALT text
Unicopedia Sinica - CJK Sources utility screenshot Four simplified and traditional "Love" characters
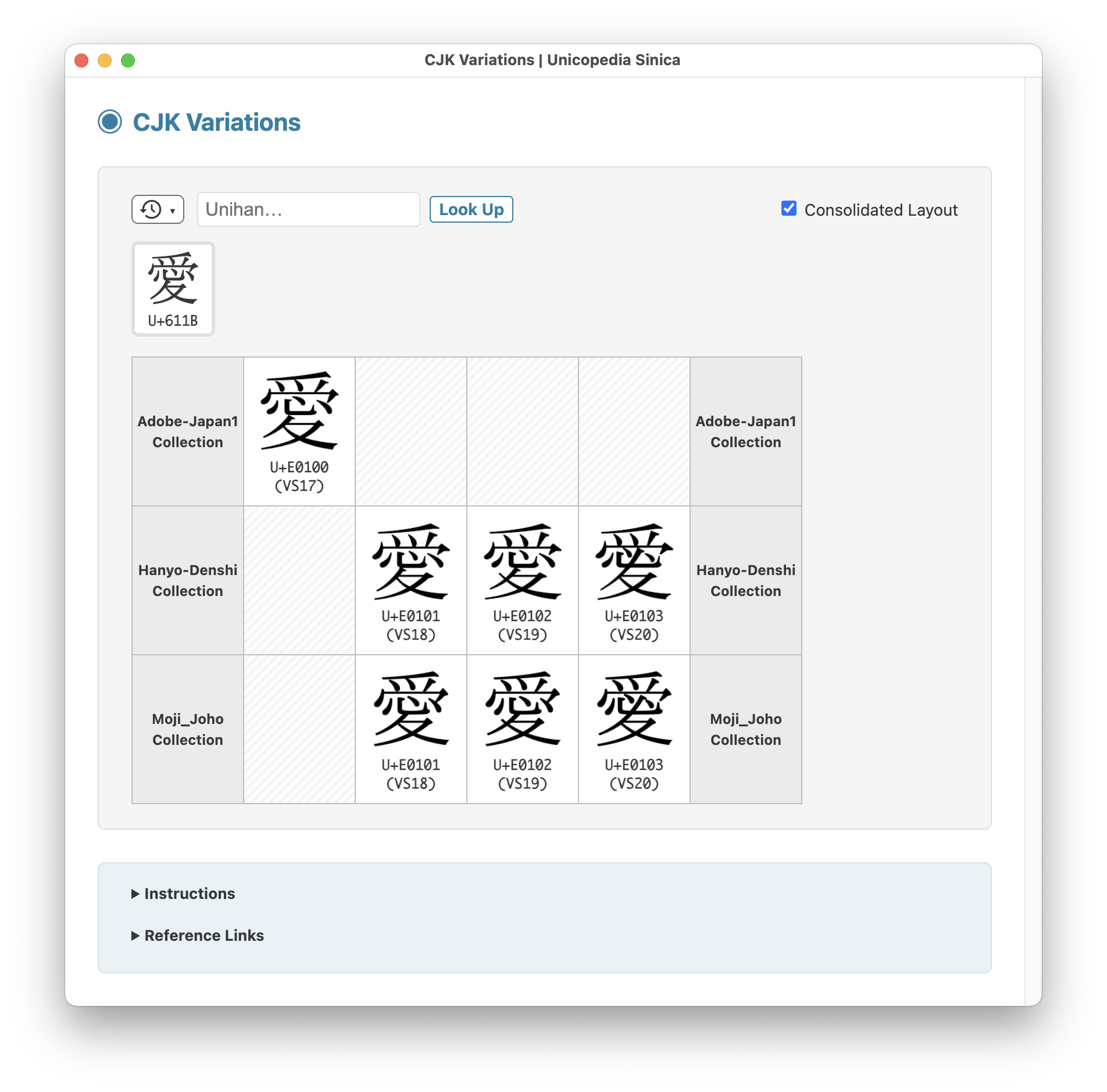
ALT text
Unicopedia Sinica - CJK Variations utility screenshot Japanese glyph variations on "Love" character
@mikaeru@mastodon.social
The latest version v18.1.0 of the open-source application "Unicopedia Sinica" is now available, embedding all data files required to display CJK ideographs as SVG glyphs in the "CJK Sources" and "CJK Variations" utilities...
ALT text
Unicopedia Sinica - CJK Sources utility screenshot Four simplified and traditional "Love" characters
ALT text
Unicopedia Sinica - CJK Variations utility screenshot Japanese glyph variations on "Love" character
@mikaeru@mastodon.social
Thanks to @jlhwung, the so beautifully crafted 'BabelStone Han' font by Andrew West (魏安), is alive and well!
The latest version 17.0.0, made of 'BabelStoneHanBasic.ttf' and 'BabelStoneHanExtra.ttf', is available from:
🔗 https://github.com/babelstone/babelstonehan-ufo/releases/latest
Release 20250710 · babelstone/babelstonehan-ufo
20250710 - 2026-03-09 Summary Changes from 20250708-beta to 20250710 across all BabelStone Han UFO files. Family Totals: 6 added, 2 modified, 0 removed (8 total changes) BabelStone Han Basic Glyph ...
@mikaeru@mastodon.social
- Technically speaking, Khitan Small Script and Yi script are not included (yet) in the data for non-Han ideographic scripts.
- The Jurchen and Seal scripts are poised to be officially added to Unicode 18.0 in September 2026...
- BabelStone (Andrew West) reference links:
🔗 https://www.babelstone.co.uk/Jurchen/
🔗 https://www.babelstone.co.uk/Khitan/
🔗 https://www.babelstone.co.uk/Yi/
#Unicode #Ideographic #Unihan #CJK #CJKV #Jurchen #Khitan #Nüshu #Seal #Tangut #Yi
babelstone.co.uk
Babel Stone : Yi
@mikaeru@mastodon.social
About two-thirds of the #Unicode 17.0 standard characters originate from China, most of them of ideographic nature, and are therefore largely over-represented...
Ideographic: 110,943
Han: 103,351
Non-Han (Khitan Small Script + Nüshu + Tangut + Yi): 9,148
Han + Non-Han: 112,499
Standard: 159,799
Ideographic / Standard: 69.43 %
(Han + Non-Han) / Standard: 70.40 %
UAX #38: Unicode Han Database (Unihan)
https://www.unicode.org/reports/tr38/
UAX #60: Data for non Han Ideographic Scripts
https://www.unicode.org/reports/tr60/

unicode.org
UAX #60: Data for non Han Ideographic Scripts
@mikaeru@mastodon.social
- Technically speaking, Khitan Small Script and Yi script are not included (yet) in the data for non-Han ideographic scripts.
- The Jurchen and Seal scripts are poised to be officially added to Unicode 18.0 in September 2026...
- BabelStone (Andrew West) reference links:
🔗 https://www.babelstone.co.uk/Jurchen/
🔗 https://www.babelstone.co.uk/Khitan/
🔗 https://www.babelstone.co.uk/Yi/
#Unicode #Ideographic #Unihan #CJK #CJKV #Jurchen #Khitan #Nüshu #Seal #Tangut #Yi
babelstone.co.uk
Babel Stone : Yi
@mikaeru@mastodon.social
About two-thirds of the #Unicode 17.0 standard characters originate from China, most of them of ideographic nature, and are therefore largely over-represented...
Ideographic: 110,943
Han: 103,351
Non-Han (Khitan Small Script + Nüshu + Tangut + Yi): 9,148
Han + Non-Han: 112,499
Standard: 159,799
Ideographic / Standard: 69.43 %
(Han + Non-Han) / Standard: 70.40 %
UAX #38: Unicode Han Database (Unihan)
https://www.unicode.org/reports/tr38/
UAX #60: Data for non Han Ideographic Scripts
https://www.unicode.org/reports/tr60/
unicode.org
UAX #60: Data for non Han Ideographic Scripts
@mikaeru@mastodon.social
Thanks to @jlhwung, the so beautifully crafted 'BabelStone Han' font by Andrew West (魏安), is alive and well!
The latest version 17.0.0, made of 'BabelStoneHanBasic.ttf' and 'BabelStoneHanExtra.ttf', is available from:
🔗 https://github.com/babelstone/babelstonehan-ufo/releases/latest
Release 20250710 · babelstone/babelstonehan-ufo
20250710 - 2026-03-09 Summary Changes from 20250708-beta to 20250710 across all BabelStone Han UFO files. Family Totals: 6 added, 2 modified, 0 removed (8 total changes) BabelStone Han Basic Glyph ...
@mikaeru@mastodon.social · Reply to Michel Mariani
The icon of the new #Unicopedia #Sigilla application shows the provisional #Seal character U+3FBB5 whose equivalent #CJK #ideograph is U+5B57 字, meaning "letter, character, word".

ALT text
Icon of the Unicopedia Sigilla application, with the provisional Seal character U+3FBB5 whose equivalent CJK ideograph is U+5B57 字
@mikaeru@mastodon.social
All documents published by the Ideographic Research Group (IRG) are now available on the Unicode web site, and can be easily and efficiently found through the new search bar provided on the IRG homepage.
🔗 https://www.unicode.org/irg/
This long-awaited search feature is very convenient, and so useful to find what you're interested in, and even more (ah, the wonderful power of serendipity!)...
#Unicode #IRG #IdeographicResearchGroup #CJK #Ideographs #Unihan

ALT text
Screenshot of the IRG home page, looking for "taboo" from the search bar

ALT text
Screenshot of list of search results in the IRG documents
@mikaeru@mastodon.social
All documents published by the Ideographic Research Group (IRG) are now available on the Unicode web site, and can be easily and efficiently found through the new search bar provided on the IRG homepage.
🔗 https://www.unicode.org/irg/
This long-awaited search feature is very convenient, and so useful to find what you're interested in, and even more (ah, the wonderful power of serendipity!)...
#Unicode #IRG #IdeographicResearchGroup #CJK #Ideographs #Unihan
ALT text
Screenshot of the IRG home page, looking for "taboo" from the search bar
ALT text
Screenshot of list of search results in the IRG documents
@mikaeru@mastodon.social
All documents published by the Ideographic Research Group (IRG) are now available on the Unicode web site, and can be easily and efficiently found through the new search bar provided on the IRG homepage.
🔗 https://www.unicode.org/irg/
This long-awaited search feature is very convenient, and so useful to find what you're interested in, and even more (ah, the wonderful power of serendipity!)...
#Unicode #IRG #IdeographicResearchGroup #CJK #Ideographs #Unihan
ALT text
Screenshot of the IRG home page, looking for "taboo" from the search bar
ALT text
Screenshot of list of search results in the IRG documents

@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8

hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
![* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]](https://media.hackers.pub/note-media/1e9c2aae-dd7d-4963-b3c8-34336b34dfac.webp)
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@mikaeru@mastodon.social
The latest version of the open-source application "Unicopedia Sinica" is now available, adding support for all the new CJK/Unihan characters defined in Unicode 17.0.
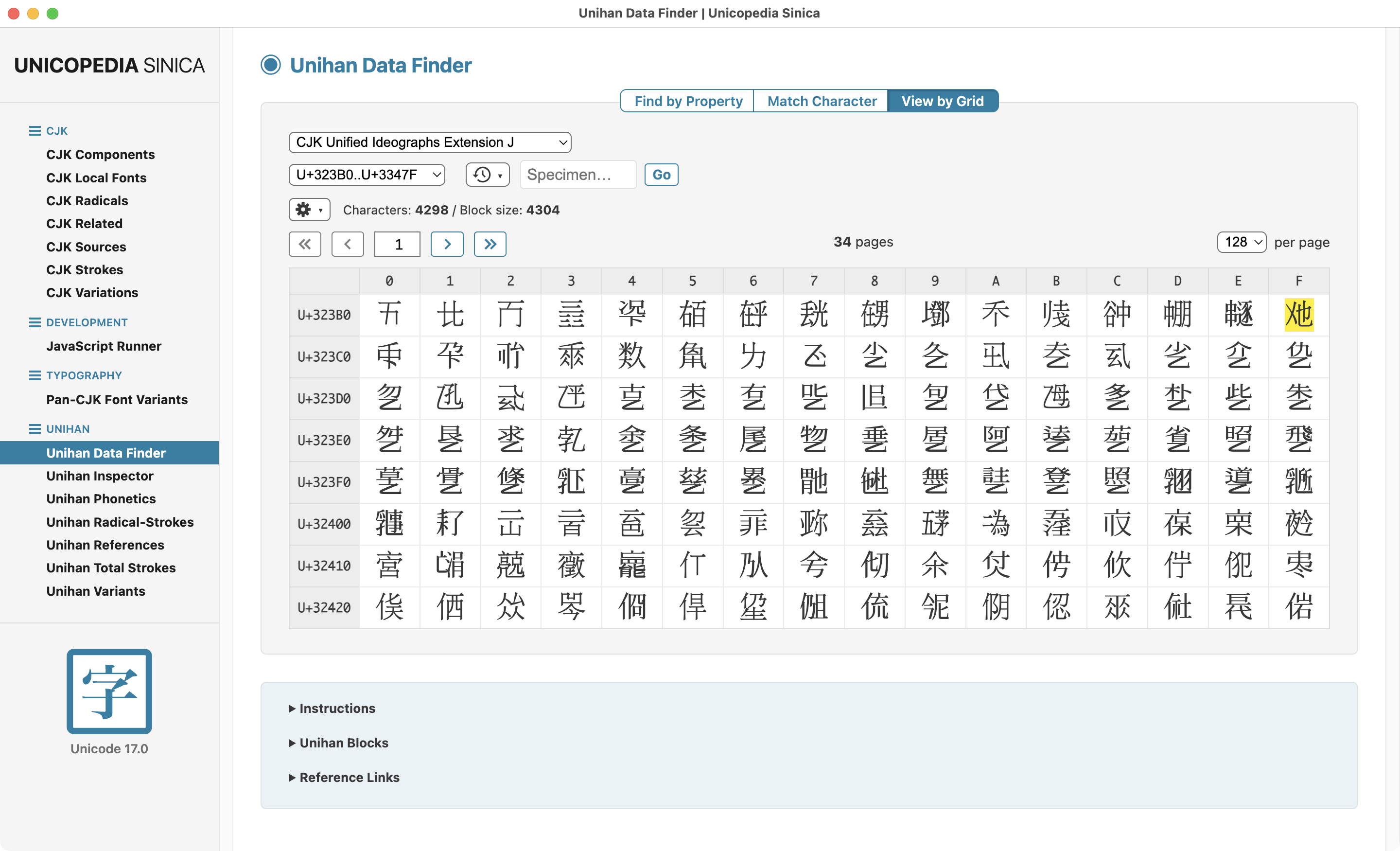
ALT text
Screenshot of the open-source application Unicopedia Sinica v.17.0.0
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@hongminhee@hollo.social
Why #Markdown's emphasis syntax (**) fails outside of Western languages: A deep dive into #CommonMark's “delimiter run” flaws and their impact on #CJK users.
A must-read for anyone interested in #internationalization and the future of Markdown:
https://hackers.pub/@yurume/019b912a-cc3b-7e45-9227-d08f0d1eafe8
hackers.pub
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day. The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction. However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis. As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**? In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
@yurume@hackers.pub · Reply to 유루메 Yurume
As Markdown has become the standard for LLM outputs, we are now forced to witness a common and unsightly mess where Markdown emphasis markers (**) remain unrendered and exposed, as seen in the image. This is a chronic issue with the CommonMark specification---one that I once reported about ten years ago---but it has been left neglected without any solution to this day.
The technical details of the problem are as follows: In an effort to limit parsing complexity during the standardization process, CommonMark introduced the concept of "delimiter runs." These runs are assigned properties of being "left-flanking" or "right-flanking" (or both, or neither) depending on their position. According to these rules, a bolded segment must start with a left-flanking delimiter run and end with a right-flanking one. The crucial point is that whether a run is left- or right-flanking is determined solely by the immediate surrounding characters, without any consideration of the broader context. For instance, a left-flanking delimiter must be in the form of **<ordinary character>, <whitespace>**<punctuation>, or <punctuation>**<punctuation>. (Here, "ordinary character" refers to any character that is not whitespace or punctuation.) The first case is presumably intended to allow markers embedded within a word, like **마크다운**은, while the latter cases are meant to provide limited support for markers placed before punctuation, such as in 이 **"마크다운"** 형식은. The rules for right-flanking are identical, just in the opposite direction.
However, when you try to parse a string like **마크다운(Markdown)**은 using these rules, it fails because the closing ** is preceded by punctuation (a parenthesis) and it must be followed by whitespace or another punctuation mark to be considered right-flanking. Since it is followed by an ordinary letter (은), it is not recognized as right-flanking and thus fails to close the emphasis.
As explained in the CommonMark spec, the original intent of this rule was to support nested emphasis, like **this **way** of nesting**. Since users typically don't insert spaces inside emphasis markers (e.g., **word **), the spec attempts to resolve ambiguity by declaring that markers adjacent to whitespace can only function in a specific direction. However, in CJK (Chinese, Japanese, Korean) environments, either spaces are completly absent or (as in Korean) punctuations are commonly used within a word. Consequently, there are clear limits to inferring whether a delimiter is left or right-flanking based on these rules. Even if we were to allow <ordinary character>**<punctuation> to be interpreted as left-flanking to accommodate cases like **마크다운(Markdown)**은, how would we handle something like このような**[状況](...)は**?
In my view, the utility of nested emphasis is marginal at best, while the frustration it causes in CJK environments is significant. Furthermore, because LLMs generate Markdown based on how people would actually use it---rather than strictly following the design intent of CommonMark---this latent inconvenience that users have long felt is now being brought directly to the surface.
ALT text
* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [The emphasized portion `비숍(Ba5)` is surrounded by unrendered Markdown emphasis marks `**`.]
@mikaeru@mastodon.social
Generally, new CJK Ideographs proposed by members of the IRG (Ideographic Research Group) go through several rounds of exchanges/discussions until they get approved or possibly postponed or rejected.
For instance, here is the page dedicated to UK-20538 ⿰㐅也 (with images as "pieces of evidence"), which eventually made its way to Unicode 17.0, encoded as U+323BF :
hc.jsecs.org
00029 | ⿰㐅也 | WS2021v7.0
@mikaeru@mastodon.social
Unicode 17.0 introduces five new CJK Unified Ideographs related to Chinese personal pronouns, four of them having been proposed by Andrew West (BabelStone):
« The other Chinese pronoun coming to Unicode v. 17.0 next year, in addition to ⿰㐅也 (3p gender-neutral, ⿰男也 (3p explicitly male), ⿱妳心 ( f. equivalent of 您), ⿱我心 (Taiwanese 1p plural), is ⿱她心 (f. equivalent to 怹) »
🔗 https://bsky.app/profile/babelstone.co.uk/post/3lbrxowqt7k24
ALT text
Screenshot of CJK Related data from Unicopedia Sinica: Chinese Personal Pronouns
@mikaeru@mastodon.social
The Ideographic Research Group (IRG) is responsible for preparing and reviewing sets of CJK unified ideographs to be included in the Unicode Standard.
It has recently made available a useful list of so-called disunified CJK ideographs, coming with images of glyphs and IRG source references, which also provides links to documents giving the rationale behind each disunification:
unicode.org
IRG Disunified Ideographs
@mikaeru@mastodon.social
> This increases the number of encoded CJK ideographs to over 100,000!
十万字【じゅうまんじ】!
mastodon.social
Michel Mariani (@mikaeru@mastodon.social)
New additions include 4,298 additional CJK unified ideographs in a new block, CJK Unified Ideographs Extension J, as well as 18 other CJK ideographs added to the existing Extension C and Extension E blocks. This increases the number of encoded CJK ideographs to over 100,000! Also, nearly 2,500 already-encoded CJK ideographs are horizontally extended by the addition of source references and glyphs reflecting use of those ideographs in China and Korea. 🔗 https://blog.unicode.org/2025/09/unicode-170-release-announcement.html #Unicode #CJK
@mikaeru@mastodon.social
RE: https://mastodon.social/@mikaeru/115567152437555585
New additions include 4,298 additional CJK unified ideographs in a new block, CJK Unified Ideographs Extension J, as well as 18 other CJK ideographs added to the existing Extension C and Extension E blocks.
This increases the number of encoded CJK ideographs to over 100,000!
Also, nearly 2,500 already-encoded CJK ideographs are horizontally extended by the addition of source references and glyphs reflecting use of those ideographs in China and Korea.
🔗 https://blog.unicode.org/2025/09/unicode-170-release-announcement.html

blog.unicode.org
Unicode 17.0 Release Announcement
Announcing The Unicode® Standard, Version 17.0 The Unicode Standard is the foundation for all global digital communications, providing the e...
@mikaeru@mastodon.social
New additions include 4,298 additional CJK unified ideographs in a new block, CJK Unified Ideographs Extension J, as well as 18 other CJK ideographs added to the existing Extension C and Extension E blocks.
This increases the number of encoded CJK ideographs to over 100,000!
Also, nearly 2,500 already-encoded CJK ideographs are horizontally extended by the addition of source references and glyphs reflecting use of those ideographs in China and Korea.
🔗 https://blog.unicode.org/2025/09/unicode-170-release-announcement.html
blog.unicode.org
Unicode 17.0 Release Announcement
Announcing The Unicode® Standard, Version 17.0 The Unicode Standard is the foundation for all global digital communications, providing the e...
@mikaeru@mastodon.social
The latest version of the open-source application "Unicopedia Sinica" is now available, adding support for all the new CJK/Unihan characters defined in Unicode 17.0.
ALT text
Screenshot of the open-source application Unicopedia Sinica v.17.0.0
@mikaeru@mastodon.social
The latest version of the open-source application "Unicopedia Sinica" is now available, adding support for all the new CJK/Unihan characters defined in Unicode 17.0.
ALT text
Screenshot of the open-source application Unicopedia Sinica v.17.0.0
@mikaeru@mastodon.social
The latest version of the open-source application "Unicopedia Sinica" is now available, adding support for all the new CJK/Unihan characters defined in Unicode 17.0.
ALT text
Screenshot of the open-source application Unicopedia Sinica v.17.0.0
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social · Reply to 洪 民憙 (Hong Minhee) :nonbinary:
安寧하세요, 저는 서울에 살고 있는 30代 後半 오픈 소스 소프트웨어 엔지니어이며, 自由·오픈 소스 소프트웨어와 聯合宇宙(fediverse)의 熱烈한 支持者입니다.
저는 TypeScript用 ActivityPub 서버 프레임워크인 @fedify 프로젝트와 싱글 유저用 ActivityPub 마이크로블로그인 @hollo 프로젝트와 ActivityPub 봇 프레임워크인 @botkit 프로젝트의 製作者이기도 합니다.
저는 東아시아 言語(이른바 #CJK)와 유니코드에도 關心이 많습니다. 聯合宇宙에서는 國漢文混用體를 쓰고 있어요! 제게 韓國語나 英語, 日本語로 말을 걸어주세요. (아니면, 漢文으로도!)
@dcz@fosstodon.org
@mikaeru@mastodon.social
Beautifully crafted BabelStone Han font, by Andrew West 魏安
#BabelStone Han v. 15.1.3 is a free #Unicode #CJK #font with over 57,000 Han characters (#hanzi, #kanji, #hanja), and 62,061 Unicode characters in total. It is a Song/Ming style (宋体/明體) font, with glyphs modelled on the official character forms used in the People's Republic of China, and is primarily intended for writing Modern Standard #Chinese, Classical Chinese, and various Sinitic languages and dialects.

ALT text
Repeated: 龙 U+9F99 U+31342 U+2EE5D
@mikaeru@mastodon.social
New in the CJK Variations utility of Unicopedia Sinica:
- Support for the latest Ideographic Variation Database (IVD 2025), adding the new CAAPH Collection.
- Support for the updated BabelStone Collection (unregistered), based on the latest BabelStone Han font (v17.0.0 BETA), by Andrew C. West (魏安), 1960-2025 RIP (安息吧).
🔗 https://https://codeberg.org/tonton-pixel/unicopedia-sinica
#Unicopedia #Unicode #Unihan #CJK #IdeographicVariationDatabase #IVD #CAAPH #BabelStone
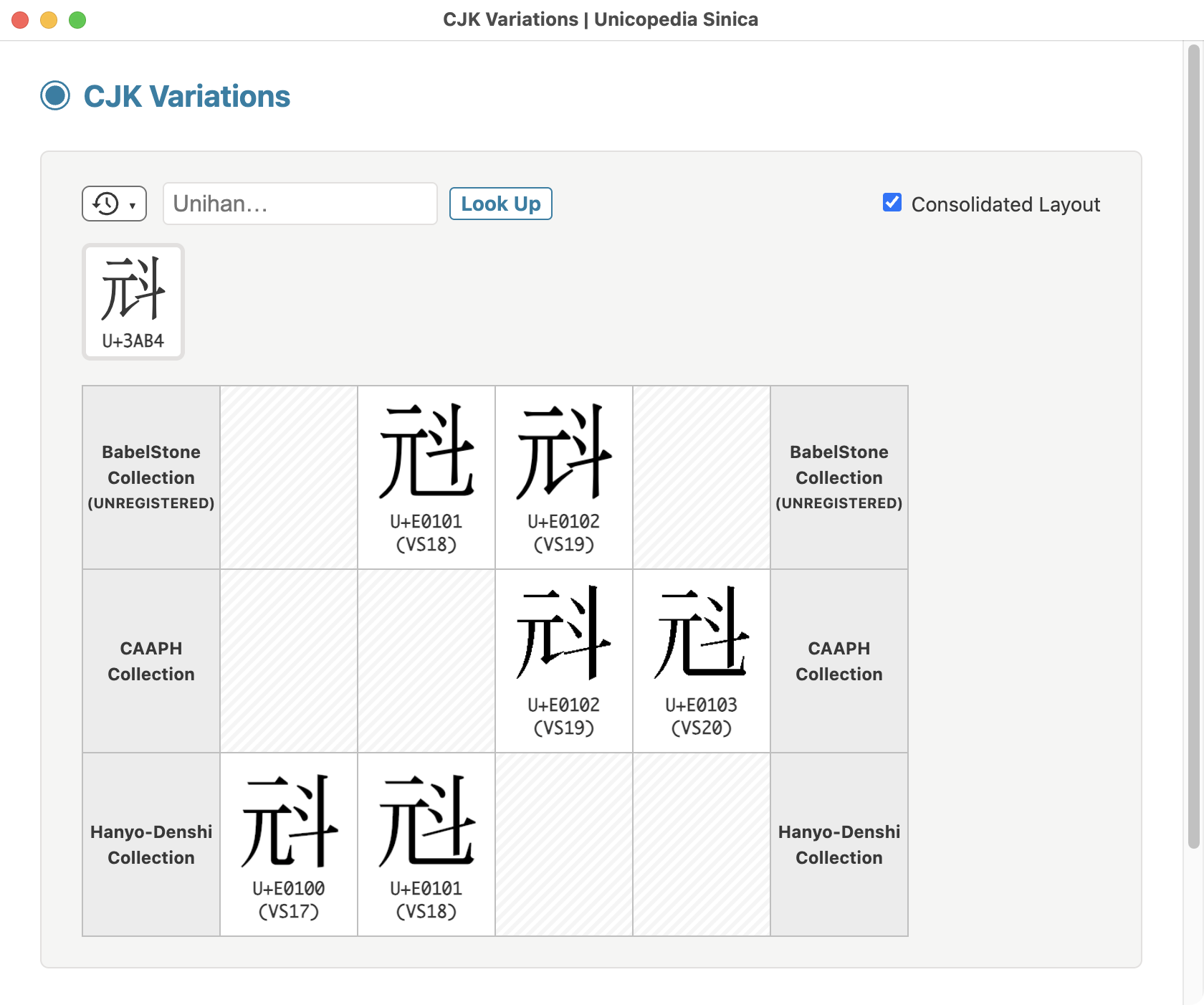
ALT text
Screenshot of the CJK Variations utility of Unicopedia Sinica for Unicode character U+3AB4
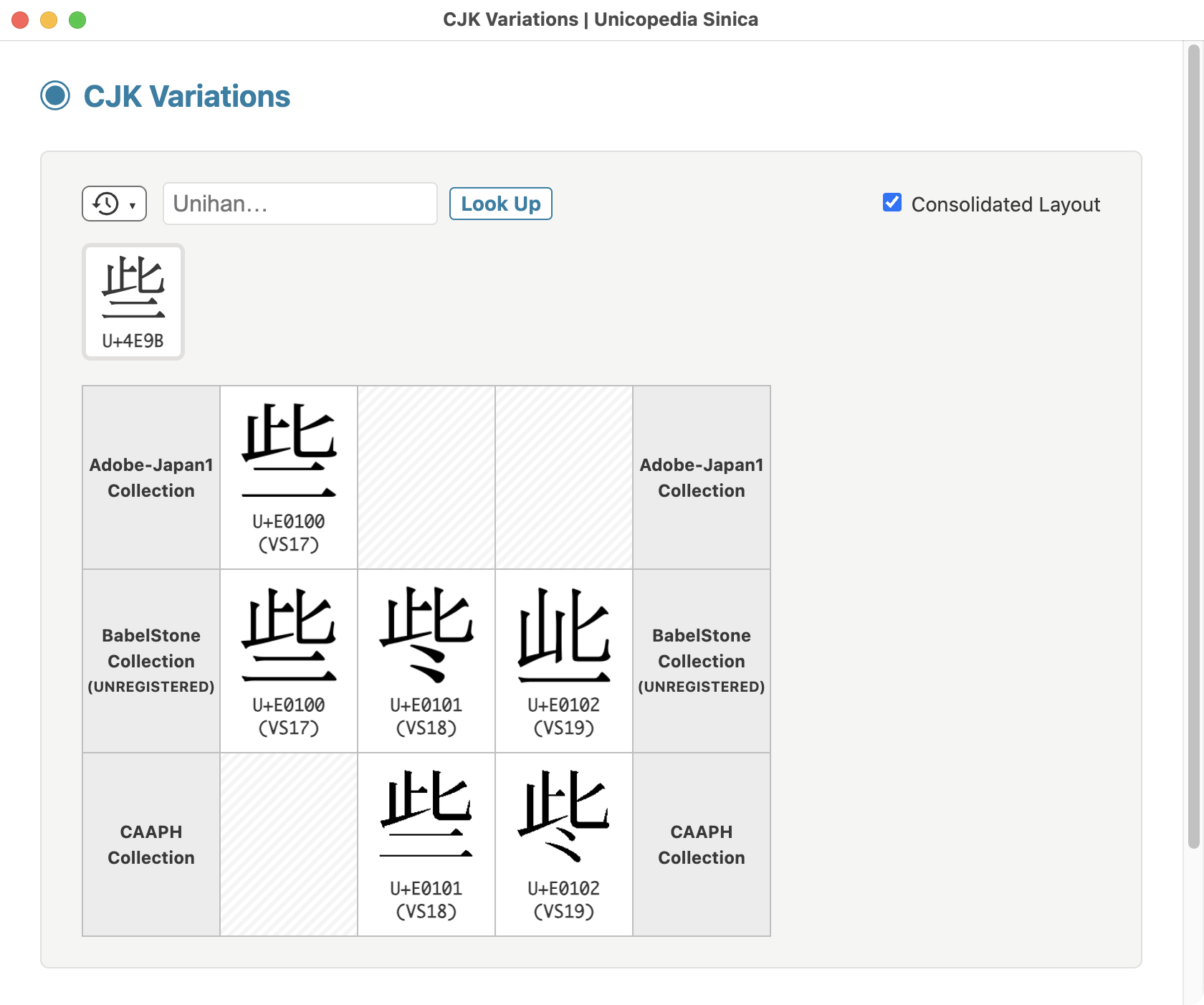
ALT text
Screenshot of the CJK Variations utility of Unicopedia Sinica for Unicode character U+4E9B
@mikaeru@mastodon.social
New in the CJK Variations utility of Unicopedia Sinica:
- Support for the latest Ideographic Variation Database (IVD 2025), adding the new CAAPH Collection.
- Support for the updated BabelStone Collection (unregistered), based on the latest BabelStone Han font (v17.0.0 BETA), by Andrew C. West (魏安), 1960-2025 RIP (安息吧).
🔗 https://https://codeberg.org/tonton-pixel/unicopedia-sinica
#Unicopedia #Unicode #Unihan #CJK #IdeographicVariationDatabase #IVD #CAAPH #BabelStone
ALT text
Screenshot of the CJK Variations utility of Unicopedia Sinica for Unicode character U+3AB4
ALT text
Screenshot of the CJK Variations utility of Unicopedia Sinica for Unicode character U+4E9B
@hongminhee@hollo.social · Reply to 洪 民憙 (Hong Minhee) :nonbinary:
安寧하세요, 저는 서울에 살고 있는 30代 後半 오픈 소스 소프트웨어 엔지니어이며, 自由·오픈 소스 소프트웨어와 聯合宇宙(fediverse)의 熱烈한 支持者입니다.
저는 TypeScript用 ActivityPub 서버 프레임워크인 @fedify 프로젝트와 싱글 유저用 ActivityPub 마이크로블로그인 @hollo 프로젝트와 ActivityPub 봇 프레임워크인 @botkit 프로젝트의 製作者이기도 합니다.
저는 東아시아 言語(이른바 #CJK)와 유니코드에도 關心이 많습니다. 聯合宇宙에서는 國漢文混用體를 쓰고 있어요! 제게 韓國語나 英語, 日本語로 말을 걸어주세요. (아니면, 漢文으로도!)
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@mikaeru@mastodon.social
The Ideographic Research Group (IRG) is responsible for preparing and reviewing sets of CJK unified ideographs to be included in the Unicode Standard.
Current and future IRG source prefixes used to be listed in the main IRG homepage, but are now available in a separate dedicated page:
unicode.org
Current & Future IRG Source Prefixes
@mikaeru@mastodon.social
Unicopedia Plus is a developer-oriented set of Unicode, Unihan, Unikemet & emoji utilities wrapped into one single app, built with #Electron.
Repository: 🔗 https://codeberg.org/tonton-pixel/unicopedia-plus
#characters #chinese #cjk #codepoints #desktopapplication #electronjs #emoji #ivd #japanese #javascript #kangxi #kangxiradicals #korean #normalization #opensource #regex #segmentation #strokecount #unicode #unicopedia #unihan #unikemet

ALT text
Unicopedia Plus Social Preview
@mikaeru@mastodon.social
Unicopedia Sinica is a developer-oriented set of #Unicode utilities related to ideographs, wrapped into one single app, built with #Electron.
Repository: 🔗 https://codeberg.org/tonton-pixel/unicopedia-sinica
#characters #chinese #cjk #cjkrelated #cjkv #codecharts #codepoints #components #confusables #desktopapplication #electronjs #glyphs #ideographs #ideographicdescriptionsequences #ids #japanese #javascript #kangxi #kangxiradicals #korean #localfonts #opensource #strokes #tangut #unicode #unicopedia #unihan #vietnamese

ALT text
Unicopedia Sinica Social Preview
@yoxem@sns.kianting.info
@yoxem@sns.kianting.info
@hongminhee@hollo.social · Reply to 洪 民憙 (Hong Minhee) :nonbinary:
安寧하세요, 저는 서울에 살고 있는 30代 後半 오픈 소스 소프트웨어 엔지니어이며, 自由·오픈 소스 소프트웨어와 聯合宇宙(fediverse)의 熱烈한 支持者입니다.
저는 TypeScript用 ActivityPub 서버 프레임워크인 @fedify 프로젝트와 싱글 유저用 ActivityPub 마이크로블로그인 @hollo 프로젝트와 ActivityPub 봇 프레임워크인 @botkit 프로젝트의 製作者이기도 합니다.
저는 東아시아 言語(이른바 #CJK)와 유니코드에도 關心이 많습니다. 聯合宇宙에서는 國漢文混用體를 쓰고 있어요! 제게 韓國語나 英語, 日本語로 말을 걸어주세요. (아니면, 漢文으로도!)
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social · Reply to 洪 民憙 (Hong Minhee) :nonbinary:
安寧하세요, 저는 서울에 살고 있는 30代 後半 오픈 소스 소프트웨어 엔지니어이며, 自由·오픈 소스 소프트웨어와 聯合宇宙(fediverse)의 熱烈한 支持者입니다.
저는 TypeScript用 ActivityPub 서버 프레임워크인 @fedify 프로젝트와 싱글 유저用 ActivityPub 마이크로블로그인 @hollo 프로젝트와 ActivityPub 봇 프레임워크인 @botkit 프로젝트의 製作者이기도 합니다.
저는 東아시아 言語(이른바 #CJK)와 유니코드에도 關心이 많습니다. 聯合宇宙에서는 國漢文混用體를 쓰고 있어요! 제게 韓國語나 英語, 日本語로 말을 걸어주세요. (아니면, 漢文으로도!)
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social · Reply to 洪 民憙 (Hong Minhee) :nonbinary:
安寧하세요, 저는 서울에 살고 있는 30代 後半 오픈 소스 소프트웨어 엔지니어이며, 自由·오픈 소스 소프트웨어와 聯合宇宙(fediverse)의 熱烈한 支持者입니다.
저는 TypeScript用 ActivityPub 서버 프레임워크인 @fedify 프로젝트와 싱글 유저用 ActivityPub 마이크로블로그인 @hollo 프로젝트와 ActivityPub 봇 프레임워크인 @botkit 프로젝트의 製作者이기도 합니다.
저는 東아시아 言語(이른바 #CJK)와 유니코드에도 關心이 많습니다. 聯合宇宙에서는 國漢文混用體를 쓰고 있어요! 제게 韓國語나 英語, 日本語로 말을 걸어주세요. (아니면, 漢文으로도!)
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social · Reply to 洪 民憙 (Hong Minhee) :nonbinary:
安寧하세요, 저는 서울에 살고 있는 30代 後半 오픈 소스 소프트웨어 엔지니어이며, 自由·오픈 소스 소프트웨어와 聯合宇宙(fediverse)의 熱烈한 支持者입니다.
저는 TypeScript用 ActivityPub 서버 프레임워크인 @fedify 프로젝트와 싱글 유저用 ActivityPub 마이크로블로그인 @hollo 프로젝트와 ActivityPub 봇 프레임워크인 @botkit 프로젝트의 製作者이기도 합니다.
저는 東아시아 言語(이른바 #CJK)와 유니코드에도 關心이 많습니다. 聯合宇宙에서는 國漢文混用體를 쓰고 있어요! 제게 韓國語나 英語, 日本語로 말을 걸어주세요. (아니면, 漢文으로도!)
@hongminhee@hollo.social · Reply to 洪 民憙 (Hong Minhee) :nonbinary:
安寧하세요, 저는 서울에 살고 있는 30代 後半 오픈 소스 소프트웨어 엔지니어이며, 自由·오픈 소스 소프트웨어와 聯合宇宙(fediverse)의 熱烈한 支持者입니다.
저는 TypeScript用 ActivityPub 서버 프레임워크인 @fedify 프로젝트와 싱글 유저用 ActivityPub 마이크로블로그인 @hollo 프로젝트와 ActivityPub 봇 프레임워크인 @botkit 프로젝트의 製作者이기도 합니다.
저는 東아시아 言語(이른바 #CJK)와 유니코드에도 關心이 많습니다. 聯合宇宙에서는 國漢文混用體를 쓰고 있어요! 제게 韓國語나 英語, 日本語로 말을 걸어주세요. (아니면, 漢文으로도!)
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@mikaeru@mastodon.social
The Ideographic Research Group (IRG) is responsible for preparing and reviewing sets of CJK unified ideographs to be included in the Unicode Standard.
The IRG homepage is now including comprehensive lists of current and future IRG source prefixes...
unicode.org
Ideographic Research Group
@hongminhee@hollo.social · Reply to 洪 民憙 (Hong Minhee) :nonbinary:
安寧하세요, 저는 서울에 살고 있는 30代 後半 오픈 소스 소프트웨어 엔지니어이며, 自由·오픈 소스 소프트웨어와 聯合宇宙(fediverse)의 熱烈한 支持者입니다.
저는 TypeScript用 ActivityPub 서버 프레임워크인 @fedify 프로젝트와 싱글 유저用 ActivityPub 마이크로블로그인 @hollo 프로젝트와 ActivityPub 봇 프레임워크인 @botkit 프로젝트의 製作者이기도 합니다.
저는 東아시아 言語(이른바 #CJK)와 유니코드에도 關心이 많습니다. 聯合宇宙에서는 國漢文混用體를 쓰고 있어요! 제게 韓國語나 英語, 日本語로 말을 걸어주세요. (아니면, 漢文으로도!)
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@hongminhee@hollo.social · Reply to 洪 民憙 (Hong Minhee) :nonbinary:
安寧하세요, 저는 서울에 살고 있는 30代 後半 오픈 소스 소프트웨어 엔지니어이며, 自由·오픈 소스 소프트웨어와 聯合宇宙(fediverse)의 熱烈한 支持者입니다.
저는 TypeScript用 ActivityPub 서버 프레임워크인 @fedify 프로젝트와 싱글 유저用 ActivityPub 마이크로블로그인 @hollo 프로젝트와 ActivityPub 봇 프레임워크인 @botkit 프로젝트의 製作者이기도 합니다.
저는 東아시아 言語(이른바 #CJK)와 유니코드에도 關心이 많습니다. 聯合宇宙에서는 國漢文混用體를 쓰고 있어요! 제게 韓國語나 英語, 日本語로 말을 걸어주세요. (아니면, 漢文으로도!)
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@FoW@netsphere.one
아시아 언어를 위한 메시징 서비스 음절 검색
CJK는 조사;postposition을 단어 뒤에 바로 붙여쓰므로, 음절 검색 허용 여부에 따라 생산성이 달라진다.
1. 나쁨: 음절 검색 불가. 어절 검색만 허용 (예: 백두산이).
- Discord
- Matrix
- Synology Chat
- Telegram
2. 보통: 세 음절부터 검색 허용 (예: 백두산, 두산이).
- Google Meet
- WhatsApp
3. 좋음: 두 음절부터 검색 허용 (예: 백두, 두산, 산이).
- Microsoft Teams
- Webex
4. 지나쳐서 당황스러움: 한 음절부터 검색 허용 (예: 백, 두, 산, 이)
- Slack
@FoW@netsphere.one
아시아 언어를 위한 메시징 서비스 음절 검색
CJK는 조사;postposition을 단어 뒤에 바로 붙여쓰므로, 음절 검색 허용 여부에 따라 생산성이 달라진다.
1. 나쁨: 음절 검색 불가. 어절 검색만 허용 (예: 백두산이).
- Discord
- Matrix
- Synology Chat
- Telegram
2. 보통: 세 음절부터 검색 허용 (예: 백두산, 두산이).
- Google Meet
- WhatsApp
3. 좋음: 두 음절부터 검색 허용 (예: 백두, 두산, 산이).
- Microsoft Teams
- Webex
4. 지나쳐서 당황스러움: 한 음절부터 검색 허용 (예: 백, 두, 산, 이)
- Slack
@mikaeru@mastodon.social
In the open-source application `Unicopedia Sinica`, both data files used for the `CJK Components` and the `CJK Related` utilities are now in a consistent JSON format with MIT license: `cjk-ids.json` and `cjk-related.json` respectively.

ALT text
CJK Related utility screenshot

ALT text
CJK Components utility screenshot
ALT text
CJK Related utility screenshot
@hongminhee@hollo.social · Reply to 洪 民憙 (Hong Minhee) :nonbinary:
安寧하세요, 저는 서울에 살고 있는 30代 後半 오픈 소스 소프트웨어 엔지니어이며, 自由·오픈 소스 소프트웨어와 聯合宇宙(fediverse)의 熱烈한 支持者입니다.
저는 TypeScript用 ActivityPub 서버 프레임워크인 @fedify 프로젝트와 싱글 유저用 ActivityPub 마이크로블로그인 @hollo 프로젝트와 ActivityPub 봇 프레임워크인 @botkit 프로젝트의 製作者이기도 합니다.
저는 東아시아 言語(이른바 #CJK)와 유니코드에도 關心이 많습니다. 聯合宇宙에서는 國漢文混用體를 쓰고 있어요! 제게 韓國語나 英語, 日本語로 말을 걸어주세요. (아니면, 漢文으로도!)
@hongminhee@hollo.social
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
@FoW@netsphere.one
아시아 언어를 위한 메시징 서비스 음절 검색
CJK는 조사;postposition을 단어 뒤에 바로 붙여쓰므로, 음절 검색 허용 여부에 따라 생산성이 달라진다.
1. 나쁨: 음절 검색 불가. 어절 검색만 허용 (예: 백두산이).
- Discord
- Matrix
- Synology Chat
- Telegram
2. 보통: 세 음절부터 검색 허용 (예: 백두산, 두산이).
- Google Meet
- WhatsApp
3. 좋음: 두 음절부터 검색 허용 (예: 백두, 두산, 산이).
- Microsoft Teams
- Webex
4. 지나쳐서 당황스러움: 한 음절부터 검색 허용 (예: 백, 두, 산, 이)
- Slack
@epocsquadron@fosstodon.org
@hongminhee random question about #cjk languages; i know that traditional chinese characters have been simplified multiple times to improve literacy of the masses. i know of simplified chinese, japanese kanji, and most recently learned of korean hanja. are they all mutually intelligible to readers? are the simplifications obvious to those who stick to traditional characters like taiwanese? it's not something i've seen much written about
@hongminhee@fosstodon.org · Reply to 洪 民憙 (Hong Minhee)
@hongminhee@fosstodon.org · Reply to 洪 民憙 (Hong Minhee)
安寧하세요, 저는 서울에 살고 있는 30代 後半 오픈 소스 소프트웨어 엔지니어이며, 自由·오픈 소스 소프트웨어와 聯合宇宙의 熱烈한 支持者입니다.
저는 TypeScript用 ActivityPub 서버 프레임워크인 @fedify 프로젝트와 싱글 유저用 聯合宇宙 마이크로블로그인 @hollo 프로젝트의 製作者이기도 합니다.
저는 東아시아 언어(이른바 #CJK)와 유니코드에도 關心이 많습니다. Mastodon에서는 國漢文混用體를 쓰고 있어요! 제게 韓國語나 英語, 日本語로 말을 걸어주세요. (아니면, 漢文으로도!)
#툿친소 #연친소 #별친소 #國漢文 #國漢文混用 #國漢文混用體 #국한문 #국한문혼용 #국한문혼용체 #한국어 #일본어 #영어 #한문 #연합우주
@hongminhee@fosstodon.org
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, and @hollo, a fediverse microblog for single users.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文/#漢文)!
@hongminhee@fosstodon.org
Wow, English-only people (or Western languages, for that matter) are so naïve. In case you didn't know, the lang attribute is very important in East Asian languages.
https://lobste.rs/s/9ck6y9/what_programming_language_is_this_code#c_0zuhqs
ALT text
Thread discussion about the utility and implementation of the lang attribute in HTML, including various opinions on its importance and examples of its uses.

ALT text
Table showing the characters 房, 港, 漢, 直, 角, 骨 in Korean, Traditional Chinese, Simplified Chinese, and Japanese scripts.
@hongminhee@fosstodon.org
If you're a software engineer and interested in East Asian languages (so-called #CJK), check out the “CJK computer science terms comparison” I edited!

cjk-compsci-terms.netlify.app
CJK computer science terms comparison
@hongminhee@fosstodon.org · Reply to 洪 民憙 (Hong Minhee) 🤏🏼
드디어 @thisismissem 님 德分에, #Mastodon 最新 開發 버전에는 루비 文字 를 렌더링할 수 있게 되었습니다!
github.com
Implement HTML ruby tags for east-asian languages by ThisIsMissEm · Pull Request #30897 · mastodon/mastodon
I'm working on implementing #26592, so far I've just focused on the "getting the tags kept", I haven't yet tested how these display in the web UI.
@hongminhee@fosstodon.org · Reply to 洪 民憙 (Hong Minhee) 🤏🏼
ついに @thisismissem さんのおかげで、Mastodonの最新開発版でルビー文字をレンダリングできるようになりました!
github.com
Implement HTML ruby tags for east-asian languages by ThisIsMissEm · Pull Request #30897 · mastodon/mastodon
I'm working on implementing #26592, so far I've just focused on the "getting the tags kept", I haven't yet tested how these display in the web UI.
@hongminhee@todon.eu · Reply to 洪 民憙 (Hong Minhee) 🤏🏼
現在Mastodonでは、Misskey等、他のActivityPubソフトウェアから受け取ったコンテンツのHTMLの中で、<strong>や<em>の樣な無害な幾つかのタグに限ってレンダリングしています。私はこれに加えて、所謂「#CJK」と呼ばれる東アジアのテキストでよく使われるルビ文字に關するタグも許可リストに入るべきだと思います。ルビ文字は單に文章の表現を追加するのではなく、實質的に文字の讀み方を示す方法でアクセシビリティにも役立ちます。MastodonのGitHubのイシューにも書いていますので、是非ご覧ください。
#Mastodon #RubyCharacters #ルビ文字
https://github.com/mastodon/mastodon/issues/8474#issuecomment-1647334955
github.com
Allow more HTML in the sanitizer · Issue #8474 · mastodon/mastodon
Currently, as it is, even simple Markdown cannot federate. It would be nice if we could support more kinds of posts, and that includes allowing more formatting. I recommend that at the very least, ...
@hongminhee@todon.eu · Reply to 洪 民憙 (Hong Minhee) 🤏🏼
現在 Mastodon에서는 Misskey 等 다른 ActivityPub 소프트웨어로부터 받은 콘텐츠의 HTML 中에 <strong>이나 <em>과 같은 無害한 몇 가지 태그들에 限해서 렌더링을 해주고 있습니다. 저는 이에 더해 이른바 「#CJK」라 불리는 東아시아 텍스트에서 자주 쓰이는 루비 문자 關聯 태그도 許容 리스트에 들어가야 한다고 생각합니다. 루비 文字는 單純히 글의 表現을 더하는 것이 아니라 實質적으로 文字를 읽기를 나타내는 方法으로 接近性에도 도움이 됩니다. #Mastodon GitHub의 이슈에도 글을 남겼으니 살펴봐 주세요.
https://github.com/mastodon/mastodon/issues/8474#issuecomment-1647334955
github.com
Allow more HTML in the sanitizer · Issue #8474 · mastodon/mastodon
Currently, as it is, even simple Markdown cannot federate. It would be nice if we could support more kinds of posts, and that includes allowing more formatting. I recommend that at the very least, ...
@hongminhee@fosstodon.org · Reply to 洪 民憙 (Hong Minhee) 🤏🏼
Thanks to @thisismissem, the latest development version of #Mastodon now has the ability to render ruby characters! 👏👏👏
github.com
Implement HTML ruby tags for east-asian languages by ThisIsMissEm · Pull Request #30897 · mastodon/mastodon
I'm working on implementing #26592, so far I've just focused on the "getting the tags kept", I haven't yet tested how these display in the web UI.
@hongminhee@todon.eu
Currently, #Mastodon only renders a few harmless tags like <strong> and <em> in the HTML of content received from other ActivityPub softwares like Misskey. In addition to these, I believe that tags related to ruby characters, which are often used in East Asian texts such as so-called #CJK, should also be allowed, as they don't just add to the presentation of the text, but actually represent how the characters are read, which also improves accessibility. I also wrote about this in an issue on Mastodon GitHub:
https://github.com/mastodon/mastodon/issues/8474#issuecomment-1647334955
github.com
Allow more HTML in the sanitizer · Issue #8474 · mastodon/mastodon
Currently, as it is, even simple Markdown cannot federate. It would be nice if we could support more kinds of posts, and that includes allowing more formatting. I recommend that at the very least, ...
@mikaeru@mastodon.social · Reply to Michel Mariani
@mikaeru@mastodon.social
@mikaeru@mastodon.social
Beautifully crafted BabelStone Han font, by Andrew West 魏安
#BabelStone Han v. 15.1.3 is a free #Unicode #CJK #font with over 57,000 Han characters (#hanzi, #kanji, #hanja), and 62,061 Unicode characters in total. It is a Song/Ming style (宋体/明體) font, with glyphs modelled on the official character forms used in the People's Republic of China, and is primarily intended for writing Modern Standard #Chinese, Classical Chinese, and various Sinitic languages and dialects.
ALT text
Repeated: 龙 U+9F99 U+31342 U+2EE5D
@mikaeru@mastodon.social
Unicopedia Plus is a developer-oriented set of Unicode, Unihan, Unikemet & emoji utilities wrapped into one single app, built with #Electron.
Repository: 🔗 https://codeberg.org/tonton-pixel/unicopedia-plus
#characters #chinese #cjk #codepoints #desktopapplication #electronjs #emoji #ivd #japanese #javascript #kangxi #kangxiradicals #korean #normalization #opensource #regex #segmentation #strokecount #unicode #unicopedia #unihan #unikemet
ALT text
Unicopedia Plus Social Preview
@mikaeru@mastodon.social
Unicopedia Sinica is a developer-oriented set of #Unicode utilities related to ideographs, wrapped into one single app, built with #Electron.
Repository: 🔗 https://codeberg.org/tonton-pixel/unicopedia-sinica
#characters #chinese #cjk #cjkrelated #cjkv #codecharts #codepoints #components #confusables #desktopapplication #electronjs #glyphs #ideographs #ideographicdescriptionsequences #ids #japanese #javascript #kangxi #kangxiradicals #korean #localfonts #opensource #strokes #tangut #unicode #unicopedia #unihan #vietnamese
ALT text
Unicopedia Sinica Social Preview